Слайд 1 - labkontrol.ru
реклама

Вычисление метрологических характеристик
прямых и косвенных измерений
Северо-Западный государственный медицинский
университет им. И. И. Мечникова
Кафедра профилактической медицины и охраны
здоровья
Получая результат экспериментальных измерений,
исследователь всегда должен понимать, что этот
результат получен с некоей суммарной
погрешностью Sсум, которая складывается из двух
составляющих – систематической составляющей Δ и
случайной составляющей s погрешности
S сум s 2 2
Инструментальные факторы, обусловливающие
систематическую погрешность (Δ):
• Использование в ФК-анализе немонохроматического
света;
• Неправильная градуировка шкалы длин волн
спектрофотометра;
• Неправильная градуировка шкалы пропускания
(оптической плотности) прибора;
• Фактор неоднородности и дисперсности раствора:
вклад эффекта рассеяния света;
• Загрязнённость элементов оптической системы и
кювет;
• Приборные погрешности, связанные с ценой деления
шкалы, например, весов, пипеток, бюреток, приборов
и т.д.
Аналитические факторы, обусловливающие
систематическую погрешность (Δ):
• Влияние различных примесей, низкой
химической квалификации растворителей
(например, ч., чда и пр.), появление
побочных продуктов приводит к
дополнительному фону оптической
плотности и увеличивают систематический
сдвиг.
Любые систематические составляющие погрешности
измерений приводят к систематическим сдвигам
(смещениям) в результатах, а значит,
к неправильности, ошибочности самих результатов.
Правильный Систематический
сдвиг
результат
Aср +- s
A
A
0
-s
A ср +- s +
+s
-s
+s
A
Неправильный результат
(ошибка)
A'ср= (A ср + A) + s
-
A ( A A0 )
A0 – опорное значение
Систематическая составляющая Δ совокупной
погрешности – это лишь часть суммарной
погрешности Sсум измерений, но такая, что при
увеличении может сделать измеряемый результат
неправильным.
В таком случае уже можно говорить об ошибке
(а не погрешности) измерений.
( A A0 )
A0
Минимизация этой части (вклада систематической
составляющей) является важной задачей не только
исследователя, оператора или лаборанта, но и всей
лаборатории и даже ее руководства.
Чем меньше систематическая составляющая Δ
погрешности – смещение измерений, тем более
суммарная погрешность (неопределённость)
определяется случайной составляющей
при
0
S сум s
В этом случае суммарная погрешность (неопределённость) определяется
преимущественно случайными факторами, которые уже не зависят от
нашей воли, от воли и желания оператора или исследователя.
Поэтому чем меньше систематическая составляющая
погрешности, меньше смещение, тем правильнее
результаты анализа.
Или: результаты анализа правильны, потому что они не искажены
систематической составляющей погрешности.
Привычные термины и понятия теории
малых выборок
• От опыта к опыту при бесконечном числе повторных
измерений: результаты измерений величины x будут
отличаться, рассеиваясь – диспергироваться
(ДИСПЕРСИЯ) вокруг некоего центра – ожидаемого
результата (МАТЕМАТИЧЕСКОЕ ОЖИДАНИЕ µ)
• Математическое ожидание – ИСТИННЫЙ РЕЗУЛЬТАТ –
гипотетический и не достижимый! – так же, как не
достижимо бесконечное число измерений
• (ГЕНЕРАЛЬНАЯ СОВОКУПНОСТЬ непрерывна и
соответствует непрерывному распределению случайных
величин - НОРМАЛЬНОМУ РАСПРЕДЕЛЕНИЮ ГАУССА)
• Разброс – Дисперсия ГЕНЕРАЛЬНАЯ
Продолжение
• В экспериментальной работе: ограничиваемся лишь
СЛУЧАЙНОЙ МАЛОЙ ВЫБОРКОЙ из всей генеральной
совокупности.
• От опыта к опыту при конечном и дискретном числе повторных
измерений:
результаты измерений величины A тоже будут отличаться,
рассеиваясь – диспергироваться (ДИСПЕРСИЯ) вокруг центра
малой выборки – экспериментального результата (СРЕДНЕЕ
АРИФМЕТИЧЕСКОЕ ЗНАЧЕНИЕ)
• Среднее арифметическое значение – ЭКСПЕРИМЕНТАЛЬНЫЙ
РЕЗУЛЬТАТ – достижимый! – отличается от математического
ожидания. ТЕОРИЯ ОЦЕНИВАЕТ ЭТО ОТЛИЧИЕ
• СОВОКУПНОСТЬ значений МАЛОЙ ВЫБОРКИ дискретна и
соответствует дискретному распределению случайных величин –
ГИСТОГРАММЕ ГАУССА, отклоняющегося от нормального
распределения случайных величин
• Разброс – Дисперсия малой выборки - ПРЕЦИЗИОННОСТЬ
• A1, A2 A3 … Ai … An
i = 1…n
• i - номер опыта; n – число или совокупность всех
опытов;
• при n → ∞ - генеральная совокупность: дискретный ряд
случайных величин переходит в непрерывное
распределение случайной величины;
• A1, A2 A3 … Ai … An группируются с неким
разбросом вокруг центра распределения;
• Наибольшая плотность значений Ai – вблизи центра
характеризует большую вероятность Pi попадания
значений Ai ближе к центру
Распределение данных в малой выборке
Гистограмма дискретных данных в малой выборке
Заметьте! Результаты тоже сконцентрированы в
центральной части гистограммы
При большем объёме выборки гистограмма
представляет намного более чёткую картину
распределения данных
Распределение приблизительно симметрично
Заметьте! Результаты опять же сконцентрированы в
центральной части гистограммы
Для бесконечного массива данных гистограмма переходит в
непрерывную плавную кривую Гаусса нормального
распределения непрерывных случайных величин
Распределение симметрично
Большая часть результатов группируется вблизи
центра распределения µ, а с удалением от центра –
количество результатов убывает.
Кривая Гаусса
( A, , )
1
2
e
( A ) 2
2 2
0,5
P(A i )
0,4
P = 68%
0,3
0,2
P = 95%
0,1
P = 99%
0,0
0
+ +215 +3
Случайные величины Ai
5
Aср
10
20
Максимум кривой для дискретных n измерений –
среднее арифметическое значение Aср
i n
Aср
1
1
( A1 A2 A3 ... An ) Ai
n
n i 1
при n → ∞ Aср → μ – математическому ожиданию для непрерывной
случайной величины
Кривая Гаусса
( A, , )
1
2
e
( A ) 2
2 2
0,5
P(A i )
0,4
P = 68%
0,3
0,2
P = 95%
0,1
P = 99%
0,0
0
+ +215 +3
Случайные величины Ai
5
Aср
10
20
Отклонения значений Ai от центра распределения кривой (μ) симметричны –
ниже и выше по значениям
Степень этого рассеивания случайных величин вокруг значения μ при n → ∞:
in
1
2
( Ai ) 2
генеральная дисперсия (σ2)
n 1 i 1
Результаты измерения Ai должны находиться в таком интервале,
в котором с определенной долей вероятности P располагается
искомая средняя величина Aср, отождествляемая с
математическим ожиданием (Aср ~ μ)
Кривая Гаусса
В границах доверительного
интервала:
0,5
±σ
P(A i )
0,4
P{(Ai – μ) < σ} = 0.683 (~68 %)
P = 68%
0,3
±2σ
P{(Ai – μ) < 2σ} = 0.954 (~95 %)
0,2
P = 95%
±3σ
0,1
P{(Ai – μ) < 3σ} = 0.9973 (~99 %)
P = 99%
0,0
0
+ +215 +3
Случайные величины Ai
5
Aср
10
20
Доверительная вероятность P
Параметр µ называется математическим ожиданием
(или средним) генеральной совокупности;
Параметр σ – стандартным отклонением генеральной
совокупности.
Площади под кривой Гаусса, соответствующие ± σ (68.3%) и ± 2·σ (95.4%)
Кроме того 99.7% значений попадают в интервал ± 3·σ (99.7%) –
почти все значения!
Непопадание результатов измерения соответствует уровню значимости
p = 1 – P < 0.05 для P = 95.4% и p = 1 – P < 0.003 для P = 99.7% .
Алгоритм расчёта статистических параметров: результаты среднего значения
величины Aср даются в границах доверительного интервала ±2σ с доверительной
вероятностью 95%. Считается, что в этих доверительных границах среднее значение
измеряемой величины воспроизводится с вероятностью P = 0.95 (попадает в интервал).
А несходимость и невоспроизводимость результата измерения соответствует
уровню значимости p = 1 – P < 0.05.
Для генеральной совокупности (n →∞)
Для малой выборки (n ≥ 3)
Среднее арифметическое значение
1
1 i n
Aср ( A1 A2 A3 ... An ) Ai
n
n i 1
Дисперсия
2
in
1
1 i 3
Aср ( A1 A2 A3 ) Ai
3
3 i 1
1 i 3
s
( Ai Aср ) 2
3 1 i 1
2
1
( Ai ) 2
n 1 i 1
Среднее квадратичное отклонение СКО (стандартное отклонение)
i 3
i n
1
( Ai ) 2
n 1 i 1
s
(A
i
i 1
Aср ) 2
3 1
Стандартное отклонение среднего арифметического выборки
i 3
i n
n
( A )
i 1
i
n (n 1)
2
0
s Aср s
3
(A A
i 1
i
ср
3 (3 1)
)2
Критерий точности прямых измерений
и достоверность результатов анализа
Смещения (Aср – μ) самого среднего арифметического результата Aср
т.е. действительные погрешности измерений,
полученные при измерениях в той ли иной выборке,
определяются с помощью коэффициентов Стьюдента
и характеризуют воспроизводимость самих результатов измерений
величины A
Aср Aср t s Aср t
s
n
Критерий Стьюдента связывает смещение (Aср – μ) величины Aср,
полученной в малой выборке, от величины μ
генеральной
совокупности
s
с погрешностью этого смещения,
n
т.е. со значением среднеквадратичного стандартного отклонения
среднего арифметического Aср выборки
tP, f
Aср
s
n
Коэффициент Стьюдента в формуле показывает, во сколько раз
разность между истинным μ (математическим ожиданием) и
средним результатом Aср малой выборки больше стандартного
отклонения среднего результата (погрешности смещения Aср)
Таблица 1. Значения коэффициентов t-распределения Стьюдента
в зависимости от доверительной вероятности P и степени свободы f
Доверительная вероятность P
f=n-1
0.683
0.90
0.955
0.997
1
1.963
6.31
12.7
63.7
2
1.386
2.92
4.30
9.92
3
1.250
2.35
3.18
5.84
4
1.190
2.13
2.78
4.60
5
1.156
2.01
2.57
4.03
6
1.134
1.94
2.45
3.71
7
1.119
1.89
2.36
3.50
8
1.108
1.86
2.31
3.36
9
1.10
1.84
2.26
3.25
14
1.076
1.76
2.14
2.98
19
1.066
1.73
2.09
2.86
20
1.064
1.725
2.09
2.85
29
1.055
1.699
2.045
2.76
30
1.055
1.70
2.04
2.75
∞
1.036
1.64
1.96
2.58
Если принять, что величина погрешности СКО
будет меньше действительной погрешности
s Aср
выборки
Aср Aср в ≈ 2.58 раза, то есть
Aср
tP, f
s Aср
2.58
Доверительная вероятность P
f=n-1
0.683
0.90
0.955
0.997
Значения коэффициента Стьюдента
∞
1.036
1.64
1.96
2.58
то вероятность того, что результат Aср проведенной выборки будет адекватным,
то есть совпадёт с истинным значением μ для генеральной совокупности в пределах
±
Aср , будет равна 99.7% (P = 0.997).
и всего 0.1% значений Aср могут оказаться вне вычисленных доверительных предел
Aср Aср
(доверительного интервала).
Если величина погрешности СКО
действительной погрешности
s Aср
выборки будет меньше
Aср Aср в ≈ 2 раза, то есть
tP, f
Aср
s Aср
1.96
Доверительная вероятность P
f=n-1
0.683
0.90
0.955
0.997
Значения коэффициента Стьюдента
∞
1.036
1.64
1.96
2.58
то вероятность того, что результат Aср проведенной выборки будет адекватным,
то есть совпадёт с истинным значением μ для генеральной совокупности в предела
±
Aср , будет равна 95.5% (P = 0.955).
а 4.5% значений Aср могут оказаться вне вычисленных доверительных пределов
Aср Aср
(доверительного интервала).
Если величина погрешности СКО
действительной погрешности
s Aср
выборки будет примерно равна
Aср Aср
то есть ≈ 1 раз
tP, f
Aср
s Aср
1.036
Доверительная вероятность P
f=n-1
0.90
0.683
0.955
0.997
Значения коэффициента Стьюдента
∞
1.036
1.64
1.96
2.58
то вероятность того, что результат Aср проведенной выборки будет адекватным,
то есть совпадёт с истинным значением μ для генеральной совокупности в преде
±
Aср , будет равна 68.3% (P = 0.683).
а 31.7% значений Aср могут оказаться вне вычисленных доверительных пределов
Aср Aср
(доверительного интервала).
Чем больше выбираемая доверительная вероятность P, тем
больше значение квантиля, поскольку увеличивается доверительный
интервал, охватывающий большие области гауссовой кривой.
Чем меньше число параллельных измерений n (число степеней
свободы f = n-1), тем непропорционально больше значение квантиля,
и тем больше отклонение
Aср
s
n
t P, f
Aср от истинного математического ожидания μ гауссовой кривой.
Доверительные границы этого результата раздвигаются и
погрешность определения Aср возрастает.
Aср – ΔAср < μ < Aср + ΔAср
И, наоборот, чем больше параллельных измерений n, тем меньше
значение квантиля tP,f и тем меньше отклонение Aср от истинного
математического ожидания μ гауссовой кривой – тем
меньше погрешность определения Aср.
Оценка абсолютного значения случайной погрешности
прямых измерений величины Aср
Абсолютное значение случайной погрешности вычисляем как
доверительный интервал ΔAср среднего значения
Aср
s
n
t P, f
предварительно рассчитав среднеквадратичное отклонение СКО
(среднеквадратичное отклонение) s для проведенного малого числа
параллельных измерений (n ≥ 3)
Оценка доверительного интервала ΔAср результатов
измерений малой выборки есть, по сути, вычисление
случайной погрешности (неопределённости)
Aср ± ΔAср.
s
Aср
t P, f
n
Относительное значение случайной погрешности
(неопределённости) вычисляем как отношение
доверительного интервала ΔAср
к самой величине среднего значения Aср измеряемой
величины:
s
Aср
Относительное значение систематической
Погрешности (неопределённости) Δ
Aср
100%
100%
Aср
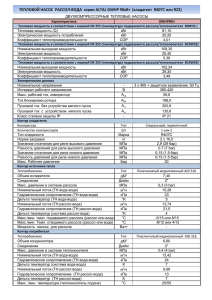
Пример 2. Пусть в прямых многократно (n = 30) повторяющихся измерениях
величины аналитического сигнала A получены следующие
экспериментальные значения Ai, приведенные в виде совокупности
в таблице 2. Определим ряд основных статистических параметров
этой совокупности значений и случайную погрешность (неопределённость)
измерений.
Таблица 2.
I
II
20
0,56
n
Совокупность
значений Ai
21
0,54
22
0,53
1
0,56
23
0,57
2
0,53
24
0,53
3
0,57
25
0,55
4
0,56
26
0,57
5
0,55
27
0,53
6
0,53
28
0,54
7
0,54
29
0,54
8
0,52
30
0,56
9
0,57
10
0,58
11
0,56
Aср
0,54967
12
0,54
0,000300
13
0,53
Дисперсия
s2
14
0,53
СКО s
0,01732
15
0,57
s Aср
0,00316
16
0,56
ΔAср
0,00647
17
0,58
18
0,54
19
0,55
Значения статистических
параметров
1) Среднее арифметическое значение для совокупности значений:
1
1 i 30
Aср
( A1 A2 A3 ... A30 )
Ai 0.54967
30
30 i 1
2) Дисперсия (разброс):
1 i30
s ( Ai Aср ) 2 0.00030
29 i1
2
i 30
3) Среднеквадратичное отклонение (СКО):
s
(A A
i 1
i
29
ср
)2
0.0003 0.01732
4) Стандартное отклонение среднего арифметического всей совокупности измерений
(СКО Aср):
s Aср s
n
0.01732
0.00316
30
5) Для определения значения действительной погрешности (неопределённости) результата
прямого измерения величины A воспользуемся формулой для расчёта доверительного
интервала ΔAср. Пусть доверительная вероятность P = 95%.
Тогда коэффициент Стьюдентадля P = 0.95 и f = n - 1 = 29, равен 2.045.
Aср
s
t P , f s Aср t P0.95, f 29 0.00316 2.045 0.00647
n
Вычисленный результат:
Aср ± ΔAср ≈ 0,5497 ± 0,0065 ≈ 0,550 ± 0,007.
II. Алгоритм (схема) проведения статистической обработки результатов
прямых равноточных измерений малой выборки
1.Оценка повторяемости (сходимости) и воспроизводимости результатов.
а) Вычисление среднего арифметического значения Aср
1
1 i n
Aср ( A1 A2 A3 ... An ) Ai
n
n i 1
i Ai Aсррезультатов от среднего значения,
n
алгебраическая сумма которых стремится к нулю
i 0
Оценка единичных отклонений
i 1
б) Находим рассеяние результатов измерений относительно среднего значения, т.е.
дисперсию s2 и среднее квадратическое отклонение СКО
in
s
(A
i 1
i
Aср ) 2
n 1
Значением СКО характеризуют повторяемость и воспроизводимость результатов
измерений аналитического сигнала (анализа) данной методикой.
Относительное стандартное отклонение sr вычисляется sr = s / Aср.
Анализ можно считать оптимальным в той области
содержаний, где стандартные отклонения имеют
минимальные значения:
Aср ± s → min
Исключение выбросов по Q-критерию Диксона
(при выборках с n < 10)
Составляется соотношение
Q x1 x2 R
x1 – подозрительно выделяющийся результат определения;
x2 – результат единичного определения, ближайший по значению к x1
R – размах варьирования R xmax xmin
Вычисленное значение
Q
x1 x2
xmax xmin
сравниваем с табличным значением Q(P, ni)
Таблица. Численные значения для Q (P*, ni); P*= 0.5 + P/2 – односторонняя задача
P* = 0.90
P* = 0.95
P* = 0.99
3
0.89
0.94
0.99
4
0.68
0.77
0.89
5
0.56
0.64
0.76
6
0.48
0.56
0.70
7
0.43
0.51
0.64
8
0.40
0.48
0.58
ni
Если Q > Q(P, ni), то наличие выброса определено и доказано, и этот
результат x может быть отброшен и не рассматриваться для расчёта СКО
Пример. Выборка 1:
0.61 0.62 0.59 0.60 0.75 0.58 0.62
A1 – подозрительно выделяющийся результат определения = 0.75
A2 – результат единичного определения, ближайший по значению к A1 = 0.62
A1 A2 0.75 0.62 0.13 R Amax Amin 0.75 0.58 0.17
Q
A1 A2
0.75 0.62
Amax Amin
0.13
0.764
0.75 0.58 0.17
Вычисленное значение 0.764
сравниваем с табличным значением Q(P=0.95, ni=7)
P* = 0.90
P* = 0.95
P* = 0.99
ni
3
0.89
0.94
0.99
4
0.68
0.77
0.89
5
0.56
0.64
0.76
6
0.48
0.56
0.70
7
0.43
0.51
0.64
8
0.40
0.48
0.58
Значение Q=0.764 > Q(0.95 и даже 0.99, 7) = 0.51, 0.64 наличие
промаха (выброса) определено и доказано, и результат A1 = 0.75 может
быть отброшен и не рассматриваться для определения СКО
Пример. Выборка 2:
0.61 0.62 0.68 0.60 0.75 0.58 0.62
A1 – подозрительно выделяющийся результат определения = 0.75
A2 – результат единичного определения, ближайший по значению к A1 = 0.62
A1 A2 0.75 0.68 0.07 R Amax Amin 0.75 0.58 0.17
Q
A1 A2
0.75 0.68
Amax Amin
0.07
0.411
0.75 0.58 0.17
Вычисленное значение 0.411
сравниваем с табличным значением Q(P=0.95, ni=7)
P* = 0.90
P* = 0.95
P* = 0.99
ni
3
0.89
0.94
0.99
4
0.68
0.77
0.89
5
0.56
0.64
0.76
6
0.48
0.56
0.70
7
0.43
0.51
0.64
8
0.40
0.48
0.58
Значение Q=0.411 < Q(0.95, 7) = 0.51 наличие промаха (выброса)
не доказано, и результат A1 = 0.75 не может быть отброшен и остаётся
в выборке для определения СКО
Метод 2. Критерий Граббса: Исключение выбросов методом вычисления
максимального относительного отклонения.
использует распределение наибольшего по абсолютному значению нормированного отклонения
макс Ai Aср
tт
s
tт – теоретическое значение квантилей распределения, приводимые в таблице 3 для уровней
значимости p = 1 – P = 0.10; 0.05; 0.01 (или P = 0.90; 0.95; 0.99 соответственно) и n < 25.
Таблица 3. Значения квантиля tт - распределенияt т
макс Ai Aср
s
(выборочные значения)
Доверительная вероятность P
n
0.90
(p = 0.1)
0.95
(p = 0.05)
0.99
(p = 0.01)
3
1.41
1.41
1.41
4
1.65
1.69
1.72
5
1.79
1.87
1.96
6
1.89
2.00
2.13
7
1.97
2.09
2.27
10
2.15
2.29
2.54
15
2.33
2.49
2.80
20
2.45
2.62
2.96
25
2.54
2.72
3.07
Для того чтобы в группе из n наблюдений A1 A2 A3 … Ai … An отбросить
результат Amax или Amin, необходимо:
Amax Aср
t
max
а) вычислить значение экспериментального квантиля
s
б) по таблице 3 найти теоретическое значение tт в зависимости от числа измерений
n и выбранного уровня значимости p, обычно принимаемого 0.05
(доверительной вероятности P, обычно = 0.95);
в) сравнить рассчитанное значение tmax с табличным значением квантиля tт .
Если tmax > tт , то результат Amax следует отбросить как промах.
Задача обнаружения и выбраковки грубых отклонений (промахов) является
более общей задачей – задачей проверки однородности выборок и,
как следствие - повторяемости опытов во внутрилабораторных условиях ВЛК
или воспроизводимости опытов в случае межлабораторных измерений МЛК.
Если имеется несколько серий параллельных опытов, полученные выборки
необходимо проверить на однородность, т.е. выяснить, насколько полученные
результаты каждой выборки соответствуют нормальному распределению.
max s 2j
Решение производят с помощью критерия Кохрена GP n 2
sj
j 1
Номер серии
опытов
Результаты
k параллельных опытов
Āj
s j2
1
A11
A12
…
A1k
Ā1
s1 2
2
A21
A22
…
A2k
Ā2
s2 2
…
…
…
…
…
…
…
N
AN1
AN2
…
ANk
ĀN
sN2
Средние значения Āj и выборочные дисперсии sj2 рассчитываются
по известным формулам
k
k
Aj
1
Ai
k i 1
s 2j
1
( Ai Aср ) 2
k 1 i 1
По найденным значениям рассчитывается критерий Кохрена: в числителе
- максимальная из найденных оценок дисперсий, а в знаменателе – их сумма
max s 2j
GP n
сравниваем с табличным
2
s j значением G
Значения G Кохрена
j 1
N
f=k-1
1
2
3
4
5
6
…
2
0.9999
0.9950
0.9794
0.9586
0.9373
0.9172
…
3
0.9933
0.9423
0.8831
0.8335
0.7933
0.7606
…
…
Если значения GP ≤ G, то опыты в сравниваемых выборках
считаются повторяющимися и воспроизводимыми,
а дисперсии – однородными. Выбросов нет.
Такие выборки можно объединить в одну для общей
статистической обработки.
Если GP > G, то выборка с максимальной дисперсией max s 2j
неоднородна из-за присутствия выбросов в ней.
И дисперсию этой выборки необходимо исключить из дальнейшей
обработки. Процедуру повторяют до следующего по значению max s 2j
и т.д. до тех пор, пока GP не станет меньше или равно G: GP ≤ G
Не исключённые из расчётов дисперсии выборок считаются
однородными, и по ним оцениваются средние квадратичные
n
отклонения
, характеризующие повторяемость
2
(
A
A
)
i
ср
результатов единичного анализа
i 1
s
n 1
(n параллельных определений)
Оценки однородных дисперсий можно усреднить и получить
оценку дисперсии повторяемости (воспроизводимости):
2
воспр
s
1 n 2
sj
n j 1
Таким образом, по критерию Кохрена делается вывод о
повторяемости (воспроизводимости) эксперимента, а величина s2воспр
характеризует неопределённость эксперимента в целом.
г) Вычисление дисперсии s2Aср и СКО sAср среднего арифметического
i n
s Aср s
n
(A
i 1
i
Aср ) 2
n (n 1)
д) Определение доверительного интервала с помощью таблицы квантилей
Стьюдента и абсолютного значения случайной погрешности ±ΔAср
Aср
s
t P , f s Aср t P , f
n
а также интервальных значений Aср ± ΔAср, что по сути является абсолютной
погрешностью результата измерения (оптической плотности).
Для интервальных значений измеряемой величины (доверительных границ) в общем случае
можно записать выражения
Aср – ΔAср < μ < Aср + ΔAср
Aср t P, f s Aср Aср t P, f s Aср
Aср t P , f
s
n
Aср t P , f
s
n
Пример расчета метрологических характеристик прямых измерений
с помощью ПП Origin 2_8
I: Aср = 0,45
0,45
0,51
0,43
0,44
0,47
0,46
0,45
0,44
C:
0,48
0,47
0,47
0,43
0,45
0,46
0,48
0,44
0,43
0,45
0,5
0,47
A: Aср = 0,459
0,45
0,51
0,43
0,44
0,47
0,46
0,45
СКО = 0,02646
0,45
0,48
0,51
0,44
0,43
0,43
0,44
0,47
E: Aср = 0,46 СКО = 0,03162
Aср = 0,45857 СКО = 0,0261
СКО = 0,02245 SUM =9,18
SUM = 3,21
N=20
SUM = 1,35 N = 3
SUM = 2,3 N = 5
N=7
Продолжение примера расчета доверительных интервалов и
абсолютной погрешности для прямых измерений
Aср
s
t P , f s Aср t P , f
n
Aср - ΔAср < Aср < Aср + ΔAср
n
f
Aср
СКО
sAср
tP, f,
при P = 0.95
ΔAср
Aср ± ΔAср
Aср - ΔAср < Aср < Aср + ΔAср
3
2
0.450
0.0265
4.30
0.066
0.450 ± 0.066
0.384 < 0.450 < 0.516
5
4
0.460
0.0316
2.78
0.039
0.460 ± 0.039
0.421 < 0.460 < 0.499
7
6
0.459
0.0261
2.45
0.024
0.459 ± 0.024
0.435 < 0.459 < 0.483
20
19
0.459
0.0225
2.09
0.011
0.459 ± 0.011
0.448 < 0.459 < 0.470
Повторяемость (сходимость) и воспроизводимость анализа
определяется разбросом повторных результатов анализа
относительно их среднего значения и обусловливаются
наличием случайных погрешностей
Повторяемость (сходимость) анализа характеризует
рассеяние результатов при фиксированных условиях выполнения
эксперимента.
Воспроизводимость анализа (внутри- и
межлабораторная) характеризует рассеяние результатов при
варьировании (изменении) этих условий
(ГОСТ 162263 – 70. Метрология. Термины и определения).
Воспроизводимость результатов анализа, полученного в прямых
измерениях разными методиками
Целью сравнения двух средних арифметических величин Aср1 и Aср2,
полученных разными методиками или в разных по объёму
экспериментальных выборках, является оценка существенности различий,
достоверности или недостоверности различий между ними.
Критерий точности
t
Aср1 Aср 2
s A2ср1 s A2ср 2
Величина t показывает во сколько раз разность средних значений
(Aср1 - Aср2) превышает их суммарную погрешность.
Если разность средних значений (Aср1 - Aср2) меньше их суммарной
погрешности, t < 1, то можно говорить
об отсутствии различия между Aср1 и Aср2, их достоверном совпадении
и воспроизводимости результата, полученного разными методиками.
Доверительная вероятность P
f=n-1
0.683
0.90
0.955
0.997
Значения коэффициента Стьюдента
∞
1.036
1.64
1.96
2.58
При t ≥ 2 разность средних арифметических может считаться вполне
достоверной, поскольку
если значения доверительного коэффициента
,
t
Aср1 Aср 2
s
2
Aср1
s
2
Aср 2
≥2
превышают значение 2, то вероятность того, что различия между
величинами установлены и достоверны, не меньше 95.5 %
Доверительная вероятность P
f=n-1
0.683
0.90
0.955
0.997
Значения коэффициента Стьюдента
∞
1.036
1.64
1.96
2.58
При t < 2 достоверность разности двух средних величин не доказана,
и в случае уменьшения доверительного коэффициента до 1 и ниже
(доверительная вероятность различия ≈ 68.3 % и меньше - см. таблицу 1)
можно вести речь о большем совпадении средних результатов измерений
Aср1 и Aср2, полученных в разных выборках,
их повторяемости и воспроизводимости.
t
Aср1 Aср 2
s A2ср1 s A2ср 2
Действительно, при t ≈ 1 выражение переходит в уравнение:
s A2 ср1 s A2 ср 2 Aср1 Aср 2
Значит, при t ≤ 1
результаты Aср1 и Aср2 прямых измерений в разных выборках достоверно совпадают,
так как между ними нет достоверного различия.
Результат воспроизводится, поскольку разность между ними не превышает сумму
погрешностей смещения средних арифметических значений, вычисляемых как СКО
Таким образом, воспроизводимость результата анализа,
полученного разными методиками, характеризуют с помощью
вычислений СКО средних арифметических значений и
оценки доверительного коэффициента t как критерия точности
результатов.
Воспроизводимость результатов анализа, полученного в прямых
измерениях разными методиками
Для решения этой задачи необходимо провести статистическую обработку
каждого из массивов данных (выборок) согласно рассмотренному алгоритму
Выборка
прямых
измерений Ai2
2-й методикой
Выборка
прямых
измерений Ai1
1-й методикой
0,55
0,52
0,58
0,56
0,57
0,54
0,58
0,55
Критерий точности
0,56
0,57
0,55
Aср1 = 0,566
s Aср1 = 0,0057
t
Aср1 Aср 2
s A2ср1 s A2ср 2
0,54
0,52
0,53
0,51
0,56
Aср2 = 0,537
s Aср 2 = 0,0060
Пример 3. Предположим, что прямые измерения оптической плотности раствора
вещества проводились двумя разными методиками, на двух разных приборах и
разными операторами от начала и до конца. Были получены два массива
экспериментальных значений Ai (две выборки) разного объёма (один – n = 7,
второй – n = 9), которые уже включают все возможные погрешности
(неопределённости), возникшие в ходе отбора, подготовки проб и измерений
(см. таблицу).
Необходимо проверить достоверность полученного в ходе прямых
параллельных измерений результата Aср – насколько можно судить
об отсутствии различий (достоверной воспроизводимости) значений
Aср, полученных двумя разными методиками.
Для решения этой задачи необходимо провести статистическую
обработку каждого из массивов данных (выборок) согласно алгоритму
I
Таблица
n
Выборка
прямых
измерений Ai1
1-й методикой
II
Выборка
прямых
измерений
Ai2 2-й
методикой
Выборка
прямых
измерений
Ai1
1-й
методикой
Выборка
прямых
измерений
Ai2 2-й
методикой
1
0,57
0,56
0,58
0,55
2
0,56
0,53
0,57
0,52
3
0,58
0,57
0,58
0,56
4
0,54
0,56
0,55
0,54
5
0,55
0,55
0,56
0,54
6
0,56
0,53
0,57
0,52
7
0,54
0,54
0,55
0,53
8
0,52
0,51
9
0,57
0,56
Значения статистических параметров
Aср
0,55714
0,54778
0,56571
0,53667
Дисперсия s2
0.000224
0.000345
0.000224
0.000345
СКО s
0,01496
0,01856
0,01272
0,01803
0,00565
0,00619
0,00481
0,00601
s Aср
Доверительный
коэффициент t
≈ 1.12 ( ≈ 0.683)
≈ 3.77 ( > 0.997)
Рассчитаем величину t – доверительного коэффициента для разности средних значений
в обоих вариантах:
Вариант I:
t
Aср1 Aср 2
s A2ср1 s A2ср 2
0.55714 0.54778
(0.00565) 2 (0.00619) 2
0.00936
1.12
0.00838
Полученная из таблиц Стьюдента доверительная вероятность того,
что средние значения различаются ≈ 0.683 – достоверное различие
результата анализа отсутствует, можно говорить
о некоторой воспроизводимости результатов анализа
Вариант II:
t
Aср1 Aср 2
s A2ср1 s A2ср 2
0.56571 0.53667
(0.00481) 2 (0.00601) 2
0.02904
3.77
0.007698
Полученная из таблиц Стьюдента доверительная вероятность того,
что средние значения различаются > 0.997 – имеет место достоверное
несовпадение результата анализа, невоспроизводимость
Повторяемость (сходимость) самих результатов прямых повторных
измерений величины A (сравнение Aср двух различных выборок)
Если необходимо оценить повторяемость самих результатов измерений
(прямо измеренные средние значения аналитического сигнала A или косвенно
измеренные средние значения концентрации C), полученных одной и той же методикой,
но в повторно проведенных экспериментах (экспериментальных выборках), то
достоверность разности между двумя средними величинами определяется по формуле:
t
Aср1 Aср 2
Aср2 1 Aср2 2
Aср1 Aср 2 – значения действительных погрешностей (доверительных интервалов),
рассчитанные для каждой из сравниваемых выборок с учётом числа измерений
в каждой из выборок и коэффициентов Стьюдента tP,f при назначенной
доверительной вероятности, например, 95.5%, по формуле:
Aср
s
t P , f s Aср t P , f
n
Применение статистической обработки результатов косвенных
определений концентрации Ci, рассчитанных с помощью массива
прямых измерений Ai величины A.
Косвенным называется измерение той величины, которая для своей
оценки требует проведения прямых измерений некоторых величин,
от которых зависит сама.
Пример косвенного определения величины:
фотометрическое определение концентраций растворов
Aст b Cст
b l
– угловой коэффициент линейного градуировочного
графика светопоглощения
Расчёт значений косвенной величины концентрации:
Ax
Cx
b
по обращённой зависимости закона Бера
В описании к методике параметр b , как правило, приведен
В результате вычислений по уравнению из массива Ai прямых измерений
величины A получаем массив Ci рассчитанных значений косвенной
величины CX:
(параметр b = (62290 ±1500) моль-1·л)
I
II
III
IV
1-я малая
выборка
значений
2-я малая
выборка
значений
Ai1
Ai2
Рассчитанный
массив
значений Ci1
косвенной
величины
концентрации,
мкмоль/л
Рассчитанный
массив
значений Ci2
косвенной
величины
концентрации,
мкмоль/л
1
0,37
0,33
5,94
5,30
2
0,36
0,35
5,78
5,62
3
0,38
0,37
6,10
5,94
4
0,34
0,33
5,46
5,30
5
0,35
0,34
5,62
5,46
6
0,36
0,34
5,78
5,46
7
0,34
0,36
5,46
5,78
8
0,36
0,36
5,78
5,78
9
0,34
0,33
5,46
5,30
10
0,33
0,37
5,30
5,94
n
Определим все основные статистические параметры для величины
концентрации.
Статистический анализ обоих массивов значений Ci косвенно
определяемой величины концентрации проводится аналогично тому,
как это сделано ранее для прямо измеряемой величины A:
s
Вычисляем численные значения Cср, дисперсии, СКО s и СКО C ср среднего
арифметического значения Cср обоих массивов с учётом их объёма (n = 10):
Параметры
Значения статистических
параметров для прямо измеренных
значений величины A
Значения статистических
параметров для косвенной
величины концентрации C
Aср или Cср
0,353
0,348
5,667
5,587
Дисперсия s2
0.000246
0.000262
0.0633
0.0676
СКО s
0,0157
0,0162
0,2516
0,2600
0,0050
0,0051
0,0796
0,0822
s Aср
или
sC ср
Полученные расчётные значения основных метрологических параметров
Cср, СКО, СКО Cср для экспериментальных значений косвенно
определяемой величины концентрации проведены с учётом всех
погрешностей измерений, но без учёта собственной погрешности
или СКО коэффициента пересчёта – параметра b уравнения
градуировочного графика, указанной в описании к конкретной методике.
Ax
Cx
b
Для учёта всех СКО и погрешностей каждой из этих величин
существует формула распределения погрешностей, позволяющая
вычислить СКО или погрешность косвенно определяемой величины
Cср на основании численных значений СКО или погрешностей каждой
из прямо измеряемых величин Aср, a, b.
III. Алгоритм (схема) проведения статистической обработки результатов
косвенных измерений
1) Среднее значение косвенно определяемой величины Cср
вычисляем подстановкой заранее вычисленных средних арифметических
значений Aср, aср , bср, полученных в прямых измерениях в формулу
Cср = f( Aср, aср , bср ).
2) Определяем дисперсию косвенно определяемой величины по формуле
f
f
f
sC2 s A2 sa2 sb2
A
a
b
2
,
Здесь
f
A
f
a
f
b
2
2
- частные производные функции f по C, a и b – прямо измеренным
величинам соответственно;
sA2 , sa2 , sb2 - дисперсии прямо измеренных величин C, a и b соответственно.
Выражение для погрешности СКО косвенного измерения величины С
(закон распределения погрешностей)
f
f
f
sC s A2 sa2 sb2
A
a
b
2
2
2
Формула накопления погрешностей для уравнения
Cx
Ax
b
примет упрощённый вид:
f
f
2
s C s A s b2
A
b
2
2
f
A
1
A A b ср bср
Aср
f
A
b b b ср
bср2
Формула для вычислений погрешности косвенно определяемой величины
с учётом погрешности определения параметра b,
sC
1
sC
bср
s A2
Aср2
bср2
sb2
Сравнение статистических параметров косвенных определений концентрации Ci,
рассчитанных без учёта и с учётом погрешности углового коэффициента b
градуировочного графика
n = 10
I
II
Массив значений Ci1
концентрации,
мкмоль/л
Массив значений Ci2
концентрации,
мкмоль/л
Значения статистических параметров величины C,
мкмоль/л
Cср
5,6670
5,5868
Дисперсия s2
0.0633
0.0676
СКО s
0,2516
0,2600
sC ср
0,0796
0,0822
Значения статистических параметров для величины C
с учётом погрешности углового коэффициента b
Cср
5,6670
5,5868
Дисперсия s2
0.0819
0.0852
СКО s
0,2862
0,2919
sC ср
0,0905
0,0923
3) доверительный интервал косвенно измеренной величины ΔСср вычисляем
из уже известного нам выражения
sC
Cср
tP, f
n
где sС – вычисленное значение дисперсии; tP,f – значения квантилей Стьюдента
находим из таблицы 2
для выбранной доверительной вероятности P и числа n повторений
прямых измерений каждой из величин (f = n – 1).
Интервальные значения косвенно определяемой величины M определяем как:
Сср – ΔСср < M
< Сср + ΔСср
Воспроизводимость результатов косвенно определяемой величины
концентрации, полученных разными методиками
Для решения этой задачи необходимо провести статистическую обработку
каждого из полученных массивов значений косвенной величины
концентрации согласно рассмотренному алгоритму
Рассчитанный массив
значений Ci2 косвенной
величины концентрации,
мкмоль/л
Рассчитанный массив
значений Ci1 косвенной
величины концентрации,
мкмоль/л
5,30
5,94
5,62
5,78
5,94
6,10
5,30
5,46
5,62
5,78
5,46
Критерий точности
5,46
5,78
5,46
5,78
5,78
5,46
5,30
sCср1
Сср1 = 5,667
= 0,0905
t
5,30
Cср1 Cср 2
sC2 ср1 sC2 ср 2
5,94
sCср 2
Сср2 = 5,587
sCср 2
= 0,0923
При t ≤ 1
Результаты косвенно определяемой величины концентрации Cср1 и Cср2 ,
полученных в разных методиках, достоверно совпадают,
так как между ними нет достоверного различия.
Результат воспроизводится, поскольку разность между ними не превышает
сумму погрешностей смещения средних арифметических значений,
вычисляемых как СКО
Таким образом, воспроизводимость результата анализа,
полученного разными методиками, характеризуют с помощью
вычислений СКО средних арифметических значений и
оценки доверительного коэффициента t как критерия точности
результатов.
Воспроизводимость и
повторяемость непосредственно
результата измерений
Определение Acp и СКО
Определение
доверительного интервала
ΔAcp
(случайнойпогрешности)
и учёт систематической
погрешности Δ
Расчёт суммарной
погрешности
Sсум (ΔAcp + Δ)
Воспроизводимость и
повторяемость результатов,
полученных в 2 методиках анализа
Определение Acp и СКО
Определение суммарной
погрешности методики
анализа SM (СКО + Δ)
Сравнение SrM (СКО +Δ) с
величиной S(%), данной в
описании, или с
величиной SrM (СКО +Δ)
для сравниваемой
методики
Пример 1. Рассмотрим применение формулы для оценки погрешности косвенного
измерения концентрации в фотоколориметрическом методе сравнения
(метод одного стандарта).
В результате 3-х прямых измерений вычислены средние значения <Aст> = 0.148 и
<Aан> = 0.216 оптических плотностей стандартного и анализируемого растворов
Aст l Cст
Aан l C ан
заранее известна концентрация Cст стандартного раствора и = 1.2 мкг/мл.
Вычислены также выборочные СКО для среднего значения
sAан = 4·10-6 оптической плотности и концентрации sAст = 4·10-6.
Определяемая величина среднего значения концентрации анализируемой пробы по методу
одного стандарта:
С ан
Aан
Aст
C ст
0.216
1.2 1.75 мкг/мл
0.148
– есть величина косвенная и зависящая от двух переменных
значений оптической плотности <Aан> и <Aст>, т. е. <Cан> = f (<Aан> , <Aст>).
Дисперсию и СКО s <Cан> находим по формуле распределения погрешностей
2
s 2Са н
Находим производные
2
f 2
f 2
s Aа н
s Aст
Aан
Aст
Cст
Aан
Cст
Aан Aст
Aст
Aст
Aан
C ст Aан
C
ст
2
A
Aст
ст
и подставляем в уравнение для СКО s<Cан> и получим значение
s Са н
Cст
Aст
2
s A2 а н Aан s A2ст
2
Aст
2
0.029
Повторяемость результата измерений данной методикой
соответствует <Cан> = (1.750 ± 0.029) мкг/мл , т.к. определяется СКО
Чтобы оценить повторяемость самого косвенного результата измерений, необходимо
найти значения доверительных интервалов Δ<Cан> концентрации <Cан> в анализируемой пробе.
При P = 0.95 и f = n – 1 = 2 (поскольку было n = 3 повторных параллельных измерения)
найдем табличное значение квантиля Стьюдента, равное 4.30,
Доверительная вероятность P
f=n- 1
0.90
0.95
0.99
1
6.31
12.7
63.7
2
2.92
4.30
9.92
3
2.35
3.18
5.84
4
2.13
2.78
4.60
5
2.01
2.57
4.03
6
1.94
2.45
3.71
7
1.89
2.36
3.50
14
1.76
2.14
2.98
19
1.73
2.09
2.86
30
1.70
2.04
2.75
∞
1.64
1.96
2.58
и подставим в уравнение C ан
s Cан
t P, f
0.029
4.30 0.072
1.73
n
Найденное значение концентрации <Cан> в анализируемой пробе в доверительных
границах ± 0.07 равняется <Cан> = (1.75 ± 0.07) мкг/мл.
Такова повторяемость и воспроизводимость косвенного результата измерений
IV. Алгоритм расчета уравнения линейного градуировочного графика,
его метрологических характеристик
Для определения содержания компонента в пробе методом градуировочного графика
необходимо установление конкретной математической зависимости A = f(C), которую
находят методом регрессионного анализа.
1) Вычисление параметров a и b (например, закон светопоглощения Бера).
В общем случае линейная зависимость A = f(C) выражается уравнением A
a bC
Имеем n взаимосвязанных пар экспериментальных значений (Ai , Ci) – точек графика, то мо
записать:
A1 a b C1
A2 a b C2
…………….
Ai a b Ci
……………..
An a b C n
Полученные нами в прямых
измерениях значения оптических
плотностей Ai стандартных растворов
Вычисленные значения Yi = a + bCi
Задача метода наименьших квадратов (МНК) – регрессионного анализа
n
2
n
SQ ( Ai Yi ) Ai a b C i МИН
2
i 1
Оптическая плотность
A
0,8
0,6
0,4
i 1
Linear Regression for Data1_Ax:
Y=A+B*X
Param
Value
sd
A -0,00643
0,02728
B 0,13357
0,00757
R = 0,99207
SD = 0,04004, N = 7
SQ 0
a
SQ 0
b
0,2
Решаем полученную
систему 2-х уравнений
b
0,0
0
1
2
3
4
5
6
Cv , ммоль/л
Значения параметров a и b:
b
n Ci Ai Ci Ai
n Ci2 Ci
2
C A C C
a
n C C
2
i
i
i
i
Ai
ср
i
2
i
1
Ci
n
Aср
ср
2
ср
i
i
2
i
i
где значения C ср
i
2
i
2
2
i
C A n C A
C n C
C A C C
C n C
1
Ai
n
i
Ai
2
ср
– средние арифметические значения от вс
значений концентраций выборки и
соответствуют серединной точке П (Cср; Aср) графика.
2) Определение дисперсии параметров a и b.
Для этого вычисляют дисперсии
параметров a и b по формулам:
и
s
2
a
n s A2 ,C
s
n C Ci
2
b
2
2
i
s A2 ,C Ci2
n Ci2 Ci
2
со степенями свободы f = n – 2 .
Дисперсию s2A, C , характеризующую рассеяние результатов относительно прямой,
вычисляем по формуле
n
s
2
A ,C
(A
i 1
i
Yi )
n2
2
n
2
A a b C
i 1
i
i
n2
A
2
i
a Ai b Ci Ai
n2
со степенями свободы f = n – 2 .
В задачу корреляционного анализа входит:
1. установление корреляционной связи между величинами;
2. измерение тесноты (плотности) связи двух (в случае парной) и более перемен
В нашем случае первая задача решена – связь существует, а вот степень тесноты
этой связи можно рассчитать используя следующее уравнение:
n Ci Ai Ci Ai
RC , A
Оптическая плотность
A
0,8
0,6
0,4
n C
2
i
Ci n Ai2 Ai
2
2
Linear Regression for Data1_Ax:
Y=A+B*X
Param
Value
sd
A -0,00643
0,02728
B 0,13357
0,00757
R = 0,99207
SD = 0,04004, N = 7
СКО
a = - 0.006 ± 0.027
b = 0.134 ± 0.008
RC, A = 0.992
sA,C = 0.040
0,2
b
0,0
0
1
2
3
4
5
6
Cv , ммоль/л
Пример условно плохой корреляции
N=8
Оптическая плотность
A
1,0
0,8
0,6
R=0.981
Linear Regression for Data1_Ax2:
Y=A+B*X
Param Value
sd
A 0,00417
0,04432
B 0,13167
0,01059
R = 0,98113
SD = 0,06866, N = 8
0,4
0,2
0,0
0
2
4
6
8
Cv , ммоль/л
Пример хорошей корреляции
N=8
Оптическая плотность
A
1,0
0,8
0,6
R=0.9986
Linear Regression for Data1_Ax1:
Y=A+B*X
Param Value
sd
A -0,01333
0,01261
B 0,13881
0,00301
R = 0,99859
SD = 0,01954, N = 8
0,4
0,2
0,0
0
2
4
6
Cv , ммоль/л
8
3) Определение доверительных интервалов Δa и Δb для значений a и b
Доверительные интервалы для значений a и b вычисляем по известным уже нам уравн
b
sb
n
t P, f
sa
a
n
t P, f
при f = n – 2 или f = n’ – 2 .
Доверительный интервал одного выбранного значения концентрации Ck зависит
от разности (Ck – Cср).
Границы доверительного интервала
в зависимости от C
Оптическая плотность
A
0,8
0,6
Linear Regression for Data1_AxDov:
Y=A+B*X
Param
Value
sd
A -0,00643
0,02728
B 0,13357
0,00757
R = 0,99207
SD = 0,04004, N = 7
П(Cср; Aср)
*
0,4
0,2
0,0
0
1
2
3
4
5
6
Cv , ммоль/л
V. Алгоритм расчета метрологических характеристик результатов
анализа проб с неизвестным содержанием определяемого компонента
по методу градуировочного графика
1) Вычисление среднего значения результата анализа (<Cан>)
Проба определяемого компонента с неизвестным содержанием анализируется m раз
Cан должна находиться в интервале содержаний, для которых вычислена
функциональная зависимость A = f(C).
В результате m измерений оптической плотности мы получаем m значений
аналитического сигнала Aан1, Aан2 , Aан3. После отбраковки выбросов по Qили tт- критерию рассчитываем среднее значение <Aан>, а по уравнению
C ан
Aан a
b
находим среднее значение содержания компонента в анализируемой пробе.
2) Вычисление стандартного отклонения результата анализа s<Cан>
Если каждый из n стандартных растворов анализируется при построении градуировочного
графика без повторений, а анализируемая проба с неизвестным содержанием компонента
– m раз, причем для этих m проб (выборки m опытов) мы получаем среднее значение
<Cан>, то погрешность определения концентрации раствора (результата анализа)
s C ан
2
1 1
A
A
1
ан
ср
2
s A, C 2
2
b
m n b (C i C ср )
при f = n – 2.
2
n
A
A
1
1 1
ан
ср
2
s Cан s A,C
2
2
2
b
m n b n C i C i
Здесь s2A,C - уже вычисленная нами дисперсия, характеризующая рассеяние точек (Ai ,Ci)
относительно аппроксимированной прямой;
<Aан> - среднее значение оптической плотности m прямых определений анализируемой
пробы неизвестной концентрации;
Aср и Сср – усредненные значения оптической плотности и концентрации всей выборки
стандартных растворов, использованных для построения градуировочного
графика (то есть середина отрезков по осям ординат и абсцисс соответственно).
3) Доверительный интервал результата анализа Δ<Cан> вычисляется, как обычно, по формуле
Сан s Cан t P , f
но при f = n – 2, а не f = m – 1, потому что при расчете учитываются все точки построения
графика, а не m повторений анализируемой пробы.
4) Границы доверительного интервала результата анализа находим по формуле
<Cан> ± Δ<Cан>.
Границы доверительного интервала
в зависимости от C
Оптическая плотность
A
0,8
0,6
Linear Regression for Data1_AxDov:
Y=A+B*X
Param
Value
sd
A -0,00643
0,02728
B 0,13357
0,00757
R = 0,99207
SD = 0,04004, N = 7
П(Cср; Aср)
*
0,4
0,2
0,0
0
1
2
3
4
5
6
Cv , ммоль/л
Границы доверительного интервала
в зависимости от C
Оптическая плотность
A
0,8
0,6
Linear Regression for Data1_AxDov:
Y=A+B*X
Param
Value
sd
A -0,00643
0,02728
B 0,13357
0,00757
R = 0,99207
SD = 0,04004, N = 7
П(Cср; Aср)
*
0,4
0,2
0,0
0
1
2
3
4
5
6
Cv , ммоль/л
Прямая зависимость:
A l C
A a1 ( l ) C a1 b1 C
A = f(C, a1, b1) функция переменных значений C, a1 и b1:
Например, закон светопоглощения Бера в общем виде:
A = a1 + b1·C
Обращённая зависимость закона Бера:
Если A – измеряемая величина в прямых измерениях, то значение C –
определяется косвенно по уравнению
из прямой зависимости
C = a + b·A, полученному
A a1 b1 C
как
A a1 1
a1
С
A a b A
b1
b1
b1
где
A a1 b1 C
a1
a
b1
1
b
b1
Воспроизводимость результатов, полученных 2-мя методиками,
характеризуются значением стандартного отклонения s (СКО)
n
s
(A A
ср
i
i 1
)2
n 1
для косвенно определяемой величины – sC :
f 2 f 2 f 2
sC s A sa sb
A
a
b
2
2
2
или относительного стандартного отклонения sr и sC/C:
sr s
Aср
srС
sC
C
СРАВНЕНИЕ МЕТОДИК
Повторяемость (сходимость)
результатов анализа
Воспроизводимость
результатов анализа
Внутрилабораторная
Фиксированные условия
выполнения эксперимента
Межлабораторная
Варьируемые условия
выполнения эксперимента
Для прямых измерений аналитического сигнала A или косвенно
определяемой величины C определяется дисперсией (или СКО):
n
s
(A A
i 1
i
ср
)
n 1
для прямых
измерений
2
f
f
f
sC s A2 sa2 sb2
A
a
b
2
2
для косвенно
определяемой величины
2
СРАВНЕНИЕ МЕТОДИК
ХИМИЧЕСКИЙ АНАЛИЗ МНОГОСТАДИЕН:
Воспроизводимость
результатов измерений s аналитического сигнала (или концентрации) не
совпадает с воспроизводимостью методики анализа SM.
Подготовительные операции пробы
перед измерениями: взятие навесок,
измерение объёмов и т.д.
2
Sпо sпо
2по
2
Sоп sоп
2оп
Отбор пробы
Sи sи2 2и
Измерения
Учёт s (СКО) и
систематической
погрешности Δ
на каждом этапе
Sоп – совокупность погрешностей отбора пробы;
Sпо – совокупность погрешностей подготовительных операций пробы перед
измерениями;
Sи – совокупность погрешностей измерения.
Суммарная погрешность методики вычисляется по формуле
SM S S S
2
оп
2
по
2
и
S rM
SM
100%
Aср
Относительную погрешность SrM для этой методики сравнивают с SrM,
полученной для другой методики или указанной в описании величиной в %