NeiroTECN6
реклама

Нейросетевые технологии в
обработке и защите данных
Обработка данных искусственными
нейронными сетями (ИНС).
Лекция 6.
Многослойный персептрон.
Метод обратного распространения ошибки.
1
Нейронные искусственные
сети, успешно применяемые для
решения задач классификации,
прогнозирования и управления,
обеспечивают предельное
распараллеливание алгоритмов,
соответствующих нейросетевой
технологии обработки данных.
2
Характеристика алгоритмов
обучения
Адаптация и самоорганизация искусственных
нейронных сетей достигается в процессе их обучения.
Обучение нейронной сети может вестись с учителем
или без него. В первом случае сети предъявляются
значения как входных, так и желательных выходных
сигналов, и она по некоторому внутреннему алгоритму
подстраивает веса своих синаптических связей. Во втором
случае выходы нейронной сети формируются
самостоятельно, а веса изменяются по алгоритму,
учитывающему только входные и производные от них
сигналы
3
Свойства нейросетей
• Способность сети, обученной на некотором множестве
данных выдавать правильные результаты для достаточно
широкого класса новых данных, в том числе и не
представленных при обучении, называется свойством
обобщения нейронной сети.
• Для настройки параметров нейронных сетей широко
используется также процедура адаптации, когда
подбираются веса и смещения с использованием
произвольных функций их настройки, обеспечивающие
соответствие между входами и желаемыми значениями на
выходе.
4
Процесс обучения – это процесс
определения параметров модели процесса
или явления, реализуемого нейронной
сетью. Ошибка обучения для конкретной
конфигурации сети определяется после
прогона через сеть всех имеющихся
наблюдений и сравнения выходных
значений с целевыми значениями в случае
обучения с учителем.
Соответствующие разности позволяют
сформировать так называемую функцию
ошибок.
5
Функции ошибок
Если ошибка сети, выходной слой которой имеет n
нейронов, есть разность между реальным и желаемым
сигналами на выходе i-го нейрона, то в качестве функций
ошибок могут быть использованы следующие функции:
n
• сумма квадратов ошибок sse = ei2 ,
i 1
1 n 2
• средняя квадратичная ошибка mse = ei ,
n i 1
• регулируемая или комбинированная ошибка
msereg =
n 2 1 n 2
e
e
n i 1 i
n i 1 i
, где - параметр регуляции,
• средняя абсолютная ошибка mae =
1 n
ei
n i 1
.
6
Для нейронных сетей с нелинейными
функциями активации в общем случае нельзя
гарантировать достижение глобального минимума
функции ошибки. Поверхность функции ошибок
определяется как совокупность точек-значений
ошибок в N+1-мерном пространстве
всевозможных сочетаний весов и смещений с
общим числом N.
Цель обучения при геометрическом анализе
или изучении поверхности ошибок состоит в том,
чтобы найти на ней глобальный минимум. По
существу алгоритмы обучения нейронных сетей
аналогичны алгоритмам поиска глобального
экстремума функции многих переменных.
7
Классификация методов
определения экстремума
Методы определения экстремума функции нескольких
переменных делятся на три категории – методы нулевого,
первого и второго порядка:
• методы нулевого порядка, в которых для нахождения
экстремума используется только информация о значениях
функции в заданных точках;
• методы первого порядка, где для нахождения экстремума
используется градиент функционала ошибки по
настраиваемым параметрам;
• методы второго порядка, вычисляющие матрицу вторых
производных функционала ошибки (матрицу Гессе).
8
В пакете NNT системы MATLAB реализованы
два способа адаптации и обучения,
последовательный и групповой, в зависимости от
того, применяется ли последовательное или
групповое представление входов и целевого
вектора (массив ячеек cell и массив формата
double соответственно).
Названия процедур обучения и адаптации
нейроимитатора NNT системы MATLAB
приводятся по мере рассмотрения
соответствующих правил обучения нейронных
сетей.
9
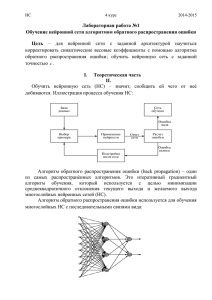
МЕТОД ОБРАТНОГО
РАСПРОСТРАНЕНИЯ ОШИБКИ
Метод обратного распространения
ошибки предложен несколькими авторами
независимо в 1986 г. для многослойных
сетей с прямой передачей сигнала (feedforward).
Многослойная нейронная сеть способна
осуществлять любое отображение входных
векторов в выходные
10
МЕТОД ОБРАТНОГО
РАСПРОСТРАНЕНИЯ ОШИБКИ
11
МЕТОД ОБРАТНОГО
РАСПРОСТРАНЕНИЯ ОШИБКИ
Цель обучения состоит в подборе таких значений
весов и для слоев сети, чтобы при заданном входном
векторе х получить на выходе значения сигналов yi,
которые с требуемой точностью будут совпадать с
ожидаемыми значениями di для i = 1, 2,…, M. Если
рассматривать единичный сигнал как одну из компонент
входного вектора х, то веса смещения можно добавить в
векторы весов соответствующих нейронов обоих слоев.
При таком подходе выходной сигнал i-го нейрона
скрытого слоя описывается функцией
N
(1)
u j f wij x j
,
j 0
12
МЕТОД ОБРАТНОГО
РАСПРОСТРАНЕНИЯ ОШИБКИ
в которой индекс 0 соответствует смещению, причем
u0 1, x0 1.
В выходном слое k-й нейрон вырабатывает выходной
сигнал, определяемый как:
K ( 2 ) N (1)
N ( 2)
yk f wki ui f wki f wij x j
i 0
j
0
i 0
Из формулы , приведенной выше, следует, что на
значение выходного сигнала влияют веса обоих слоев,
тогда как сигналы, вырабатываемые в скрытом слое, не
зависят от весов выходного слоя.
13
E (k )
wij (t 1) wij (t )
wij (t )
E (k )
S 0 j (t 1) S 0 j (t )
S 0 j (t )
i=1,2,…,n; j=1,2,…,p,
где E – среднеквадратичная ошибка сети для одного из k
образов,
определяемая по формуле:
1 p
E ( y j t j )2
2 j 1
МЕТОД ОБРАТНОГО
РАСПРОСТРАНЕНИЯ ОШИБКИ
wij (t 1) wij (t ) j y j (1 y j ) yi
S0 j (t 1) S0 j (t ) j y j (1 y j )
i=1,2,…,n, j=1,2,…,p,
ошибка j-го нейрона выходного слоя
определяется как
ץj = y j – tj,
15
МЕТОД ОБРАТНОГО
РАСПРОСТРАНЕНИЯ ОШИБКИ
В случае применения градиентных методов
оптимизации необходимо вычисление вектора
градиента относительно весов для всех слоев
сети. Так как эта задача имеет очевидное решение
только для выходного слоя сети, то для других
слоев используется алгоритм обратного
распространения ошибки, отождествляемый
обычно с процедурой обучения сети.
16
МЕТОД ОБРАТНОГО
РАСПРОСТРАНЕНИЯ ОШИБКИ
В соответствии с этим алгоритмом в каждом
цикле обучения выделяются следующие этапы:
1) Анализ нейронной сети в прямом
направлении передачи информации,
составляющей очередной вектор x. В результате
такого анализа рассчитываются значения
выходных сигналов нейронов скрытых слоев и
выходного слоя, а также соответствующие
производные функций активации каждого слоя
(m – количество слоев сети).
17
МЕТОД ОБРАТНОГО
РАСПРОСТРАНЕНИЯ ОШИБКИ
2) Создание сети обратного распространения
ошибок путем изменения направлений передачи
сигналов, замена функций активации их
производными и подача на бывший выход (а в
настоящий момент – вход) сети возбуждения в
виде разности между фактическим и ожидаемым
значением. Для определенной таким образом сети
необходимо рассчитать значения требуемых
обратных разностей.
18
МЕТОД ОБРАТНОГО
РАСПРОСТРАНЕНИЯ ОШИБКИ
3)
Уточнение весов (обучение сети)
производится по приведенным выше
формулам на основе результатов,
полученных на этапах 1 и 2, для
оригинальной сети и для сети обратного
распространения ошибки.
19
МЕТОД ОБРАТНОГО
РАСПРОСТРАНЕНИЯ ОШИБКИ
4) Описанный на этапах 1, 2 и 3 процесс
следует повторить для всех обучающих
выборок, продолжая его вплоть до
выполнения условия остановки алгоритма.
Действие алгоритма завершается в
момент, когда норма градиента становится
меньше априори заданного значения ,
характеризующего точность процесса
обучения.
20
Недостатки МОРО
К недостаткам метода обратного
распространения ошибки относят следующие:
• Медленную сходимость градиентного метода при
постоянном шаге обучения;
• Возможное смешение точек локального и
глобального минимумов;
• Влияние случайной инициализации весовых
коэффициентов на скорость поиска минимума.
21
Модификации МОРО
1. с импульсом, позволяющим учесть текущий и
предыдущий градиенты, изменение веса тогда:
w (t 1) F ' ( S ) y w (t ) ,
ij
j
j
i
ij
где – коэффициент скорости обучения, – импульс
или момент, обычно 0 < < 1, 0,9;
2. с адаптивным шагом обучения, изменяющимся по
формуле:
(t )
1
1 xi2 (t )
22
Классификация символов
Демонстрационная программа пакета NNT
системы MATLAB – расчета и
проектирования искусственных нейронных
сетей, appcr1
(D:\MATLAB\toolbox\nnet\nndemos),
иллюстрирует, как распознавание символов
может быть выполнено с помощью
однонаправленной многослойной сети на
основе метода обратного распространения
ошибки
23
Классификация символов
Для распознавания 26 символов латинского
алфавита, получаемых, например, с помощью
системы распознавания, выполняющей оцифровку
каждого символа в ее поле зрения, используется
сеть из двух слоев, не считая входного, с n (10)
нейронами в скрытом слое и p (26) нейронами в
выходном (по одному на букву).
Каждый символ представляется шаблоном
размера 7 5, соответствующим пиксельной
градации букв
24
Классификация символов
Проектируемая нейронная сеть должна точно
распознать идеальные векторы входа и с
максимальной точностью воспроизводить
зашумленные векторы.
Функция prprob формирует 26 векторов
входа, каждый из которых содержит 35 элементов,
называемых алфавитом. Она создает выходные
переменные alphabet и targets, которые
определяют массивы алфавита и целевых
векторов. Массив targets задается как единичная
матрица функцией eye(26).
25
СОЗДАНИЕ СЕТИ
Двухслойная нейронная сеть создается с помощью команды
newff, предназначенной для описания многослойных нейронных
сетей прямой передачи сигнала с заданными функциями обучения и
настройки на основе метода обратного распространения ошибки, и
имеющей формат:
net=newff(PR, [S1 S2 …SN],{TF1 TF2 …TFN},btf,blf,pf),
где PR – массив размера R × 2 минимальных и максимальных
значений для R векторов входа;
Si – количество нейронов в слое i;
Tfi – функция активации слоя i, по умолчанию tansig;
btf – обучающая функция, реализующая метод обратного
распространения ошибки, по умолчанию trainlm;
blf – функция настройки, реализующая метод обратного
распространения, по умолчанию learngdm;
pf – критерий качества обучения, по умолчанию средняя
квадратичная ошибка mse.
26
ОБУЧЕНИЕ СЕТИ
Для обучения сетей в пакете NNT применяется функция train,
позволяющая установить процедуры обучения сети и настройки ее
параметров и имеющая формат:
[net, TR]=train(net, P, T, Pi, Ai), где входные аргументы:
net – имя нейронной сети,
P – массив входов,
T – вектор целей, по умолчанию нулевой вектор,
Pi – начальные условия на линиях задержки входов, по
умолчанию нулевые,
Ai – начальные условия на линиях задержки слоев, по
умолчанию нулевые; а выходные:
net – объект класса network.object после обучения;.
TR – характеристики процедуры обучения
27
Моделирование нейронных сетей
в пакете NNT обеспечивает функция sim, имеющая формат
[Y, Pf, Af, E, perf]= sim(net, P, Pi, Ai, T), где входные аргументы:
net – имя нейронной сети,
P – массив входов,
Pi – начальные условия на линиях задержки входов, по
умолчанию нулевой вектор,
Ai – начальные условия на линиях задержки слоев, по
умолчанию нулевой вектор,
T – вектор целей, по умолчанию нулевой вектор;
выходные аргументы:
Y – массив выходов,
Pf – состояния на линиях задержки входов после моделирования,
f – состояния на линиях задержки слоев после моделирования,
E – массив ошибок,
perf – значение функционала качества
28
ОБУЧАЮЩИЕ ФУНКЦИИ
В пакете NNT встроено несколько
обучающих функций, реализующих метод
обратного распространения ошибки, по
умолчанию trainlm :
1. traingdx , МОРО с импульсом и адаптацией
2. traincgp, сопряженных градиентов
(Поллака - Рибейры);
3. trainlm, метод Левенберга – Марквардта,
относящийся к методам второго порядка
29
Лабораторная работа
Изучить
prprob,appcr1MATLAB\toolbox\nnet\nndemos,
newff,
traingdx,learngdmMATLAB\toolbox\nnet\nnet.
1. Построить нейронные сети для распознавания
букв латинского алфавита (двухслойную и
трехслойную), используя функцию newff –
инициализации сети прямой передачи сигнала.
2. Обучить сеть, используя функции traingdx
(traincga, trainlm)
3. Распознать фразу из зашумленных символов
(функция sim).
30