Кто вы такие?
реклама

Загадки Sphinx-а
Анатомический атлас поискового движка
Кто вы такие?
• Sphinx – полнотекстовый поисковик
Кто вы такие?
• Sphinx – полнотекстовый поисковик
• Умеет копать
Кто вы такие?
• Sphinx – полнотекстовый поисковик
• Умеет копать
• Умеет не копать
Кто вы такие?
•
•
•
•
Sphinx – полнотекстовый поисковик
Умеет копать
Умеет не копать
Умеет передать лопату соседу
Кто вы такие?
•
•
•
•
•
Sphinx – полнотекстовый поисковик
Умеет копать
Умеет не копать
Умеет передать лопату соседу
Умеет много гитик
– «фасеточный» поиск, геопоиск, создание
сниппетов, мультизапросы, IO throttling, и еще
10-20 других интересных директив
Зачем вас позвали?
• Чего не будет в докладе?
– Вводного обзора «что это и зачем мне»
– Длинных цитат из документации
– Подробного разбора C++ архитектуры
Зачем вас позвали?
• Чего не будет в докладе?
– Вводного обзора «что это и зачем мне»
– Длинных цитат из документации
– Подробного разбора C++ архитектуры
• Что будет?
– Как оно в целом устроено внутри
– Как можно оптимизировать разное
– Как можно распараллеливать разное
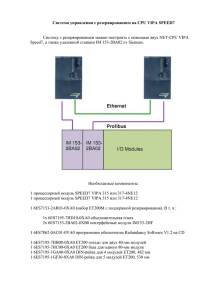
Глава 1. Потроха движка
Вспомнить workflow
• Сначала индексируем
• Потом ищем
Вспомнить workflow
• Сначала индексируем
• Потом ищем
• Есть источники данных (откуда и что брать)
• Есть индексы
– Какие источники брать
– Как обрабатывать текст
– Куда складывать результат
Как работает индексация
• В двух актах, с антрактом
• Фаза 1 – сбор документов
– Получаем документы (цикл по источникам)
– Разбиваем каждый документ на слова
– Обрабатываем слова (морфология, *фиксы)
– Заменяем слова на wordid (CRC32/64)
– Пишем ряд временных файлов
Как работает индексация
• Фаза 2 – сортировка хитов
–
–
–
–
Хит (hit, вхождение) – запись (docid,wordid,wordpos)
На входе частично сортированные (по wordid) данные
Сортируем слиянием списки хитов
На выходе полностью сортированные данные
• Интермеццо
– Собираем и сортируем значения MVA
– Сортируем ordinals
– Сортируем extern атрибуты
Тупой и еще тупее
• Формат индекса на выходе… несложен
• Несколько сортированных массивов
– Словарь (список wordid)
– Атрибуты (только если docinfo=extern)
– Список документов (для каждого слова)
– Список позиций (для каждого слова)
• Всё уложено линейно, хорошо для IO
Как работает поиск
• Для каждого локального индекса
– Строим список кандидатов (документов,
удовлетворяющих запросу)
– Фильтруем (аналог – WHERE)
– Ранжируем (считаем веса документов)
– Сортируем (аналог – ORDER BY)
– Группируем (аналог – GROUP BY)
• Склеиваем результаты по всем индексам
1. Цена поиска
• Построение списка кандидатов
– 1 ключевое слово = 1+ IO (список документов)
– Булевы операции над списками документов
– Стоимость пропорциональна (~) длине списков
– То есть, сумме частот всех ключевых слов
– При поиске фраз итп, еще и операции над
списками позиций слов – примерно 2x IO/CPU
1. Цена поиска
• Построение списка кандидатов
– 1 ключевое слово = 1+ IO (список документов)
– Булевы операции над списками документов
– Стоимость пропорциональна (~) длине списков
– То есть, сумме частот всех ключевых слов
– При поиске фраз итп, еще и операции над
списками позиций слов – примерно 2x IO/CPU
• Мораль – “The Who” – очень плохая музыка
2. Цена фильтрации
• docinfo=inline
– Атрибуты хранятся в списке документов
– ВСЕ значения дублируются МНОГО раз!
– Доступны сразу после чтения с диска
• docinfo=extern
– Атрибуты хранятся в отдельном списке (файле)
– Полностью кэшируются в RAM
– Хэш по docid + бинарный поиск
• Перебор фильтров
• Cтоимость ~ числу кандидатов и фильтров
3. Цена ранжирования
• Прямая – зависит от ranker-а
– Учитывать позиции слов –
• Полезно для релевантности
• Но стоит ресурсов – двойной удар!
• Стоимость ~ числу результатов
• Самый дорогой – phrase proximity + BM25
• Самый дешевый – none (weight=1)
• Косвенная – может наводиться в сортировке
4. Цена сортировки
• Стоимость ~ числу результатов
• Еще зависит от критерия сортировки
(документы придут в порядке @id asc)
• Еще зависит от max_matches
• Чем больше max, тем хуже серверу
• 1-10K приемлемо, 100K перебор
• 10-20 недобор
5. Цена группировки
•
•
•
•
Группировка внутри – подвид сортировки
Тоже число результатов
Тоже max_matches
Вдобавок, от max_matches зависит
точность @count и @distinct
Глава 2. Оптимизируем разное
Как оптимизировать запросы
• Разбиение данных (partitioning)
•
•
•
•
Режимы ранжирования и сортировки
Фильтры против ключевых слов
Фильтры и MTF вручную
Мультизапросы (multi queries)
Как оптимизировать запросы
• Разбиение данных (partitioning)
•
•
•
•
Режимы ранжирования и сортировки
Фильтры против ключевых слов
Фильтры и MTF вручную
Мультизапросы (multi queries)
• Последняя линия защиты – Три Большие Кнопки
1. Разбиение данных
• Чисто швейцарский нож, для разных задач
• Уперлось в переиндексацию?
– Разбиваем, переиндексируем только изменения
• Уперлось в фильтрацию?
– Разбиваем, ищем только по нужным индексам
• Уперлось в CPU/HDD?
– Разбиваем, разносим по разным
cores/HDDs/boxes
1a. Разбиение под индексацию
•
•
•
•
•
•
Необходимо держать баланс
Не добьешь – будет тормозить индексация
Перебьешь – будет тормозить поиск
1-10 индексов – работают разумно
Некоторых устраивает и 50+ (30+24...)
Некоторых устраивает и 2000+ (!!!)
1b. Разбиение под фильтрацию
• Полностью, на 100% зависит от статистики
боевых запросов
– Анализируйте свои личные боевые логи
– Добавляйте комментарии (3й параметр Query())
• Оправдано только при существенном
уменьшении обрабатываемых данных
– Для документов за последнюю неделю – да
– Для англоязычных запросов – нет (!)
1c. Разбиение под CPU/HDD
• Распределенный индекс, куски явно
дробим по физическим устройствам
• Прицеливаем searchd “сам на себя” –
index dist1
{
type = distributed
local = chunk01
agent = localhost:3312:chunk02
agent = localhost:3312:chunk03
agent = localhost:3312:chunk04
}
1c. Как искать CPU/HDD заторы
• Три стандартных средства
– vmstat – чем и насколько занят CPU?
– oprofile – кем конкретно занят CPU?
– iostat – насколько занят HDD?
•
•
•
•
Плюс логи, плюс опция searchd --iostats
Обычно все наглядно (us/sy/bi/bo…), но!
Ловушка – HDD может упираться в iops
Ловушка – CPU может прятаться в sy
2. Ранжирование
• Теперь бывает разное (т.н. ранкеры в
режиме поиска extended2)
• Ранкер по умолчанию – phrase+BM25,
анализирует позиции слов – не бесплатно
• Иногда достаточно более простого
• Иногда @weight игнорируется совсем
(ищем ipod, сортируем по цене)
• Иногда можно сэкономить
3. Фильтры против спецслов
• Известный трюк
– При индексации, добавляем специальное
ключевое слово в документ (_authorid123)
– При поиске, добавляем его в запрос
• Понятный вопрос
– Что быстрее, как лучше?
• Нехитрый ответ
– Считайте ценник, не отходя от кассы
3. Фильтры против спецслов
• Цена булева поиска ~ частотам слов
• Цена фильтрации ~ числу кандидатов
• Поиск – CPU+IO, фильтр – только CPU
• Частота спец-слова
= селективности значения фильтра
• Частое значение + мало кандидатов → плохо!
• Редкое значение + много кандидатов → хорошо!
4. Фильтры и MTF вручную
• Фильтры перебираются последовательно
• В порядке, указанном приложением!
• Самый жесткий – лучше ставить в начале
• Самый нестрогий – лучше ставить в конце
• При замене спец-словами – не важно
• Домашняя работа – а почему?
5. Мультизапросы
• Любые запросы можно передать пачкой
• Всегда экономит network roundtrip
• Иногда может сработать оптимизатор
• Особо важный и нужный случай –
разные режимы сортировки-группировки
• 2x+ оптимизация “фасеточного” поиска
5. Мультизапросы
$client = new SphinxClient ();
$q = “laptop”; // coming from website user
$client->SetSortMode ( SPH_SORT_EXTENDED, “@weight desc”);
$client->AddQuery ( $q, “products” );
$client->SetGroupBy ( SPH_GROUPBY_ATTR, “vendor_id” );
$client->AddQuery ( $q, “products” );
$client->ResetGroupBy ();
$client->SetSortMode ( SPH_SORT_EXTENDED, “price asc” );
$client->SetLimit ( 0, 10 );
$result = $client->RunQueries ();
6. Три Большие Кнопки
• Если ничто другое не помогает…
• Cutoff (см. SetLimits())
– Останов поиска после N первых совпадений
– В каждом индексе, не суммарно
• MaxQueryTime (см. SetMaxQueryTime())
– Останов поиска после M миллисекунд
– В каждом индексе, не суммарно
6. Три Большие Кнопки
• Если ничто другое не помогает…
• Consulting
– Можем заметить незамеченное
– Можем дописать недописанное
Глава 3. Пример распараллеливания
Боевая задача
• Есть ~160M кросс-ссылок
• Нужен ряд отчетов (по доменам→groupby)
*************************** 1. row ***************************
domain_id: 440682
link_id: 15
url_from: http://www.insidegamer.nl/forum/viewtopic.php?t=40750
url_to: http://xbox360achievements.org/content/view/101/114/
anchor: NULL
from_site_id: 9835
from_forum_id: 1818
from_author_id: 282
from_message_id: 2586
message_published: 2006-09-30 00:00:00
...
Решаем – раз
• Дробим данные
• 8 машин, 4x CPU, ~5M ссылок на CPU
• Используем Sphinx
• Теоретически можно MySQL
• Практически сложно
– Выйдет 15-20M+ rows/CPU
– Агрегацию придется делать вручную
Решаем – два
• Выделяем “интересные части” URL при
индексации UDF-кой
• Выборку подменяем текстовым запросом
*************************** 1. row ***************************
url_from: http://www.insidegamer.nl/forum/viewtopic.php?t=40750
urlize(url_from,0): www$insidegamer$nl
insidegamer$nl
insidegamer$nl$forum
insidegamer$nl$forum$viewtopic.php
insidegamer$nl$forum$viewtopic.php$t=40750
urlize(url_from,1): www$insidegamer$nl
insidegamer$nl
insidegamer$nl$forum
insidegamer$nl$forum$viewtopic.php
Решаем – три
• 64 индекса
– 4 копии searchd на сервер, по числу CPU/HDD
– 2 индекса (main+delta) на CPU
• Обыскиваются параллельно
– Web box спрашивает главную копию searchd
– Главная спрашивает себя и остальные 3 копии
– Используем 4 копии, потому что startup/update
– Используем plain HDD, потому что IO stepping
Результаты
• Точность приемлема
• “Редкие” домены – без ошибок
• “Частые” домены – в пределах 0.5%
•
•
•
•
Среднее время запроса – 0.125 sec
90% запросов – менее 0.227 sec
95% запросов – менее 0.352 sec
99% запросов – менее 2.888 sec
Конец