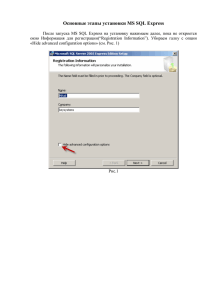
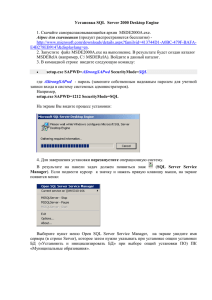
Поиск неструктурированных данных в SQL Server 2008
реклама

Управление неструктурированными данными при помощи SQL Server 2008 Техническая статья о SQL Server. Автор: Грэм Малколм (Graem Malcolm), ответственный за содержание Технический рецензент: Шэн Синха (Shan Sinha) Редактор проекта: Джоан Ходжинс (Joanne Hodgins) Документ опубликован: Август 2007 года Применение: SQL Server 2008 Аннотация: Рост объема информации в цифровой форме оказал значительное влияние на хранение бизнес-данных и доступ к ним. Постоянно растет число приложений для бизнеса, использующих неструктурированные данные, такие как документы, изображение, видео содержимое и данные в других форматах мультимедиа, а следовательно базы данных, используемые этими приложениями, должны быть интегрированы с неструктурированными данными. Для организаций все более важной становится возможность хранить цифровые данные в различных форматах и управлять этими данными. Это необходимо для того, чтобы управлять жизненным циклом информации, следовать регулятивным нормам и реализовывать решения для управления содержимым. Microsoft SQL Server предоставляет гибкое решение для хранения неструктурированных данных и использования одновременно неструктурированных и реляционных данными. Такое решение необходимо для построения полнофункционального решения для работы со всеми данными организации. Microsoft Corporation ©2007 Copyright This is a preliminary document and may be changed substantially prior to final commercial release of the software described herein. The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication. This White Paper is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE INFORMATION IN THIS DOCUMENT. Complying with all applicable copyright laws is the responsibility of the user. Without limiting the rights under copyright, no part of this document may be reproduced, stored in or introduced into a retrieval system, or transmitted in any form or by any means (electronic, mechanical, photocopying, recording, or otherwise), or for any purpose, without the express written permission of Microsoft Corporation. Microsoft may have patents, patent applications, trademarks, copyrights, or other intellectual property rights covering subject matter in this document. Except as expressly provided in any written license agreement from Microsoft, the furnishing of this document does not give you any license to these patents, trademarks, copyrights, or other intellectual property. 2007 Microsoft Corporation. All rights reserved. Microsoft, Excel, SQL Server, and Windows are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries. The names of actual companies and products mentioned herein may be the trademarks of their respective owners. Microsoft Corporation ©2007 Содержание Введение ......................................................................................................... 1 Бизнес-драйвер для неструктурированных данных ...................................... 1 Сложности в работе с неструктурированными данными ................................... 2 Сложности, связанные с сохранением неструктурированных данных ........... 2 Сложности, связанные с использованием неструктурированных данных ...... 3 Цели SQL Server 2008 в работе с неструктурированными данными ................... 3 Хранение неструктурированных данных в SQL Server 2008 ......................... 4 BLOB-данные в SQL Server ............................................................................. 4 Атрибут FILESTREAM ...................................................................................... 5 Программный интерфейс Remote BLOB Store API ............................................. 5 Сравнение вариантов хранения BLOB-данных ................................................. 6 Поиск неструктурированных данных в SQL Server 2008 ............................... 7 Интегрированный полнотекстовый поиск ........................................................ 7 Заключение ..................................................................................................... 7 Microsoft Corporation ©2007 SQL Server 2008. Управление неструктурированными данными при помощи SQL Server 2008. 1 Введение В последние годы произошел резкий рост объема цифровых данных, создаваемых и сохраняемых как отдельными пользователями, так и организациями. Исторически предприятия использовали компьютерные системы и базы данных, предназначенные для хранения большей части данных в структурованных форматах, таких как реляционные таблицы или файлы с определенной структурой. Подобные хранилища структурированных данных использовались приложениями для выполнения задач предприятия. Однако на сегодняшний день данные на предприятиях в основном сохраняются в виде документов, созданных при помощи таких производительных средств, как Microsoft® Office Excel® и Microsoft Office Word, а достижения в области цифровой фотографии, сканирования документов, а также развитие звуковых и видеоформатов еще больше расширили спектр используемых форматов для бизнесданных. Кроме того, резкое снижение стоимости запоминающих устройств и памяти оказало значительное влияние на количество и типы данных, сохраняемых в компьютерных системах, и привело к появлению нового поколения приложений для бизнеса, в которых традиционные реляционные структуры данных используются совместно с неструктурированными цифровыми данными. Для предприятий такое обилие цифрового содержания означает поиск путей управления как реляционными, так и неструктурированными данными, способных удовлетворить потребности всей компании. Поэтому необходимо решение, полностью отвечающее требованиям хранения обоих групп данных, при этом снижающее стоимость управления этими данными и создания приложений, которые бы с ними работали. Например, рассмотрим вероятное изменение приложения, обрабатывающего страховые иски, за последние пятнадцать лет. Пятнадцать лет назад такое приложение, скорее всего, поддерживало бы список записей по страховым искам, сохраненный как простые строчки и столбцы. Сегодня записи по страховым искам для приложения скорее всего включают базовые изображения, фотографии и документы. Также для интеграции с другими системами такое приложение, возможно, должно поддерживать экспорт данных по искам в форматах, основанных на XML, и включать такие функциональные возможности высокого уровня, как использование пространственных зрительных образов, отчетов и анализа данных. SQL Server 2008 предоставляет новые возможности, которых не было в традиционных системах баз данных, превращаясь в платформу для сохранения, управления, составления запросов для всех типов данных, включая неструктурированные двоичные данные, XML и пространственные данные. Данный документ касается работы с неструктурированными данными и описывает функции сохранения, управления и использования неструктурированных данных в SQL Server 2008. Бизнес-драйвер для неструктурированных данных Специалисты в большинстве организаций полагаются в своей работе на критичные для бизнеса данные, которые хранятся в базах данных. В системы управления данными, в приложения для сохранения данных и управления ими организации вложили большие средства. Однако на предприятиях накапливаются все большие объемы нереляционных, неструктурированных данных, таких как цифровые изображения, документы, данные в видеоформате и других форматах мультимедиа, и эти новые форматы данных быстро становятся ключевыми компонентом формальных и неформальных бизнес-процессов. Они интегрируются с существующими приложениями, соответствуют нормативным требованиям и просто Microsoft Corporation ©2007 SQL Server 2008. Управление неструктурированными данными при помощи SQL Server 2008. 2 расширяют возможности для пользователя при работе с информационными системами. Рассмотрим, например, следующие бизнес-сценарии: специалистам страховой компании необходимо иметь возможность сохранять полисы и загружать их для обработки исков; для отображения на сайте магазина необходимо иметь возможность сохранять результат видеосъемки товара; для работы телефонной системы необходимо иметь возможность сохранять сообщения голосовой почты, чтобы пользователи могли прослушивать сообщения в удаленном режиме; работникам радиостанции нужна библиотека оцифрованных записей, доступных для загрузки с веб-узла, с функцией поиска; юридической службе необходимо хранить электронные копии документов в формате изображений и иметь возможность легко загрузить документы, имеющие отношение к определенному клиенту или определенному случаю; партнерству архитекторов требуется сохранять и загружать цифровые чертежи, а также относящиеся к ним данные клиентов; библиотеке требуется преобразовывать и архивировать большой объем существующих бумажных документов и аналогового содержимого для индексирования и использования при помощи средства работы с цифровыми справочными материалами. Выше приведены несколько примеров использования неструктурированных цифровых данных на предприятиях во всем мире. Создавать цифровое содержимое становится все проще, и организации находят новые пути использования его для улучшения и расширения своих бизнес-возможностей. Сложности в работе с неструктурированными данными Хотя быстрое распространение новых типов неструктурированного цифрового содержимого приносит ощутимую пользу и открывает новые возможности для бизнеса, параллельно возникают проблемы для разработчиков архитектуры системы, администраторов и разработчиков приложений, которые должны сделать так, чтобы существующие приложения и службы работали с этими неструктурированными источниками данных. Сложности, связанные с сохранением неструктурированных данных Первой и, возможно, наиболее очевидной, проблемой, которую необходимо принимать во внимание, является проблема хранения большого объема неструктурированных данных. Было бы желательно иметь систему, которая обладала бы достаточной гибкостью для того, чтобы отвечать требованиям хранения именно неструктурированных данных при минимальной стоимости и минимальных накладных расходах на управление. Ключевыми возможными проблемами, которые должны быть учтены при планировании хранилища для неструктурированных данных, являются: затраты на хранение неструктурированных данных, включающие не только затраты на оборудование, но и накладные расходы на управление; физические хранилища для неструктурированных данных, такие как файловые серверы и устройства хранения данных, подключаемые к сети (NAS); управление политиками хранения и архивации; Microsoft Corporation ©2007 SQL Server 2008. Управление неструктурированными данными при помощи SQL Server 2008. 3 объединение файлов, содержащих неструктурированные данные, и согласованных с ними реляционными данными, а также обеспечение транзакционной согласованости между источниками структурированных и неструктурированных данных; минимизация накладных расходов на управление, связанных с обслуживанием как структурированных, так и неструктурированных данных; быстродействие и масштабируемость; защита неструктурированных данных и обеспечение согласованной безопасности также для связанных с ними реляционных данных; доступность и возможность восстановления неструктурированных данных. Сложности, связанные с использованием неструктурированных данных Кроме сложностей, связанных с хранением неструктурированных данных, нужно учитывать и то, как эти данные буду использоваться приложениями. Обычные вопросы для рассмотрения включают следующее: на этапе разработки приложения, в котором используются структурированные и неструктурированные данные, могут возникнуть проблемы, связанные с составлением кода, отвечающего за создание, загрузку, обновление и удаление неструктурированных данных, а также с обеспечением транзакционной согласованности между источниками реляционных и неструктурированных данных; индексирование неструктурированных данных и поиск; извлечение метаданных, доступных в явной форме (например, из полей форм или из атрибутов файлов), и предоставление этих данных пользователю; преобразование содержимого документа в форматы, пригодные для выполнения поиска и составления запросов (например, преобразование звуковых файлов в текстовые, в которых затем может быть выполнен поиск по запросу базы данных или поиск при помощи обработчика полнотекстового поиска). Цели SQL Server 2008 в работе с неструктурированными данными Сложности, связанные с неструктурированными данными, отражают некоторые общие проблемы, с которыми сталкиваются специалисты, начинающие разработку решений для цифрового содержимого, такие как: управление несколькими платформами, когда приходится иметь дело как с реляционными, так и с нереляционными данными, приводит к неоправданной сложности; раздельные хранилища данных приводят к повышению сложности разработки приложений, а также к проблемам с управлением развертыванием; разработчики и администраторы баз данных должны принимать меры для компенсации недостающих служб, поскольку их набор может быть разным для данных различных типов. SQL Server 2008 ставит своей целью разрешение этих проблем при помощи: снижения затрат на руководство различными типами данных; упрощения разработки приложений, использующих реляционные и нереляционные данные; расширения возможностей, которые доступны на данный момент только для реляционных данных, чтобы они были доступны и для неструктурированных данных. Microsoft Corporation ©2007 SQL Server 2008. Управление неструктурированными данными при помощи SQL Server 2008. 4 Хранение неструктурированных данных в SQL Server 2008 Приложения, основанные на работе с реляционными и нереляционными данными, в основном используют одну из трех архитектур: реляционные данные находятся в базе данных, а данные в формате больших нереляционных двоичных объектов (BLOB) находятся в файловых системах или на файловых серверах; реляционные данные находятся в базе данных, а нереляционные данные – в хранилище, предназначенном для BLOB-данных; реляционные и нереляционные данные находятся в базе данных. Каждый из перечисленных подходов имеет свои преимущества и недостатки. Например, хранение неструктурированных данных на файловых серверах или в хранилищах, предназначенных для хранения BLOB-данных, может снизить денежные затраты на память, однако это усложнит разработку приложений и управление ими, так как приложения должны поддерживать согласованность между записями в базе данных и системами, в которых находятся BLOB-данные, связанные с этими записями. С другой стороны, при хранении BLOB-данных в базе данных одна база данных становится удобным централизованным хранилищем, но при этом происходит увеличение затрат и может произойти снижение быстродействия. SQL Server 2008 предлагает новые возможности хранения BLOB-данных: FILESTREAM: значение этого атрибута можно установить в столбце varbinary, чтобы данные были сохранены в файловой системе (таким образом используются преимущества и потоковой передачи, и этого способа хранения), но при этом данные доступны напрямую из базы данных, и управление данными осуществляется в контексте этой базы данных; удаленное хранилище BLOB-данных Remote BLOB: программный интерфейс (API), который снижает сложность разработки приложений, использующих BLOB-данные из внешнего хранилища и реляционные данные из базы данных. Кроме того, SQL Server 2008 продолжает поддерживать стандартные столбцы BLOB с типом данных varbinary. BLOB-данные в SQL Server В SQL Server 2005 был использован новый тип данных varbinary(max), который позволяет сохранять большой объем двоичных данных размером до 2 147 483 647 байт в столбце или переменной SQL Server. При использовании модификатора max можно задать значение параметра таблицы large value types out of row, который позволяет контролировать, в каком виде происходит физическое хранение данных. Если значение этого параметра задано как ON, все значения сохраняются на отдельных связанных страницах, а 16-байтовый корневой указатель на них хранится в странице данных для строки. Если значение параметра равно OFF, то значения, размер которых меньше 8000 байт, встраиваются в страницу данных для строки, а значения большего размера сохраняются на отдельных связанных страницах. Хотя новые типы данных FILESTREAM и Remote BLOB добавлены для того, чтобы улучшить быстродействие и управление по сравнению со стандартными столбцами varbinary, в некоторых случаях удобно использовать последние (обычно, если размер BLOB-данных в среднем не превышает двухсот пятидесяти килобайт). Microsoft Corporation ©2007 SQL Server 2008. Управление неструктурированными данными при помощи SQL Server 2008. 5 Атрибут FILESTREAM В SQL Server 2008 данные столбца varbinary можно сохранять в локальной файловой системе NTFS, если использовать атрибут FILESTREAM. Хранение данных в файловой системе имеет два преимущества: быстродействие соответствует быстродействию потоковой передачи данных файловой системы; размер BLOB-данных ограничен только размером файловой системы. В то же время управлять данными в столбце можно точно так же, как любыми другими столбцами в SQL Server, поэтому администраторы могут использовать возможности управления и безопасности SQL Server, чтобы объединить управление BLOB-данными и остальными данными в реляционной базе данных, без необходимости управлять данными отдельно в файловой системе. Использование атрибута FILESTREAM при хранении данных в SQL Server также обеспечивает согласованность на уровне данных между данными в реляционной базе данных и данными, физически находящимися в файловой системе. Столбец FILESTREAM ведет себя точно так же, как столбец BLOB, а это означает возможность полной интеграции таких операций, как резервное копирование или восстановление, полной интеграции с моделью безопасности SQL Server и поддержку полной транзакции. Разработчики приложений могут использовать данные FILESTREAM при помощи одной из двух моделей программирования: они могут работать с Transact-SQL для доступа к данным и управления данными точно так же, как со стандартными столбцами BLOB, или с программными интерфейсами (API) для работы с потоками Win32 с транзакционной семантикой Transact-SQL, для обеспечения согласованности. Таким образом, разработчикам будут доступны стандартные вызовы на чтение или запись для работы с BLOB-данными при использовании атрибута FILESTREAM так же, как если бы они работали с файлами в файловой системе. В SQL Server 2008 столбцы FILESTREAM могут хранить данные только в томах локальных дисков, и некоторые функции, такие как прозрачное шифрование и параметры, возвращающие табличное значение, не поддерживаются для этих столбцов. Кроме того, таблицы со столбцами FILESTREAM не могут быть включены в моментальные снимки базы данных или использоваться в сеансе зеркального отображения базы данных. Функция доставки журналов для них поддерживается. Программный интерфейс Remote BLOB Store API Хотя при использовании атрибута FILESTREAM быстродействие и масштабируемость файловой системы сочетаются с управляемостью и согласованностью данных при хранении BLOB-данных в базе данных, существует много сценариев, для которых более эффективным является сохранение BLOB-данных в таких системах, как EMC Centera, Fujitsu Nearline, файловый сервер Microsoft Windows® или в любой другой системе, предназначенной для хранения BLOB-данных. Программный интерфейс удаленного хранения BLOB-данных (Remote BLOB Store API) в SQL Server 2008 упрощает интеграцию решений использования предназначенных для них удаленных хранилищ, с реляционными данными в базах данных. Для этого используется архитектура, основанная на поставщиках, которая позволяет приложениям использовать любое хранилище BLOB-данных без добавления функциональных возможностей или кода, необходимых именно для работы с такими данными. Двумя ключевыми моментами данной архитектуры являются: библиотека клиента: компонент, позволяющий работать с любым поставщиком для работы и с реляционными и с BLOB-данными. Клиентские приложения обращаются к библиотекам клиента и любым применимым Microsoft Corporation ©2007 SQL Server 2008. Управление неструктурированными данными при помощи SQL Server 2008. 6 библиотекам поставщика для добавления, обновления и запроса данных в хранилище BLOB-данных, как и с данными, хранящимися в базе данных; библиотека поставщика: компонент, обычно предоставляемый поставщиками хранилищ BLOB-данных (также может быть разработана на заказ). Библиотека поставщика реализует общий интерфейс и предоставляет доступ к стандартным службам, которые скрывают от пользователя выполнение операций создания, отправки запросов, перечисления, удаления и сборки мусора для этого конкретного хранилища. Программный интерфейс удаленного хранения BLOB-данных является наиболее подходящим в том случае, если BLOB-данные из базы данных и сама база данных сохранены на разных серверах и требуется обеспечить взаимодействие с другими системами. На хранилище BLOB-данных ограничений не накладывается. Поддерживается любая система, предоставляющая поставщика удаленного хранилища BLOB-данных, или для которой оно может быть построено. Так как подробности того, как именно происходит взаимодействие с этим хранилищем, скрыты внутри служб библиотеки поставщика, можно сменить хранилище и при этом ничего не менять в приложениях. Таким образом, разработчики и администраторы получают значительные преимущества при пониженной сложности. Корпорация Майкрософт работает со всеми вендорами в отрасли, тем самым обеспечивая достаточное количество поставщиков хранилищ, с которыми можно работать при помощи программного интерфейса удаленного хранения BLOB-данных. Данный программный интерфейс предоставляет гибкость в управлении реляционными и нереляционными данными. Интерфейс поддерживает согласованность между строками в базе данных и BLOB-данными во внешнем хранилище при помощи ссылок. Например, если к ссылке на BLOB-данные в базе данных была применена операция удаления, из хранилища будут удалены и соответствующие BLOB-данные. Однако использование программного интерфейса удаленного хранения BLOB-данных не дает пользователю того же полного согласования на уровне данных, какое дает сохранение BLOB-данных непосредственно в базе данных, как при использовании столбцов FILESTREAM или varbinary. Сравнение вариантов хранения BLOB-данных Следующая таблица сравнивает различные варианты хранения BLOB-данных в SQL Server 2008. Файловый сервер или хранилище, предназначен ное для BLOBданных Быстрая потоковая передача BLOBданные SQL Server Программн. интерфейс удаленного хранения BLOB-данных Столбцы FILESTREAM В зависимости от хранилища Нет В зависимости от хранилища Да Согласованность на уровне ссылок Нет Да Да Да Согласованность на уровне данных Нет Да Нет Да Microsoft Corporation ©2007 SQL Server 2008. Управление неструктурированными данными при помощи SQL Server 2008. Объединенное управление данными 7 Нет Да Нет Да Использование удаленных файловых серверов Windows Неприм. Нет Да Не в данном выпуске Взаимодействие с внешними хранилищами BLOB-данных Неприм. Нет Да Нет Таблица 1 Сравнение вариантов хранения BLOB-данных Такой диапазон возможностей означает, что SQL Server 2008 предоставляет гибкое решение для хранения неструктурированных данных и, следовательно, наилучшим образом отвечает бизнес-требованиям. Поиск неструктурированных данных в SQL Server 2008 Одним из наиболее распространенных требований к приложениям, использующим нереляционных данные, является полнотекстовый поиск таких данных. Интегрированный полнотекстовый поиск Полнотекстовый поиск поддерживался и более ранними версиями SQL Server, однако они полагались на обработчика полнотекстового поиска внешней службы поиска Windows. При использовании внешней службы возникают следующие сложности: зависимость от внешней службы приводит к большей сложности развертывания и к проблемам с технической поддержкой; возникали проблемы с быстродействием при совместном использовании предикатов полнотекстового поиска и стандартных предикатов SQL. Необходимо было отправить всю полнотекстовую часть поиска обработчику до применения предикатов SQL, и поэтому было невозможно составить оптимизацию для запросов, включающих предикаты полнотекстового поиска. В SQL Server 2008 обработчик полнотекстового поиска полностью интегрирован в систему управления базы данных. Прямая интеграция полнотекстового поиска в ядро базы данных устраняет сложности, возникавшие в предыдущих выпусках, снижает затраты на управление и на развертывание SQL Server и в то же время повышает быстродействие поиска неструктурированных данных. Заключение SQL Server предлагает гибкое решение для хранения и поиска неструктурированных данных. Атрибут FILESTREAM повышает быстродействие при хранении нереляционных BLOB-данных в базе данных вместе с реляционными данными, без ущерба для управления. Если используется хранилище, предназначенное для BLOBданных, то программный интерфейс Remote BLOB Store API помогает объединить BLOB-данные и реляционные данные в базе данных и обеспечивает согласованный программный интерфейс для взаимодействия с этими данными независимо от системы, в которой они хранятся. И в завершение, любое решение для SQL Server 2008, предложенное в данной технической статье, делает более эффективным поиск нереляционных данных и упрощает управление в тех случаях, когда необходимо сохранить и затем использовать большие библиотеки документов. Microsoft Corporation ©2007 SQL Server 2008. Управление неструктурированными данными при помощи SQL Server 2008. 8 Дополнительные сведения: http://www.microsoft.com/sql (на английском языке). Помогла ли вам эта статья? Выскажите свое мнение. Пользуясь шкалой оценок от 1 (плохо) до 5 (отлично), как бы вы оценили эту статью и почему выставляете такую оценку? Например: Вы высоко оцениваете данную статью, так как в ней используются хорошие примеры, отличные снимки экранов, доступный текст или по другой причине? Вы даете данной статье низкую оценку из-за плохих примеров, размытых снимков и непонятного текста? Ваша оценка поможет нам улучшить качество наших статей. Отправить отзыв Microsoft Corporation ©2007