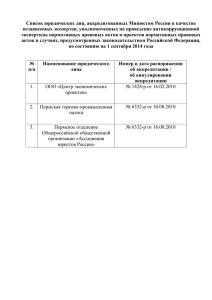
Автоматизированное выявление потенциальных
реклама

Автоматизированное выявление потенциальных коррупциогенных факторов в проектах НПА Романов Д.А., доцент НИУ ВШЭ Васильченко Ю.Л., зав.кафедрой правовой информатики МГЮА Применение методов компьютерной лингвистики для анализа текстов юридической тематики – давнее и популярное направление исследований [1,2]. Юридические тексты отличает высокая степень формализации, строгости изложения и структурированности. Основные направления исследований – формализация и классификация правовых норм, поиск прецедентов, выявление правовых пробелов и коллизий. Несмотря на свою актуальность, проблематика применения методов компьютерной лингвистики как эффективной технологии обработки русскоязычного правового контента для целей законотворчества была долгое время обделена вниманием исследовательского сообщества. Семантический анализ правовых текстов проводился, главным образом, для улучшения качества поиска релевантных документов в справочных правовых системах. Наделение органов государственной власти функциями антикоррупционной экспертизы на фоне роста количества законопроектов, изменений и дополнений в действующее законодательство, недостаточной подготовки экспертов, делает актуальной задачу экспертной поддержки законотворческой деятельности с помощью автоматизированной интеллектуальной юридико-лингвистической обработки текстов проектов нормативных правовых актов (НПА). Основной целью автоматизированной данного исследования юридико-лингвистической являлась обработки разработка текстов алгоритмов нормативных правовых актов при проведении антикоррупционной экспертизы. Постановлением Правительства РФ № 96 от 26.02.2010 утверждена Методика проведения антикоррупционной экспертизы нормативных правовых актов и проектов нормативных правовых актов [3], в которой рекомендуется выявлять одиннадцать коррупциогенных факторов, разделенных на две группы: (а) факторы, устанавливающие для правоприменителя необоснованно широкие пределы усмотрения или возможность необоснованного применения исключений из общих правил (в т.ч. широта дискреционных полномочий, определение компетенции по формуле "вправе", выборочное изменение объема прав и др.); (б) факторы, содержащие неопределенные, трудновыполнимые и (или) обременительные требования к гражданам и организациям (наличие завышенных требований, злоупотребление правом заявителя, юридико-лингвистическая неопределенность – употребление неустоявшихся, двусмысленных терминов и категорий оценочного характера). Отметим, что данная классификация не является окончательной и единственно возможной. Так, критикуется неоправданное сокращение количества коррупциогенных факторов по сравнению с предыдущей редакцией Методики от 2009 года [4], двусмысленность, расплывчатость, отсутствие целеполагания в описании коррупциогенных факторов [5]. Задача автоматизации антикоррупционной экспертизы осложняется как отсутствием однозначного и устоявшегося толкования перечня и формулировок коррупционных факторов, так и сохраняющейся дискуссионностью самого понятия. Для решения прикладных задач в компьютерной лингвистике можно выделить два основных подхода: (а) использование статистических методов и машинного обучения и (б) использование систем, основанных на правилах и шаблонах. Применение методов машинного обучения для автоматизированного выявления потенциальных коррупциогенных факторов осложнено отсутствием достаточного для формирования обучающих выборок количества исходных примеров и образцов (в наличии десятки и сотни примеров при необходимых сотнях тысяч), а также многозначностью и неопределенностью экспертных оценок. Для достижения поставленной цели в данной работе была применена уникальная методика построения и применения контекстнозависимых лексических шаблонов для юридико-лингвистической обработки текста правового акта при проведении правовой экспертизы. Данный подход был отработан ранее на примере задач выявления экспертных компетенций [6] и формализации учебных материалов для студентов юридических вузов [7]. Анализ результатов проводимых экспертами антикоррупционных экспертиз позволил выявить ряд семантических конструкций, характерных для потенциальных коррупциогенных факторов. В частности, были выявлены и использованы для построения лексических шаблонов конструкции, содержащие: явное упоминание потенциального коррупциогенного фактора в наиболее коррупциогенных сферах; категории оценочного характера; определения компетенции по формуле "вправе"; бланкетные нормы; необоснованные исключения из общего порядка. На основе предложенных лексических шаблонов была разработана автоматизированная информационная система для проведения антикоррупционной экспертизы проектов НПА. Данная система стала развитием системы правового мониторинга АИС «Мониторинг», используемой в МВД РФ [8]. На вход системы поступает проект НПА, после чего система c помощью заложенных в нее алгоритмов, настроек и базы действующего законодательства анализирует представленный текст проекта НПА и выделяет фрагменты текста, содержащие потенциальные коррупциогенные формулировки. Эксперт проверяет представленные замечания и либо подтверждает наличие коррупциогенного фактора в проекте НПА, либо удаляет замечание, если коррупциогенный фактор, по его мнению, отсутствует. По результатам проверки система формирует проект отчета о проведении антикоррупционной экспертизы, в который эксперт может внести необходимые уточнения и дополнения. Система не заменяет человека, а помогает ему, сокращает трудозатраты и время проведения экспертизы, снижает риск пропуска коррупуциогенных факторов. По сравнению с использовавшимся ранее подходом, основанном на поиске ключевых слов и словосочетаний, использование лексических шаблонов позволило значительно повысить точность и полноту выделения потенциальных коррупциогеных факторов в проектах НПА. Автоматизированная система должна рассматриваться прежде всего как удобный инструмент, расширяющий и дополняющий возможности человека, берущий на себя трудоемкие рутинные задачи антикоррупционной экспертизы проектов НПА [9]. Литература 1) McCarty, L. Thorne. "Deep semantic interpretations of legal texts." Proceedings of the 11th international conference on Artificial intelligence and law. ACM, 2007. 2) Francesconi, Enrico, et al., eds. Semantic processing of legal texts: Where the language of law meets the law of language. Vol. 6036. Springer, 2010. 3) Постановление Правительства РФ от 26.02.2010 N 96 "Об антикоррупционной экспертизе нормативных правовых актов и проектов нормативных правовых актов". Собрание законодательства РФ. – 2010. – N 10. - Ст. 1084. 4) Епихин В. П. "Роль и место прокуратуры при производстве антикоррупционной экспертизы." Вестник Волгоградского государственного университета. Серия 5: Юриспруденция 1.5-14 (2011). 5) Будатаров С.М. "Коррупциогенные факторы: понятие, виды, проблемы их практического применения." Мониторинг правоприменения, 2 (2013). 6) V.Molokanov, D.Romanov, V.Tsibulsky "Enhanced Algorithms for Enterprise Expert Search System", in: Proc. of International Conference on Graphic and Image Processing (ICGIP 2012). Singapore : SPIE, 2013. Ch. 8768-36. P. 146-150. 7) Васильченко Ю.Л., Романов Д.А. "Анализ и систематизация правовых дефиниций в учебном процессе юридического ВУЗа". Сб. науч. работ ИГП РАН– М.: ИГП РАН – Издательство «Канон+» РООИ «Реабилитация», 2015 – 280 с. 8) Дюков А.В., Зыков А.А., Ищенко Т.Ю., Ковалев Д.А., Романов Д.А., Цибульский В.В., Черников В.В. "Система сбора правовой информации и ее анализа для выявления проблемных вопросов и недостатков нормативного правового регулирования." Патент на полезную модель RUS 115095 23.09.2011. 9) "Антикоррупционная экспертиза проектов нормативных правовых актов: научнопрактическое пособие". Отв. ред.: Ю. А. Тихомиров. М. : Анкил, 2012.