МИНОБРНАУКИ РОССИИ
федеральное государственное бюджетное образовательное учреждение
высшего образования
«Санкт-Петербургский государственный технологический институт
(технический университет)»
Кафедра системного анализа и информационных технологий
В. И. Халимон, Г. А. Мамаева,
А. Ю. Рогов, В. Н. Чепикова
БАЗЫ ДАННЫХ
Учебное пособие
Санкт-Петербург
2017
УДК 681.3.06
Халимон, В.И. Базы данных: учебное пособие / В.И. Халимон,
Г.А. Мамаева, А.Ю. Рогов, В.Н. Чепикова - С-Пб.: СПбГТИ(ТУ), 2017. – 118 с.
Илл. 60, библиография – 13 наим.
В учебном пособии изложены основы теории баз данных (БД), архитектура БД, базовые подходы к проектированию реляционных БД, CASEсредства. Описывается технология разработки персональных БД с помощью
СУБД Microsoft Access. Рассматриваются базисные средства манипулирования данными: элементы реляционной алгебры и реляционного исчисления.
Изложены основы использования языка структурированных запросов TransactSQL, реализованного в Microsoft SQL Server, а также основные функции и типовая организация современных систем управления базами данных.
Пособие предназначено для бакалавров очной формы обучения для направления подготовки 27.03.03 – системный анализ и управление, соответствует рабочей программе дисциплины «Базы данных». Учебное пособие формирует у студентов следующие общепрофессиональные: ОПК-2 и профессиональные: ПК-7, ПК-9 компетенции. Учебное пособие может быть полезно для
студентов заочной формы обучения, магистров, аспирантов, а также может
быть использовано как дополнительный материал к лекционному курсу «Проектирование информационных систем».
Рецензенты:
1 Санкт-Петербургский государственный университет технологии и дизайна В.И. Пименов, д-р техн. наук, профессор,
зав. кафедрой прикладной информатики
2 Д.А. Смирнова, к.т.н., доцент кафедры ресурсосберегающих технологий, СПбТИ(ТУ)
Издание подготовлено в рамках выполнения государственного задания по
оказанию образовательных услуг Минобрнауки России
Утверждено на заседании учебно-методической комиссии факультета информационных технологий и управления 12 мая 2016 г.
Рекомендовано к изданию РИС СПбГТИ(ТУ)
2
СОДЕРЖАНИЕ
ВВЕДЕНИЕ............................................................................................................. 5
1 КОНЦЕПЦИЯ БАЗ ДАННЫХ .......................................................................... 6
1.1 Базы данных и информационные системы. Основные понятия ....... 6
1.2 Централизованные и распределенные базы данных ............................ 8
1.3 Классификация БД по способу доступа к данным ................................ 9
1.4 Модели данных ........................................................................................... 10
1.4.1 Трехуровневая архитектура базы данных .......................................... 10
1.4.2 Классификация моделей данных согласно архитектуре ANSI-SPARC 12
1.4.3 Модели представления данных, поддерживаемые СУБД ................. 15
2 РЕЛЯЦИОННАЯ МОДЕЛЬ ДАННЫХ ......................................................... 16
2.1 Основные понятия реляционной модели данных ............................... 16
2.2 Фундаментальные свойства отношений. Понятие первичного
ключа .................................................................................................................. 19
2.3 Виды связей между таблицами ............................................................... 22
2.4 Нормализация отношений ....................................................................... 23
3 ПРОЕКТИРОВАНИЕ РЕЛЯЦИОННЫХ БАЗ ДАННЫХ .......................... 26
3.1 Основные задачи и этапы проектирования ......................................... 26
3.2 Методы проектирования реляционных баз данных .......................... 27
3.3 Проектирование базы данных «Университет» .................................... 29
3.3.1 Инфологическое проектирование ........................................................ 29
3.3.2 Даталогическое проектирование ........................................................ 31
3.3.3 Физическое проектирование................................................................. 33
4 АВТОМАТИЗАЦИЯ ПРОЕКТИРОВАНИЯ БАЗ ДАННЫХ ......................... 33
4.1 Общая характеристика CASE-средств .................................................. 33
4.2 Семантическая модель данных ............................................................... 35
4.3 Структурная схема автоматизированного проектирования базы
данных................................................................................................................. 43
5 БАЗИСНЫЕСРЕДСТВА МАНИПУЛИРОВАНИЯ ДАННЫМИ ................. 44
5.1 Эквивалентность механизмов реляционной алгебры и
реляционного исчисления .............................................................................. 44
5.2 Элементы реляционной алгебры ............................................................ 45
5.3 Элементы реляционного исчисления .................................................... 51
6 СИСТЕМА УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ MS ACCESS ................. 52
3
6.1 Общая характеристика СУБД MS Access ............................................. 52
6.2 Инструментальные средства СУБД Access .......................................... 53
6.3 Система доступа к данным ...................................................................... 53
6.4 Поддержка технологий корпоративных сетей ..................................... 54
6.4.1 Многопользовательская база данных Access ...................................... 54
6.4.2 Работа Access с базой данных SQL Server .......................................... 55
6.4.3 Интернет-технологии .......................................................................... 56
6.5 Схема данных.............................................................................................. 56
6.6 Объекты Access ........................................................................................... 57
6.7 Сводные таблицы и сводные диаграммы ............................................. 59
6.8 Размещение базы данных ......................................................................... 60
7 СОЗДНИЕ БАЗЫ ДАННЫХ В СУБД MS ACCESS 2010 ............................ 62
7.1 Начало работы с Access. Интерфейс пользователя ............................. 62
7.2 Основные этапы разработки базы данных в среде MS Access ......... 66
7.2.1 Описание предметной области............................................................ 66
7.2.2 Создание таблиц .................................................................................... 68
7.2.3 Создание схемы данных ........................................................................ 71
7.2.4 Разработка запросов к базе данных .................................................... 73
7.2.5 Конструирование экранных форм для работы с данными ............... 78
7.2.6 Конструирование отчетов ................................................................... 83
7.2.7 Средства макропрограммирования в MS Access ................................ 86
7.2.8 Разработка программных приложений для MS Access ..................... 87
7.3. Организация защиты данных в СУБД MS Access ............................. 89
8 ОСНОВЫ ИСПОЛЬЗОВАНИЯ ЯЗЫКА СТРУКТУРИРОВАННЫХ
ЗАПРОСОВ............................................................................................................ 92
8.1 Структурированный язык запросов Transact-SQL ............................ 92
8.1 Команды языка определения данных.................................................... 97
8.2 Команды языка манипулирования данными .................................... 100
9 ОСНОВНЫЕ ФУНКЦИИ И ТИПОВАЯ ОРГАНИЗАЦИЯ
СОВРЕМЕННЫХ СИСТЕМ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ .......... 109
9.1. Основные функции систем управления базами данных ................ 109
9.2. Типовая организация систем управления базами данных ............ 112
9.3. Архитектуры приложений, использующих базы данных .............. 113
ЛИТЕРАТУРА .................................................................................................... 116
4
ВВЕДЕНИЕ
Применение информационных технологий в настоящее время невозможно без рациональной организации информации и обеспечения эффективного доступа к ней пользователей.
Одним из определяющих факторов успеха функционирования систем
управления, обеспечивающих требуемый уровень качества процессов, продуктов, услуг и результатов деятельности предприятий, является использование современных технологий баз данных. Актуальным становится требование подготовки специалистов, обладающих достаточными знаниями и навыками использования современных информационных технологий в области
баз данных. Цель учебного пособия – дать студентам необходимые знания по
теоретическим основам баз данных, проектированию баз данных, использованию языков манипулирования данными при работе с базами данных.
Учебное пособие соответствуют содержанию дисциплины «Базы данных» федеральных государственных образовательных стандартов по направлению подготовки бакалавров 27.03.03 «Системный анализ и управление».
Изложенные в учебном пособии темы соответствуют рабочей программе
дисциплины и ГОС.
Авторы ставили перед собой задачу не только изложить материал по
теории баз данных, но и дать примеры для грамотного использования полученных знаний. Рассмотренный в пособии пример позволит студентам освоить технологию проектирования и создания базы данных, язык запросов
SQL.
При описании форматов команд языка SQL приняты следующие обозначения:
[ ] – необязательный элемент синтаксиса; { } – обязательный элемент
синтаксиса;
| – разделяет элементы синтаксиса внутри квадратных и фигурных скобок;
[,…] – предшествующий элемент синтаксиса может быть повторен несколько раз (элементы разделяются запятой).
5
1 КОНЦЕПЦИЯ БАЗ ДАННЫХ
1.1 Базы данных и информационные системы. Основные понятия
В основе решения многих задач лежит обработка информации. Для облегчения обработки информации создаются информационные системы (ИС).
Автоматизированными называют ИС, в которых применяют технические
средства, в частности ЭВМ.
Информационная система (ИС) — это система, предназначенная для
хранения, поиска и обработки информации, и соответствующие организационные ресурсы (человеческие, технические, финансовые и т. д.), которые
обеспечивают и распространяют информацию.
Информационная система предназначена для своевременного обеспечения надлежащих людей надлежащей информацией, то есть для удовлетворения конкретных информационных потребностей в рамках определенной
предметной области.
Под предметной областью информационной системы понимается совокупность реальных процессов и объектов (сущностей) в некоторой области
деятельности для организации управления и, в конечном счете, автоматизации, например, предприятие, вуз и т.д.
По области применения ИС можно разделить на системы, используемые в производстве, образовании, здравоохранении, науке, военном деле, социальной сфере, торговле и других отраслях. По целевой функции ИС можно
условно разделить на следующие основные категории: управляющие, информационно-справочные, поддержки принятия решений.
Заметим, что иногда используется более узкая трактовка понятия ИС
как совокупности аппаратно-программных средств, задействованных для решения некоторой прикладной задачи. В организации, например, могут существовать информационные системы, на которых соответственно возложены
следующие задачи: учет кадров и материально-технических средств, расчет с
поставщиками и заказчиками, бухгалтерский учет и т. п.
Неотъемлемой частью любой информационной системы является база
данных.
База данных (БД)–это совокупность сведений о конкретных объектах
реального мира в какой-либо предметной области.
Создавая базу данных, пользователь стремится упорядочить информацию по различным признакам и быстро извлекать данные, при необходимости делая выборку с произвольным сочетанием признаков. Пользователями
БД могут быть различные прикладные программы, программные комплексы,
а также специалисты предметной области, выступающие в роли потребителей и (или) источников данных, называемые конечными пользователями.
Однако для быстрого нахождения требуемой информации необходимо,
6
чтобы хранящиеся данные были структурированы.
Структурирование – это соглашение о способах представления данных.
Неструктурированными называют, например, данные, записанные в
текстовом файле (рис. 1).
Зачетная книжка № 1212, группа № 1005, Иван Петрович Сергеев, 12 декабря 1971 г. р., обучается на
коммерческой основе. Зач. кн. № 1232, гр. № 1006,
Михайлов Степан Степанович, 14.10.71 г. р.,
Рисунок 1 – Пример неструктурированных данных
Чтобы автоматизировать поиск и систематизировать эти данные, необходимо выработать определенные соглашения о способах представления
данных. Так, например, дату рождения каждого студента нужно записывать
одинаково в соответствии с заданным форматом. Эти же замечания справедливы и для других элементов данных.
После проведения несложной структуризации информации она будет
выглядеть, например, так, как показано на рис. 2.
Номер
зачетной
книжки
1212
1232
Номер
Фамилия
Имя
1005
1006
Сергеев
Иван
Михайлов Степан
Отчество
Дата
Коммеррождения ческий
Петрович
12.12.71
Степанович 14.10.71
Да
Да
Рисунок 2 –Пример структурированных данных
Таким образом, дадим более точное определение базе данных.
База данных представляет собой поименованную совокупность структурированных данных, хранимых в памяти вычислительной системы и отображающих состояние объектов и их взаимосвязей в рассматриваемой предметной области.
С точки зрения функционирования любой информационной системы
БД должна удовлетворять следующим общесистемным требованиям.
Данные, хранящиеся в системе, отражают часть реального мира, объекты которого находятся в сложном взаимодействии между собой. Системность, взаимосвязанность этих объектов приводит к взаимосвязанности отражающих их информационных объектов (элементов информации ). Для того
чтобы обеспечить непротиворечивость отображения объектов реального мира, БД должна представлять собой некоторое единое взаимоувязанное целое.
Поэтому важнейшим требованием к БД является обеспечение адекватности
отображения предметной области.
Информационные потребности конечных пользователей, как правило,
7
пересекаются. Создание же локальных массивов, кроме случаев, когда в этом
есть реальная необходимость, приводит к значительному дублированию информации и, как следствие, к повышению возможности нарушения целостности и непротиворечивости данных. Поэтому БД, как единое информационное поле, должна обеспечивать многократное обращение к одним и тем же
данным, т. е. возможность взаимодействия с пользователями разных категорий и в различных режимах.
Следующим требованием, в известной мере дополняющим предыдущее, является требование нахождения в БД минимально необходимых сведений о предметной области: ни минимальных, а именно минимально необходимых сведений. Данные должны быть организованы таким образом , чтобы
имелась возможность получения на их основе дополнительной информации,
которая непосредственно не содержится в БД, но которую можно получить,
использую средства манипулирования данными.
Наконец, последние из общесистемных требований заключается в том,
что любая БД потенциально должна обладать способностью развития (эволюции), т.е. обладать в этом смысле открытостью. Очевидно, что объекты
предметной области находятся в движении, т. е. подвержены различного рода изменениям, что, естественно, может придавать им новые важные свойства. Вследствие этого, и сама предметная область не статична. Поэтому в БД
должно своевременно отражаться любое существенное изменение структуры
свойств информационных объектов.
В современной технологии БД предполагается, что создание БД, ее
поддержка и обеспечение доступа пользователей к ней осуществляется централизованно с помощью специального инструментария – систем управления
базами данных.
Система управления базами данных (СУБД)— этот совокупность
программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
Для работы с БД зачастую достаточно средств СУБД. Однако если требуется обеспечить удобство работы с БД неквалифицированным пользователям или интерфейс СУБД не устраивает пользователей, то могут быть разработаны приложения. Их создание требует программирования.
Приложение представляет собой программу или комплекс программ,
обеспечивающих автоматизацию решения какой-либо прикладной задачи.
Приложения могут создаваться в среде или вне среды СУБД — с помощью системы программирования, использующей средства доступа к БД, к
примеру, Delphi или С++ Вuildег. Приложения, разработанные в среде СУБД,
часто называют приложениями СУБД, а приложения, разработанные вне
СУБД, — внешними приложениями.
1.2 Централизованные и распределенные базы данных
С появлением и развитием корпоративных и иных сетей появилась
8
возможность организации доступа к одним и тем же данным из различных
структурных подразделений предприятия или из других регионов. При этом
разработаны два вида баз данных — централизованные и распределенные.
Централизованная база данных характеризуется тем, что полностью
находится на центральном компьютере (сервере), к которому пользователи
(клиенты) обращаются за информацией с помощью своих компьютеров.
Управление базой данных (ее корректировка и прочие процедуры, поддерживающие ее целостность, безопасность и др.) осуществляется централизованно.
Недостатки централизованной БД: необходимость передачи большого
потока данных, низкая надежность и низкая производительность.
Преимущества: минимальные затраты на корректировку.
Для снижения остроты перечисленных недостатков создают распределенные базы данных.
Распределенная база данных состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети.
Главный критерий распределения данных в сети состоит в следующем:
данные должны находиться там, где существует наибольшая частота обращения к ним.
Фактически распределенная БД есть виртуальный объект, составные
части которого хранятся в разных узлах сети. Для пользователя они находятся в одной логической модели базы данных.
По технологии обработки данных базы данных подразделяются на централизованные и распределенные.
1.3 Классификация БД по способу доступа к данным
Классификация баз данных по способу доступа предполагают архитектуры (рис. 3):
файл-сервер;
клиент-сервер.
9
Рисунок 3 –Архитектуры БД «Файл-сервер» и «Клиент-сервер»
Файл-сервер. Такая архитектура предполагает выделение одной из машин сети в качестве центральной (сервер файлов ). На такой машине хранится совместно используемая централизованная БД. Все другие машины сети
выполняют функции рабочих станций, с помощью которых поддерживается
доступ пользователей системы к централизованной БД. Файлы БД в соответствии с пользовательскими запросами передаются на рабочие станции, где в
основном и производится обработка. Очевидно, что при большой интенсивности доступа к одним и тем же данным производительность такой системы
падает.
Применение архитектуры «файл-сервер» привлекает своей простотой,
удобством использования и доступностью. Она представляет интерес для малых рабочих групп и используется и в информационных системах масштаба
небольшого предприятия.
Клиент-сервер. В этой концепции подразумевается, что помимо хранения централизованной БД центральная машина (сервер БД) должна обеспечивать выполнение основного объема обработки данных. Клиентское приложение формирует запросы к серверу базы данных, как правило, в виде инструкций языка SQL. Сервер извлекает из базы запрошенные данные и передает на компьютер клиента. Главное достоинство такого подхода — значительно меньший объем передаваемых данных.
Совершенно очевидно, что перенос программ управления данными с рабочих станций на сервер способствует высвобождению ресурсов рабочих
станций, предоставляет возможность увеличить число частных, локально решаемых задач. Данная архитектура позволяет также централизовать ряд самых
важных функций управления данными, такие, как защита информации баз
данных, обеспечение целостности данных, управление совместным использованием ресурсов.
1.4 Модели данных
1.4.1 Трехуровневая архитектура базы данных
Современная технология баз данных основана на концепции трехуровневой архитектуры СУБД, сформулированной американским комитетом по
стандартизации SPARC (Standards Planning and Requirements Committee)
Американского национального института стандартов ANSI (American National Standards Institute). Архитектура включает 3 уровня описания данных (концептуальный, внешний и внутренний), различающиеся степенью абстракции
(рис.4).
1. На внешнем (пользовательском) уровне описываются различные
подмножества элементов концептуального уровня для представлений данных различным пользовательским программам. Каждый пользователь получает в свое распоряжение часть представлений о данных, но полная концеп10
ция скрыта. Например, система распределения работ использует сведения о
квалификации сотрудника, но ее не интересуют сведения об окладе, домашнем адресе и телефоне сотрудника, и наоборот, именно эти сведения используются в подсистеме отдела кадров. Отделение внешнего уровня от
концептуального обеспечивает логическую независимость данных.
Рисунок 4 – Трехуровневая модель СУБД, предложенная ANSI-SPARC
2. Концептуальный уровень лежит в основе архитектурыANSISPARC. Он описывает объекты и их взаимосвязи без указания способов их
физического хранения, объединяя данные, используемые всеми приложениями, работающими с данной БД. Фактически концептуальный уровень
отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных.
3. Внутренний (физический) уровень — позволяет скрыть подробности физического хранения данных (носители, файлы, таблицы, триггеры)
от концептуального уровня. Он содержит детальное описание структур данных и физической организации файлов с данными, описание вспомогательных структур (индексов), используемых для ускорения поиска, сведения о
распределении дискового пространства для хранения данных и индексов,
сведения о сжатии данных и выбранных методах их шифрования и т.д.
Отделение внутреннего уровня от концептуального обеспечивает так
называемую физическую независимость данных.
Эта архитектура позволяет обеспечить логическую (между уровнями 1
и 2) и физическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с
11
этой же базой данных. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной базой
данных.
Как показывает изучение трехуровневой архитектуры БД, концептуальная схема является самым важным уровнем представления базы данных.
Она поддерживает все внешние представления, а сама поддерживается средствами внутренней схемы. Внутренняя схема является всего лишь физическим воплощением концептуальной схемы. Именно концептуальная схема
призвана быть полным и точным представлением требований к данным в
рамках некоторой предметной области.
1.4.2 Классификация моделей данных согласно архитектуре ANSISPARC
Одними из основополагающих в концепции баз данных являются
обобщенные категории "данные" и "модель данных".
Понятие "данные" в концепции баз данных — это набор конкретных
значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы. Примеры данных: Петров Николай Степанович, $30
и т.д.
Данные не обладают определенной структурой, данные становятся информацией тогда, когда пользователь задает им определенную структуру, то
есть осознает их смысловое содержание. Поэтому центральным понятием в
области баз данных является понятие модели. Не существует однозначного
определения этого термина, у разных авторов эта абстракция определяется с
некоторыми различиями, но, тем не менее, можно выделить нечто общее в
этих определениях.
Модель данных – это некоторая абстракция, которая, будучи приложенной к конкретным данным, позволяет пользователям и разработчикам
трактовать их уже как информацию, то есть сведения, содержащие не только
данные, но и взаимосвязь между ними.
На рис. 5 и 6представлена классификация моделей данных в соответствии с трехуровневой архитектурой, предложенной предложенная ANSISPARC. Так, модели данных, обозначенные на рисунках как физические, соответствуют первому (нижнему) уровню архитектуры ANSI-SPARC, даталогические модели можно отнести ко второму, внутреннему уровню архитектуры, а инфологические модели соответствуют концептуальному уровню архитектуры, изображенной на рис. 4.
12
Рисунок 5 – Классификация моделей данных
Рисунок 6 – Развернутая классификация моделей данных
13
Инфологическая (информационно-логическая)или семантическая
модель данных – это модель отображения предметной области в виде информационных объектов и связей между ними. При этом под информационным объектом понимается абстрактные объект, информацию о свойствах которого предполагается хранить в БД. Такими информационными объектами,
например, могут быть: СТУДЕНТ, ГРУППА, ФАКУЛЬТЕТ и др.
Такая модель создаѐтся без ориентации на какую-либо конкретную
СУБД. Термины «инфологическая модель», «семантическая модель» и «концептуальная модель» являются синонимами. Кроме того, в этом контексте
равноправно могут использоваться слова «модель базы данных» и «модель
предметной области» (например, «концептуальная модель базы данных» и
«концептуальная модель предметной области»), поскольку такая модель является как образом реальности, так и образом проектируемой базы данных
для этой реальности.
Конкретный вид и содержание концептуальной модели базы данных
определяется выбранным для этого формальным аппаратом. Обычно используются графические нотации, подобные ER-диаграммам.
Чаще всего концептуальная модель базы данных включает в себя:
описание информационных объектов или понятий предметной области и связей между ними;
описание ограничений целостности, т.е. требований к допустимым
значениям данных и к связям между ними.
Инфологическая модель строится безотносительно к физической реализации БД. Следовательно, она является наиболее стабильной среди всех
моделей, показанных на рис. 5, 6. Поэтому к этой модели предъявляются
следующие требования:
адекватное отображение предметной области;
полнота модели (модель должна содержать информацию, достаточную для создания БД);
однозначность модели.
Даталогическое или логическая модель данных – это модель, ориентированная на реализацию БД в конкретной СУБД, т.е. это инфологическая модель, трансформированная с учетом требований и ограничений конкретной СУБД (тип модели данных, поддерживаемой СУБД, формат данных,
возможности по обеспечению целостности данных и т.д.).
Логическая модель отражает логические связи между элементами данных вне зависимости от их содержания и среды хранения.
Логическая модель данных может быть иерархической, сетевой или
реляционной.
Физическая модель данных используется для привязки даталогической модели к среде хранения в данной операционной среде. Эта модель определяет используемые запоминающие устройства, способы расположения
элементов данных в памяти, способы физической реализации логических от14
ношений между элементами данных. Модель физического уровня строится с
учетом ограничений СУБД и операционной системы.
Модель каждого последующего уровня строится на основе фиксированных характеристик моделей предшествующих уровней. Модели имеют
разный уровень абстракции.
Выделение моделей разных уровней абстракции позволяет:
разделить сложный процесс отображения «предметная область –
база данных» на несколько итеративных более простых отображений;
обеспечить специализацию разработчиков баз данных; возможность
работать разным категориям пользователей с моделью соответствующего
уровня;
предоставить возможность активного и конструктивного участия в
разработке баз данных лицам, не имеющим профессиональных навыков в области обработки данных;
создать предпосылки автоматизации проектирования баз данных
путем формализованного перехода с одного уровня моделей на другой.
1.4.3 Модели представления данных, поддерживаемые СУБД
Логическую структуру данных, хранимых в базе, называют моделью
представления данных. Вид модели и используемые в ней типы структур
данных отражают концепцию логической организации данных и их обработки, используемую в СУБД. Вид модели данных, поддерживаемой СУБД, является одним из важнейших признаков классификации СУБД — иерархические, сетевые, реляционные, объектно-ориентированные, семантические
и др.
Иерархическая модель представляет совокупность элементов, связанных
между собой по принципу «дерева» (связного ациклического графа) (рис. 7).
Рисунок 7 – Иерархическая модель данных
Отличительными признаками иерархической структуры являются:
каждый элемент является либо управляющим, либо подчиненным, либо
и тем и другим одновременно;
существует один и только один только управляющий элемент;
существует, по крайней мере, один только подчиненный элемент;
любой подчиненный элемент непосредственно взаимодействует с од15
ним и только одним управляющим элементом;
связи между элементами на одном уровне отсутствуют;
к каждому элементу существует только один путь от корневого элемента.
Сетевая модель позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа (рис. 8).
Рисунок 8 –Сетевая модель данных
Реляционная
модель
получила
название
от
английского
терминаrelation(отношение).Ее предложил в70-х годах прошлого века известный американский специалист фирмы IBM Эдгар Кодд.
Реляционные модели характеризуются простотой структуры данных,
удобным для пользователя табличным представлением и возможностью использования формального аппарата реляционной алгебры и реляционного исчисления.
Реляционная модель ориентирована на представление данных в виде
плоских (двумерных) таблиц (отношений).
Объектно-ориентированная модель представляет собой синтез сетевой и реляционной моделей. Она ориентирована на использование методов
объектно-ориентрованного программирования, в котором существенными являются понятия инкапсуляции, наследования и полиморфизма.
Семантическая модель данных ориентирована на отражение семантики (смысла) данных и их взаимодействия.
Ключевыми
понятиями
семантической
модели
являются
сущность(Entity), атрибут (Attribute) и связь (Relationship).
Семантическая модель данных используется в настоящее время, как
правило, на начальных стадиях создания информационных систем вообще и
их баз данных в частности. Поэтому именно эта модель реализована в большинстве CASE-средств разработки информационных систем.
2 РЕЛЯЦИОННАЯ МОДЕЛЬ ДАННЫХ
2.1 Основные понятия реляционной модели данных
Реляционная модель данных (РМД) некоторой предметной области
представляет собой набор отношений, изменяющихся во времени. При соз16
дании информационной системы совокупность отношений позволяет хранить
данные об объектах предметной области и моделировать связи между ними.
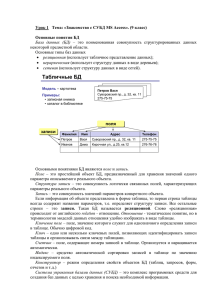
Элементы РМД и формы их представления приведены в табл. 1.
Таблица 1 – Элементы реляционной модели
Элемент реляционной
Форма представления
модели
Сущность
Описание свойств объекта
Отношение
Таблица
Кортеж
Строка таблицы
Строка заголовков столбцов таблицы
Схема отношения
(заголовок таблицы)
Атрибут
Заголовок столбца таблицы
Значение атрибута
Значение поля в записи
Множество допустимых значений атрибуДомен
та
Первичный ключ
Один или несколько атрибутов
Тип данных
Тип значений элементов таблицы
Сущность есть объект любой природы, данные о котором хранятся в
базе данных. Данные о сущности хранятся в отношении.
Отношение является важнейшим понятием и представляет собой двумерную таблицу, содержащую некоторые данные.
На рис. 8 приведен пример представления отношения СОТРУДНИК.
Атрибуты представляют собой свойства, характеризующие сущность.
В структуре таблицы каждый атрибут именуется, и ему соответствует заголовок некоторого столбца таблицы.
Формально, если переставить атрибуты в отношении, то получается
новое отношение. Однако в реляционных БД перестановка атрибутов не приводит к образованию нового отношения.
Схема отношения (заголовок отношения) представляет собой список
имен атрибутов. Например, для отношения, приведенного на рисунке 8 схема
отношения имеет вид: СОТРУДНИК(ФИО, Отдел, Должность, Д_Рождения).
Множество собственно кортежей отношения часто называют содержимым
(телом) отношения.
Схема отношения – это именованное множество пар {имя атрибута,
имя домена (или типа данных, если понятие домена не поддерживается)}.
Кортеж, соответствующий данной схеме отношения, – это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого
имени атрибута, принадлежащего схеме отношения.
17
«Значение» является допустимым значением домена данного атрибута.
Отношение – это множество кортежей, соответствующих одной
схеме отношения.
Отношение СОТРУДНИК содержит 3 кортежа. Кортеж рассматриваемого отношения состоит из 4 атрибутов, каждый из которых выбирается из
соответствующего домена. Каждому кортежу соответствует строка таблицы
(рис. 9).
Рисунок 9 – Представление отношения СОТРУДНИК
В общем случае порядок кортежей в отношении, как и в любом множестве, не определен. Однако в реляционных СУБД для удобства кортежи все
же упорядочивают. Чаще всего для этого выбирают некоторый атрибут, по
которому система автоматически сортирует кортежи по возрастанию или
убыванию. Если пользователь не назначает атрибута упорядочения, система
автоматически присваивает номер кортежам в порядке их ввода.
Домен представляет собой множество всех возможных значений определенного атрибута отношения. Отношение СОТРУДНИК включает 4 домена. Домен 1 содержит фамилии всех сотрудников, домен 2 — номера всех отделов фирмы, домен 3 — названия всех должностей, домен 4 — даты рождения всех сотрудников. Каждый домен образует значения одного типа данных,
например, в данном случае, числовые или символьные.
Математически отношение можно описать следующим образом. Пусть
даны n множеств D1, D2, D3,..., Dn, тогда отношение R есть множество упорядоченных кортежей <dl, d2, d3 ,..., dn>, где dk∈Dk, dk —атрибут, a Dk —
домен отношения R.
Обычным интуитивным представлением отношения является таблица,
заголовком которой является схема отношения, а строками – кортежи отношения В этом случае имена атрибутов именуют столбцы этой таблицы. Поэтому иногда говорят «столбец таблицы», имея в виду «атрибут отношения».
Реляционная база данных – это набор отношений, имена которых
совпадают с именами схем отношений в схеме БД.
18
Как видно, основные структурные понятия реляционной модели данных (если не считать понятия домена) имеют очень простую интуитивную
интерпретацию, хотя в теории реляционных БД все они определяются абсолютно формально и точно.
2.2 Фундаментальные свойства отношений. Понятие первичного
ключа
Свойства реляционных отношений базируются на общей теории множеств. При этом понятие множества будем считать первоначальным и интуитивно ясным.
Множество состоит из элементов и определяется своими элементами.
Существенными при этом являются следующие обозначения и операции над
множествами.
Основные
обозначения:
Множество: А={а1, а2, ..., аn}, аi∈А;
Множество А, состоящее из элементов а, удовлетворяющих
условию Р: А={а| а Р};
Пустое множество: ∅;
А является подмножеством В: А ⊂ В;
А не является подмножеством В: А ⊄ В;
Множества А и В совпадают: А=В.
Объединение: А ∪ В = {а| а∈ А∨ а ∈В}
Пересечение: А ∩ В = {а| а∈ А∧ а ∈В}
Разность: А \ В = {а| а∈ А∧ а ∉ В}
Декартово произведение: А В = {(а, в): а ∈ А ∧ b ∈В }
Бинарным отношением называется всякое подмножество
С = А В, причем аRв, а ∈ А ∧ b ∈ В (R– символ отношения)
6) N – арное отношение по аналогии, где Y = А В ... С
Основные
операции:
1)
2)
3)
4)
5)
Свойства
отношений:
1)
2)
3)
4)
5)
6)
7)
Рефлексивность:∀ а ∈ Аа Rа
Антирефлексивность: условие рефлексивности не выполняется
Симметричность: ∀аi∈А∧ ∀аj∈Ааi Raj аjRai
Антисимметричность: условие симметричности не выполняется
Тождественность: ∀аi∈А∧ ∀аj∈ А аiRaj аj= ai
Транзитивность: ∃аi∈А∧ ∃аj∈А∧ ∃аk∈А аiRaj ∧ аjRak аiRak
Полнота: ∀(аi, аj) всегда выполняется аiRaj∨ аjRai
С учетом введенных понятий определяются свойства реляционных отношений.
1. Эквивалентность кортежей
Любая схема отношения есть отношение эквивалентности на множестве своих атрибутов.
Следовательно, кортежи одного отношения эквивалентны (подобны).
19
2. Отсутствие кортежей-дубликатов
То свойство, что отношения не содержат кортежей-дубликатов, следует
из определения отношения как множества кортежей.
В классической теории множеств каждое множество, по определению, состоит из различных элементов.
Из этого свойства вытекает наличие у каждого отношения, так называемого, первичного ключа – набора атрибутов, значения которых однозначно определяют кортеж отношения.
Понятие первичного ключа является исключительно важным в связи с
понятием целостности баз данных. Первичный ключ, является одним из основных видов ограничений в базе данных. Он предназначен для однозначной
идентификации записи в таблице, и должен быть уникальным
Первичным ключом (ключом отношения, ключевым атрибутом)называется атрибут отношения, однозначно идентифицирующий каждый из его кортежей.
Первичные ключи находятся в таблицах, которые принято называть
родительскими. Например, в отношении СОТРУДНИК(ФИО, Отдел, Должность, Д_Рождения) первичным ключом является атрибут «ФИО». Ключ может быть составным (сложным),то есть состоять из нескольких атрибутов.
Ключи обычно используют для достижения следующих целей:
1) исключения дублирования значений в ключевых атрибутах (остальные атрибуты в расчет не принимаются);
2) упорядочения кортежей;
3) ускорения работы с кортежами отношения;
4) организации связывания таблиц (подраздел 2.3).
Пусть в отношении R1 имеется неключевой атрибут А, значения которого являются значениями ключевого атрибута В другого отношения R2. Тогда
говорят, что атрибут А отношения R1 есть внешний ключ.
Внешний ключ – это столбец или набор столбцов в дочерней таблице,
который в точности соответствует столбцу или набору столбцов, определенных в родительской таблице как первичный (или уникальный) ключ, и ссылается на них.
С помощью внешних ключей устанавливаются связи между отношениями. Например, имеются два отношения СТУДЕНТ(ФИО, Группа, Специальность) и ПРЕДМЕТ(Назв.Пр, Часы), которые связаны отношением СТУДЕНТ_ПРЕДМЕТ(ФИО, Назв.Пр, Оценка) (рис. 10). В связующем отношении
атрибуты ФИО и Назв.Пр образуют составной ключ. Эти атрибуты представляют собой внешние ключи, являющиеся первичными ключами других отношений.
20
Рисунок 10 – Связь отношений
Реляционная модель накладывает на внешние ключи ограничение для
обеспечения целостности данных, называемое ссылочной целостностью. Это
означает, что каждому значению внешнего ключа должны соответствовать
строки в связываемых отношениях.
Поскольку не всякой таблице можно поставить в соответствие отношение, приведем условия, выполнение которых позволяет таблицу считать отношением.
1. Все строки таблицы должны быть уникальны, то есть не может быть
строк с одинаковыми первичными ключами.
2. Имена столбцов таблицы должны быть различны, а значения их простыми, то есть недопустима группа значений в одном столбце одной
строки.
3. Все строки одной таблицы должны иметь одну структуру, соответствующую именам и типам столбцов.
4. Порядок размещения строк в таблице может быть произвольным.
В общем случае можно считать, что БД включает одну или несколько
таблиц, объединенных смысловым содержанием, а также процедурами контроля целостности и обработки информации в интересах решения некоторой
прикладной задачи. Например, при использовании СУБД MicrosoftAccess в
файле БД наряду с таблицами хранятся и другие объекты базы: запросы, отчеты, формы, макросы и модули.
К отношениям можно применять систему операций, позволяющую получать одни отношения из других. Например, результатом запроса к реляционной БД может быть новое отношение, вычисленное на основе имеющихся
отношений.
В таблицах БД должны сохраняться все данные, необходимые для решения задач предметной области. Причем каждый элемент данных должен
храниться в базе только в одном экземпляре. Для создания таблиц, соответствующих реляционной модели данных, используется процесс, называемый
нормализацией данных. Нормализация — это процесс, который позволяет
получить таблицы без повторяющихся данных. Минимальное дублирование
данных в реляционной базе обеспечивает высокую эффективность поддержания БД в актуальном и непротиворечивом состоянии, однократный ввод и
корректировку данных.
21
2.3 Виды связей между таблицами
Между двумя или более таблицами базы данных могут существовать
отношения подчиненности, которые определяют, что для каждой записи
главной таблицы (родительской) возможно наличие одной или нескольких
записей в подчиненной таблице (дочерней).
В нормализованной реляционной БД выделяют три разновидности связи между таблицами:
1) «один-ко-многим» (1:М);
2) «один-к-одному»(1:1);
3) «многие-ко-многим» (М:М).
Отношение «один-ко-многим» имеет место, когда одной записи родительской таблицы может соответствовать несколько записей дочерней. Связь
"один-ко-многим" иногда называют связью "многие-к-одному". И в том, и в
другом случае сущность связи между таблицами остается неизменной. Связь
"один-ко-многим" является самой распространенной для реляционных БД.
На рис. 11 показаны две таблицы со списком покупателей и перечнем
заключенных договоров, которые находятся в отношении типа 1: M и логически связаны с помощью общего поля (столбца) Код покупателя — ключа
связи. Это поле является уникальным ключом в главной таблице — ПОКУПАТЕЛЬ, и неключевым полем в подчиненной таблице — ДОГОВОР.
Рисунок 11 – Взаимосвязанные таблицы реляционной БД
Размещение сведений о каждой сущности в отдельной таблице и связывание таблиц позволяет избежать повторения значений данных в разных
таблицах. При этом обеспечивается однократный ввод данных при загрузке и
корректировке БД. При хранении данных в двух таблицах сведения о покупателе хранятся в единственном экземпляре, а в таблице договоров повторяются только значения ключевого поля с кодом покупателя.
22
Отношение «один-к-одному» имеет место, когда одной записи в родительской таблице соответствует одна запись в дочерней. Это отношение
встречается намного реже, чем отношение "один-ко-многим".
Отношение «один-к-одному» может использоваться для разделения
таблиц, содержащих много полей, для отделения части таблицы по соображениям безопасности, а также для сохранения сведений, относящихся к подмножеству записей в главной таблице.
Отношение «многие-ко-многим» имеет место, когда каждая запись в
одной таблице связана с несколькими записями в другой таблице и наоборот.
Всякую связь "многие-ко-многим" в реляционной базе данных необходимо заменить на связь "один-ко-многим" (одну или более) с помощью введения дополнительных таблиц (рис. 12).
Рисунок 12 – Устранение связи «многие-ко-многим»
2.4 Нормализация отношений
Главная цель нормализации отношений базы данных – устранение избыточности и дублирования информации. В идеале при нормализации надо
добиться, чтобы любое значение хранилось в базе в одном экземпляре, причем значение это не должно быть получено расчетным путем из других данных, хранящихся в базе.
Приведение модели к требуемому уровню нормальной формы является
основой построения реляционной базы данных.
В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм:
1) первая нормальная форма (1NF);
2) вторая нормальная форма(2NF);
3) третья нормальная форма(3NF);
4) нормальная форма Бойса-Кодда (BCNF);
5) четвертая нормальная форма(4NF);
6) пятая нормальная форма, или нормальная форма проекции-соединения
(5NF или PJ/NF).
Основные свойства нормальных форм:
каждая следующая нормальная форма в некотором смысле лучше
предыдущей;
при переходе к следующей нормальной форме свойства предыдущих нормальных форм сохраняются.
23
В основе нормализации лежит декомпозиция отношения, находящегося
в предыдущей нормальной форме, в два или более отношений, удовлетворяющих требованиям следующей нормальной формы.
Наиболее важные на практике нормальные формы отношений основываются на фундаментальном в теории реляционных баз данных понятии
функциональной зависимости:
1. В отношении R атрибут Y функционально зависит от атрибута X(X и
Y могут быть составными) в том и только в том случае, если каждому значению X соответствует в точности одно значение Y: R.X→R.Y.
2. Функциональная зависимость R.X → R.Y называется полной, если
атрибут Y не зависит функционально от любого подмножества X.
3. Функциональная зависимость R.X→ R.Y называется транзитивной,
если существует такой атрибут Z, что имеются функциональные зависимости
R.X →R.Z и R.Z → R.Y и отсутствует функциональная зависимость R.Z → R.X.
При отсутствии последнего требования имелись бы транзитивные зависимости в любом отношении, обладающем несколькими ключами.
Неключевым атрибутом называется любой атрибут отношения, не входящий в состав первичного ключа (в частности, первичного).
Два или более атрибута взаимно независимы, если ни один из этих атрибутов не является функционально зависимым от других.
База данных считается нормализованной, если ее таблицы представлены как минимум в третьей нормальной форме. Часто многие таблицы нормализуются до четвертой нормальной формы, иногда, наоборот, производится
денормализация. Использования таблиц в пятой нормальной форме в реальных базах данных встречается редко.
Первая нормальная форма (1NF)
Отношение R находится в первой нормальной форме (1NF) в том и
только в том случае, если значения его атрибутов атомарны (неделимы).
Например, отношение КНИГА(АВТОР, НАЗВАНИЕ, ВЫХОДНЫЕ_ДАННЫЕ)не находится в первой нормальной форме, так как атрибут
ВЫХОДНЫЕ_ДАННЫЕ можно разделить на атрибуты: ИЗДАТЕЛЬСТВО,
ГОД, КОЛИЧЕСТВО_СТРАНИЦ.
Вторая нормальная форма (2NF)
Отношение R находится в2NF в том и только в том случае, когда находится в 1NF, и каждый неключевой атрибут функционально полно зависит от первичного ключа.
Если допустить наличие нескольких ключей, то данное определение
примет следующий вид:
Отношение R находится в2NF в том и только в том случае, когда оно
находится в 1NF, и каждый неключевой атрибут полностью зависит от
каждого ключа R.
24
Например, отношение УСПЕВАЕМОСТЬ(НОМЕР, ФАМИЛИЯ, ДИСЦИПЛИНА, ОЦЕНКА) находится в 1НФ и имеет составной ключ НОМЕР +
ДИСЦИПЛИНА. Это отношение не находится в 2НФ, так как атрибут ФАМИЛИЯ функционально зависим от поля НОМЕР составного ключа. Чтобы
привести это отношение к 2НФ необходимо разбить его на два связанных отношения:
УСПЕВАЕМОСТЬ(НОМЕР, ДИСЦИПЛИНА, ОЦЕНКА),
СПИСОК(НОМЕР, ФАМИЛИЯ).
Связь между отношениями осуществляется по полю НОМЕР.
Третья нормальная форма (3НФ)
Отношение находится в 3НФв том и только в том случае, когда находится в 2НФ, и отсутствуют транзитивные функциональные зависимости
неключевых атрибутов от ключевых.
Транзитивная зависимость присутствует в отношении, если существует
два неключевых поля, первое из которых зависит от ключа, а второе от первого.
Отношение ДИСЦИПЛИНА(НАЗВАНИЕ, ЛЕКТОР, УЧ_СТЕПЕНЬ,
ГРУППА) не находится в 3НФ, так как поле УЧ_СТЕПЕНЬ зависит от поля
ЛЕКТОР, но не от составного ключа, поэтому отношение необходимо разбить на два связанных отношения
ДИСЦИПЛИНА(НАЗВАНИЕ, ЛЕКТОР, ГРУППА),
ПРЕПОДАВАТЕЛЬ(ЛЕКТОР, УЧ_СТЕПЕНЬ).
На практике третья нормальная форма схем отношений достаточна в
большинстве случаев, и приведением к третьей нормальной форме процесс
проектирования реляционной базы данных обычно заканчивается. Однако
иногда полезно продолжить процесс нормализации.
Нормальная форма Бойса-Кодда (BCNF)
Эта форма применяется к отношениям, имеющим детерминант.
Детерминант – любой атрибут, от которого полностью функционально зависит некоторый другой атрибут.
Отношение R находится в нормальной форме Бойса-Кодда (BCNF) в
том и только в том случае, если каждый детерминант является возможным ключом.
Если в отношении между двумя атрибутами существует многозначная
зависимость, то нормализовать его можно с помощью четвертой нормальной
формы.
Четвертая нормальная форма (4NF)
В отношении R (A, B, C) существует многозначная зависимость
R.A R.B в том и только в том случае, если множество значений B, соот25
ветствующее паре значений A и C, зависит только от A и не зависит от С.
Отношение R находится в четвертой нормальной форме (4NF) в том
и только в том случае, если в случае существования многозначной зависимости A B все остальные атрибуты R функционально зависят от A.
Пятая нормальная форма (PJ/NF)
Во всех рассмотренных до этого момента нормализациях производилась декомпозиция одного отношения в два. Иногда это сделать не удается,
но возможна декомпозиция в большее число отношений, каждое из которых
обладает лучшими свойствами.
Отношение R (X, Y, ..., Z) удовлетворяет зависимости соединения * (X,
Y, ..., Z) в том и только в том случае, когда R восстанавливается без потерь
путем соединения своих проекций на X, Y, ..., Z.
Под проецированием без потерь понимается такой способ декомпозиции отношения, при котором исходное отношение полностью и без избыточности восстанавливается путем естественного соединения полученных отношений.
Отношение R находится в пятой нормальной форме (нормальной
форме проекции-соединения – PJNF) в том и только в том случае, когда любая зависимость соединения в R следует из существования некоторого возможного ключа в R.
Пятая нормальная форма – это последняя нормальная форма, которую
можно получить путем декомпозиции. Ее условия достаточно нетривиальны,
и на практике 5NF не используется. Заметим, что зависимость соединения
является обобщением, как многозначной зависимости, так и функциональной
зависимости.
3 ПРОЕКТИРОВАНИЕ РЕЛЯЦИОННЫХ БАЗ ДАННЫХ
3.1 Основные задачи и этапы проектирования
Проектирование баз данных — это процесс создания схемы базы данных и определения необходимых ограничений целостности. Основными задачами проектирования баз данных являются:
Обеспечение хранения в БД всей необходимой информации.
Обеспечение возможности получения данных по всем необходимым
запросам.
Сокращение избыточности и дублирования данных.
Обеспечение целостности данных (правильности их содержания): исключение противоречий в содержании данных, исключение их потери и т.д.
Процесс проектирования БД представляет собой последовательность
переходов от неформального словесного описания информационной структуры предметной области к формализованному описанию объектов предметной
26
области в терминах некоторой модели. В общем случае можно выделить следующие этапы проектирования (рис. 13):
Рисунок 13 – Этапы проектирования БД
Решение проблем проектирования на физическом уровне во многом зависит от используемой СУБД, зачастую автоматизировано и скрыто от пользователя. В ряде случаев пользователю предоставляется возможность настройки отдельных параметров системы, которая не составляет большой
проблемы.
Логическое проектирование заключается в определении числа и структуры таблиц, формировании запросов к БД, определении типов отчетных документов, разработке алгоритмов обработки информации, создании форм для
ввода и редактирования данных в базе и решении ряда других задач.
Решение задач логического проектирования БД в основном определяется спецификой задач предметной области. Наиболее важной здесь является
проблема структуризации данных.
3.2 Методы проектирования реляционных баз данных
Основная проблема проектирования реляционной базы данных состоит
в обоснованном принятии решений о том, из каких отношений должна состоять БД и какие атрибуты должны быть у этих отношений.
Для построения «хорошей» базы данных, которая находилась хотя бы в
27
третьей нормальной форме, можно использовать следующие методы:
1) Метод нормальных форм–метод пошаговой декомпозиции, заключающийся в последовательном разбиении исходной и промежуточных схем отношений до тех пор, пока результирующие отношения не будут удовлетворять заданным свойствам.
2) Метод синтеза, состоящий в конструировании (синтезе) набора
декомпозиционных подсхем, удовлетворяющих определѐнным
свойствам, из заданного множества атрибутов выбранной предметной области на основе заданного множества функциональных зависимостей, связывающих эти атрибуты.
3) Метод ER-диаграмм (семантическое моделирование) представляет собой моделирование структуры данных, опираясь на смысл
этих данных. В качестве инструмента семантического моделирования используются различные варианты диаграмм сущность-связь
(ER – Entity-Relationship).
1. Метод нормальных форм (классический метод)представляет собой
вариант восходящего подхода при проектировании БД. Нормализация предусматривает идентификацию требуемых атрибутов с последующим созданием
из них нормализованных таблиц, основанных на функциональных зависимостях между этими атрибутами (подраздел 2.4).
Восходящий подход в наибольшей степени приемлем для проектирования простых (как правило, централизованных) БД с относительно небольшим количеством атрибутов. Однако использование этого подхода существенно усложняется при проектировании распределенных БД, особенно при
интеграции локальных баз данных, которые могут быть выполнены с использованием различных моделей данных с большим количеством атрибутов, установить среди которых все существующие функциональные зависимости
довольно затруднительно
2. Более подходящей стратегией проектирования сложных баз данных является использование нисходящего подхода (метода синтеза). Начинается этот
подход с разработки моделей данных, которые содержат несколько высокоуровневых сущностей и связей, затем работа продолжается в виде серии нисходящих
уточнений низкоуровневых сущностей, связей и относящихся к ним атрибутов.
Например, сначала можно было бы идентифицировать сущности ВЛАДЕЛЕЦ и
ОБЪЕКТ_НЕДВИЖИМОСТИ, затем установить между ними связь ВЛАДЕЛЕЦ
владеет ОБЪЕКТОМ_НЕДВИЖИМОСТИ и лишь после этого определить связанные с ними атрибуты — например, ВЛАДЕЛЕЦ (номер_вл, имя_вл, адрес_вл)
и ОБЪЕКТ_НЕДВИЖИМОСТИ(номер_об, адрес_об).
3. Все варианты диаграмм сущность-связь исходят из одной идеи – рисунок всегда нагляднее текстового описания. Все такие диаграммы используют графическое изображение сущностей предметной области, их свойств
(атрибутов), и взаимосвязей между сущностями.
28
Без семантического моделирования можно обойтись, если число таблиц не превышает десяти, но оно совершенно необходимо, если БД включает
более сотни таблиц.
В настоящее время на рынке существует большое количество систем автоматизации проектирования баз данных (Сomputer-Аided Software Engineering – CASE-средств), обеспечивающих автоматизированное преобразование
диаграммных концептуальных схем баз данных, представленных в той или
иной семантической модели данных, в реляционные схемы данных конкретной СУБД (подраздел 4.1). Все CASE-системы имеют развитые средства документирования процесса разработки, автоматические генераторы отчетов позволяют подготовить отчет о текущем состоянии проекта с подробным описанием объектов БД и их отношений, что существенно облегчает ведение проекта.
3.3 Проектирование базы данных «Университет»
3.3.1 Инфологическое проектирование
Инфологическое проектирование проводится, как правило, методом
последовательных приближений к удовлетворительному набору схем отношений. Исходной точкой является представление предметной области в виде
одного или нескольких отношений, а на каждом шаге проектирования производится некоторый новый набор схем отношений, обладающих лучшими
свойствами.
Пусть в результате системного анализа установлена необходимость отразить в БД сведения о студентах вуза.
При этом БД должна содержать данные о каждом студенте: СТУДЕНТ(Номер зачетной книжки, Фамилия, Имя, Отчество, Номер группы,
Номер факультета, Наименование, Декан, Номер специальности, Наименование специальности, Стоимость, Дата рождения, Курс, Коммерческий).
Определим функциональные зависимости в исходном отношении (рис. 14).
29
Рисунок 14 – Функциональные зависимости в исходном отношении СТУДЕНТ
Следовательно, инфологическая модель предметной области будет
иметь вид, показанный на рис. 15.
Рисунок 15 – Инфологическая модель предметной области
Модель содержит не только информационные объекты, но и взаимосвязи между ними. Так, связь типа «один ко многим» устанавливается:
между объектами ГРУППА и СТУДЕНТ по их общему атрибуту
Номер группы;
между объектами ГРУППА и ФАКУЛЬТЕТ по их общему атрибуту
Номер факультета;
между объектами ГРУППА и СПЕЦИАЛЬНОСТЬ по их общему атрибуту Номер специальности.
Стоит, однако, обратить внимание на то, что полученная инфологическая модель, в целом удовлетворяющая требованиям нормализации, с точки
зрения логики может некорректно описывать предметную область. Модель
30
допускает существование некоторой специальности, которая не преподается
ни на одном факультете. Естественным желанием при этом является добавление связи между объектами ФАКУЛЬТЕТ и СПЕЦИАЛЬНОСТЬ. Альтернативой этому может быть определение домена для атрибута Номер специальности, который будет содержать только «существующие» номера специальностей.
3.3.2 Даталогическое проектирование
Выполняется описание логических структур сформированных информационных объектов, предполагаемых к реализации в базе данных. Описания
приведены в табл. 2 – 5.
Таблица 2 – Логическая структура информационного объекта СТУДЕНТ
Таблица 3 – Логическая структура информационного объекта ГРУППА
31
Таблица 4 – Логическая структура информационного объекта ФАКУЛЬТЕТ
Таблица 5 – Логическая структура информационного объекта
СПАЦИАЛЬНОСТЬ
После описания информационных объектов необходимо установить
правила ссылочной целостности для каждой связи инфологической модели.
Правила ссылочной целостности – это логические конструкции, которые выражают правила использования взаимосвязанных данных при их
добавлении, обновлении и удалении.
В ходе физической реализации БД каждой связи будут приписаны
триггеры ссылочной целостности (RI-триггеры), которые и обеспечат установленное правило целостности.
Триггеры – это подпрограммы, которые запускаются всякий раз при
выполнении команд вставки (INSERT), обновления(UPDATE) и удаления
(DELETE).
Допустим, что необходимо удалить один из экземпляров информационного объекта ГРУППА. Экземпляр информационного объекта СТУДЕНТ
не может существовать без соответствующего экземпляра объекта ГРУППА.
Следовательно, необходимо либо запретить удаление группы, в которой числится хотя бы один студент, либо сразу удалять всех студентов вместе с
32
группой. Такие правила ссылочной целостности называются RESTRICT и
CASCADE соответственно.
В другой ситуации, когда, например, экземпляр информационного объекта СТУДЕНТ может существовать без ссылки на номер группы в объекте
ГРУППА, при удалении какой -либо группы информация о ней должна остаться в объекте СТУДЕНТ. Такое правило называется SET NULL. При этом значение атрибута Номер группы объекта СТУДЕНТ принимает значение NULL.
Правило SET DEFAULT устанавливает атрибуту значение по умолчанию. Например, при «удалении» группы все студенты, которые в ней учились, зачисляются в другую группу (значению атрибута Номер группы объекта СТУДЕНТ присваивается значение по умолчанию).
Наконец, правило NONE не меняет значение атрибута. При «удалении»
группы запись о ней «повисает в воздухе», т. е. экземпляр объекта СТУДЕНТ
ссылается на несуществующую уже запись о группе.
3.3.3 Физическое проектирование
Основной целью физического проектирования базы данных является
описание способа физической реализации логического проекта базы данных,
т.е. реализации базы данных на вторичных запоминающих устройствах. На
этом этапе рассматриваются основные отношения, организация файлов и индексов, предназначенных для обеспечения эффективного доступа к данным, а
также все связанные с этим ограничения целостности и средства защиты.
Физическое проектирование неразрывно связано с конкретной СУБД.
Между логическим и физическим проектированием существует постоянная
обратная связь, так как решения, принимаемые на этапе физического проектирования с целью повышения производительности системы, способны повлиять на структуру логической модели данных.
4 АВТОМАТИЗАЦИЯ ПРОЕКТИРОВАНИЯ БАЗ ДАННЫХ
4.1 Общая характеристика CASE-средств
Современные CASE-средства (Computer-Aided Software/System Engineering) охватывают обширную область поддержки многочисленных технологий
проектирования информационных систем (ИС).
Обычно к этим средствам относят любое программное средство, автоматизирующее ту или иную совокупность процессов жизненного цикла (ЖЦ)
ИС. Интегрированное CASE-средство (или комплекс средств, поддерживающих полный ЖЦ ПО) содержит следующие компоненты:
репозиторий, являющийся основой CASE-средства. он должен обеспечивать хранение версий проекта и его отдельных компонентов,
синхронизацию поступления информации от различных разработчиков при групповой разработке, контроль метаданных на полноту
33
кодов;
и непротиворечивость;
графические средства анализа и проектирования, обеспечивающие
создание и редактирование иерархически связанных диаграмм, образующих модели ИС;
средства разработки приложений, включая языки 4gl и генераторы
средства конфигурационного управления;
средства документирования;
средства тестирования;
средства управления проектом;
средства реинжиниринга.
Все современные CASE-средства могут быть классифицированы в основном по типам и категориям.
Классификация по типам отражает функциональную ориентацию
CASE-средств на те или иные процессы жизненного цикла ИС.
Классификация по категориям определяет степень интегрированности
по выполняемым функциям и включает:
отдельные локальные средства, решающие небольшие автономные
задачи (tools);
набор частично интегрированных средств, охватывающих большинство этапов жизненного цикла ИС (toolkit);
полностью интегрированные средства, поддерживающие весь ЖЦ
ИС и связанные общим репозиторием.
Помимо этого, CASE-средства можно классифицировать по следующим
признакам:
применяемым методологиям и моделям систем и БД;
степени интегрированности с СУБД;
доступным платформам.
Классификация по типам в основном совпадает с компонентным составом CASE-средств и включает следующие основные типы:
средства анализа (Upper CASE), предназначенные для построения и
анализа моделей предметной области (Design/IDEF, BPwin);
средства анализа и проектирования (Middle CASE), поддерживающие наиболее распространенные методологии проектирования и
использующиеся для создания проектных спецификаций (Vantage
Team Builder, Designer/2000, Silverrun, PRO-IV, CASE Аналитик).
Выходом таких средств являются спецификации компонентов и интерфейсов системы, архитектуры системы, алгоритмов и структур
данных;
средства проектирования баз данных, обеспечивающие моделирование данных и генерацию схем баз данных (как правило, на языке
34
SQL)для наиболее распространенных СУБД.К ним относятся
ERwin, S-Designor и DataBase Designer.Средства проектирования
баз данных имеются также в составе CASE-средств Vantage Team
Builder, Designer/2000, Silverrun и PRO-IV;
средства разработки приложений. К ним относятся средства
4GL,JAM, PowerBuilder, Developer/2000, New Era, SQL Windows,
Delphi и др. и генераторы кодов, входящие в состав Vantage Team
Builder, PRO-IVи частично–в Silverrun;
средства реинжиниринга, обеспечивающие анализ программных
кодов и схем баз данных и формирование на их основе различных
моделей и проектных спецификаций. Средства анализа схем БД
входят в состав Vantage Team Builder, PRO-IV, Silverrun,
Designer/2000, ERwin, S-Designor, Rational Rose.В области анализа
программных кодов наибольшее распространение получают объектно-ориентированные CASE-средства, обеспечивающие реинжиниринг программ на языке С++ (Rational Rose, Object Team).
В большинстве CASE-средств в целях автоматизации проектирования
БД реализована семантическая модель данных, которая требует отдельного
рассмотрения.
4.2 Семантическая модель данных
Потребности проектировщиков баз данных в более удобных и мощных
средствах моделирования предметной области вызвали к жизни направление
семантических моделей данных, которые наиболее актуальны в автоматизированном проектировании. При этом любая развитая семантическая модель
данных, как и реляционная модель, включает структурную, манипуляционную и целостную части.
Главным назначением семантических моделей является обеспечение
возможности выражения семантики (смысла) данных и их взаимосвязей.
Наиболее часто на практике семантическое моделирование используется
на первой стадии проектирования базы данных. При этом в терминах семантической модели производится концептуальная схема базы данных, которая
затем вручную или автоматизированно преобразуется к реляционной (или какой-либо другой) схеме. Этот процесс выполняется под управлением методик,
в которых достаточно четко оговорены все этапы такого преобразования.
Одной из наиболее популярных семантических моделей данных является модель Сущность-Связь (Entity Relationship Model), часто ее называют
кратко ER-моделью.
На использовании разновидностей ER-модели основано большинство
современных подходов к проектированию баз данных (главным образом, реляционных). Модель была предложена Ченом (Chen) в 1976 г. Моделирование предметной области в этом случае базируется на использовании графических диаграмм, включающих небольшое число разнородных компонентов.
35
В связи с наглядностью представления концептуальных схем баз данных, ERмодели получили широкое распространение в CASE-системах, поддерживающих автоматизированное проектирование реляционных баз данных.
Основными понятиями ER-модели являются сущность, связь и атрибут.
Сущность – это реальный или абстрактный объект, информация о котором должна сохраняться и быть доступна.
Связь – это графически изображаемая ассоциация, устанавливаемая
между двумя сущностями. Эта ассоциация всегда является бинарной и может
существовать между двумя разными сущностями или между сущностью и ей
же самой (рекурсивная связь).
В любой связи выделяются два конца (в соответствии с существующей
парой связываемых сущностей), на каждом из которых указывается имя конца связи, степень конца связи (сколько экземпляров данной сущности связывается), обязательность связи (т. е. любой ли экземпляр данной сущности
должен участвовать в данной связи).
Связь представляется в виде линии, связывающей две сущности или
ведущей от сущности к ней же самой.
Атрибутом сущности является любая деталь, которая служит для
уточнения, идентификации, классификации, числовой характеристики или
выражения состояния сущности.
Метод IDEF1X является стандартом для разработки реляционных баз
данных и использует условный синтаксис, специально разработанный для
удобного построения семантической модели.
Использование метода IDEF1X наиболее целесообразно для построения
логической структуры базы данных после того, как все информационные ресурсы исследованы и решение о внедрении базы данных, как части корпоративной информационной системы, принято. Однако средства моделирования
IDEF1X изначально разработаны для построения реляционных информационных систем, и если существует необходимость проектирования другой
системы, скажем, объектно-ориентированной, то лучше избрать другие методы моделирования (например, на основе языка UML).
Сущность в IDEF1X описывает собой совокупность или набор экземпляров, похожих по свойствам, но однозначно отличаемых друг от друга по
одному или нескольким признакам. Каждый экземпляр является реализацией
сущности. Таким образом, сущность в IDEF1X описывает конкретный набор
экземпляров предметной области. Примером сущности IDEF1X может быть
сущность СТУДЕНТ, свойства которой присущи всем студента университета, а один из них, скажем, Иванов Петр Сергеевич, является конкретной реализацией этой сущности. В примере, приведенном на рис. 16, каждый экземпляр сущности СТУДЕНТ содержит некоторую информацию.
36
Рисунок 16 – Изображение в диаграмме сущности СТУДЕНТ
В IDEF1X-модели эти свойства называются атрибутами сущности. Каждый атрибут содержит только часть информации о сущности.
Сущность описывается в диаграмме IDEF1X графическим объектом в
виде прямоугольника. Каждый прямоугольник, отображающий собой сущность, разделяется горизонтальной линией на часть, в которой расположены
атрибуты первичного ключа, и часть, где расположены неключевые атрибуты. Верхняя часть называется ключевой областью, а нижняя часть – областью данных.
Первичный ключ –это набор атрибутов, выбранных для идентификации
уникальных экземпляров сущности. Неключевой атрибут – это атрибут, который не был выбран в качестве ключевого.
В стандарте IDEF1X сущность может быть независимой или зависимой
(рис. 17). Сущность является независимой, если каждый экземпляр сущности
может быть однозначно идентифицирован без определения его отношений с
другими сущностями.
Рисунок 17 – Сущности в IDEF1X
Сущность называется зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности.
37
Сущности могут иметь также внешние ключи (Foreign Key), которые
могут использоваться в качестве части или целого первичного ключа или неключевого атрибута. Внешний ключ изображается с помощью помещения
внутрь блока сущности имен атрибутов, после которых следуют буквы FK в
скобках (рис. 18). Сущность, внешний ключ которой является частью первичного ключа, является зависимой сущностью.
Рисунок 18 – Примеры внешних ключей
В стандарте IDEF1X определены типы связей, показанные в табл.
6Идентифицирующая связь между сущностью-родителем и сущностьюпотомком изображается сплошной линией. Сущность-потомок в идентифицирующей связи является зависимой от идентификатора сущностью. Сущность-родитель в идентифицирующей связи может быть как независимой, так
и зависимой от идентификатора сущностью (это определяется ее связями с
другими сущностями).
Пунктирная линия изображает неидентифицируемую связь. Сущностьпотомок в неидентифицирующей связи будет независимой от идентификатора, если она не является также сущностью-потомком в какой-либо идентифицирующей связи.
Пунктирная линия изображает неидентифицирующую связь. Сущностьпотомок в этой связи будет независимой от идентификатора, если она не является также сущностью-потомком в какой-либо идентифицирующей связи.
Рекурсивной является связь между сущностью и ей же самой (в этом
случае один или несколько экземпляров сущности ссылаются с помощью
внешнего ключа на другой экземпляр той же сущности).
38
Таблица6 – Типы связей стандарта IDEF1X
Необходимо отметить, что связей типа «многие-ко-многим» следует
избегать при создании БД. Пример связи типа «многие-ко-многим» показан
на рис. 19. Эта связь порождает чрезмерное дублирование данных, а самое
главное, существенно затрудняет обеспечение целостности по ссылкам. Разрешение связей данного типа показано на рис. 20.
Рисунок 19 – Связь типа «многие-ко-многим»
Рисунок 20 – Разрешение связей типа «многие-ко-многим»
39
В стандарте IDEF1X, как, например, в языках программирования развитыми механизмами типов данных, имеется возможность наследования типа сущности, исходя из одного или нескольких супертипов.
Возможны следующие типы связей супертипа с подтипами:
взаимоисключающие (Exclusive Subtype) полные и неполные;
входящие (Inclusive Subtype) полные и неполные.
Для подтипа Inclusive Subtype каждый экземпляр в супертипе может
быть связан с одним или несколькими входящими подтипами.
На рис. 21 и 22 представлены примеры использования взаимоисключающих подтипов.
Рисунок 21 – Взаимоисключающие полные подтипы
40
Рисунок 22 – Взаимоисключающие неполные подтипы
Однако связь супертипа с подтипами может быть трансформирована в
соответствии с одним из вариантов, показанных на рис. 23.
Рисунок 23 – Разрешение связей супертипа с подтипами
Средства метода IDEF1X в полном объеме реализуют семантическую
модель данных. Вместе с этим, IDEF1Xориентирован, в основном, на даль41
нейшую физическую реализацию реляционной БД в соответствующей СУБД.
Поэтому между объектами IDEF1X-модели и объектами реляционной модели
данных существует определенная взаимосвязь. Соответствие объектов
IDEF1X и реляционной модели данных показано в табл. 7.
Таблица 7 – Соответствие объектов IDEF1X объектам реляционной
модели
Существующая взаимосвязь между компонентами семантической и реляционной моделью позволяют преобразовывать ER-модель в реляционную
схему следующей последовательностью действий.
1. Каждая сущность, не являющаяся подтипом и не имеющая подтипов,
становится таблицей. Имя сущности становится именем таблицы.
2. Каждый атрибут становится столбцом с тем же именем в таблице.
3. Атрибуты первичного ключа становятся первичным ключом таблицы.
4. Связи «многие-ко-многим» разрешаются посредством введения ассоциативной таблицы.
5. Индексы создаются для первичного (уникальный индекс) и внешних
ключей.
6. Если в ER-модели присутствовали подтипы, то они либо сводятся в
одну таблицу, либо для каждого подтипа создается отдельная таблица.
42
4.3 Структурная схема автоматизированного проектирования базы
данных
Большинство современных CASE-средств, включающих функции автоматизированного проектирования баз данных, реализуют схему проектирования, показанную на рис. 24.
Рисунок 24 – Уровни автоматизированного проектирования базы данных
В представленной структурной схеме можно выделить три уровня:
1-й уровень. На данном уровне, на основе анализа предметной области
визуально строится семантическая модель данных (логическая структура будущей базы данных);
2-й уровень. Здесь устанавливается конкретная структура таблиц базы
данных, определяются характеристики атрибутов и связей между таблицами
в терминах целевой СУБД (формируется физическая структура будущей базы данных);
3-й уровень. На этом уровне осуществляется генерация физической модели данных в физическую базу данных целевой СУБД. На рис. 23 видно,
что современные CASE-средства поддерживают несколько целевых СУБД
(как правило, наиболее распространенных), что обеспечивается конкретным
видом физической модели данных.
Для более детального анализа предметной области 1-й уровень (логический уровень) может быть разбит на ряд подуровней:
1) Уровень Entity Relationships Diagram (ERD). Модель этого верхнего
(на1) уровень Entity Relationships Diagram (ERD). Модель этого верхнего (начального) уровня включает только сущности и связи между ними,
а также описание основных правил взаимодействия данных. Эта модель никак не оптимизирована (с точки зрения нормальных форм) и
служит в качестве первоначальной;
43
2) уровень Key Based Model (KB). Модель данного уровня представляет
оптимизированные сущности с детализацией их описания до ключевых
атрибутов;
3) уровень Fully Attributed Model (FA). Полная атрибутная модель этого
уровня представляет сущности в 3NF и включает все их атрибуты и связи.
В CASE-средствах поддерживается возможность прямого и обратного
проектирования (рис. 25).
Рисунок 25 – Прямое и обратное проектирование
Прямое проектирование (Forward Engineering) – это процесс преобразования (трансформации) физической модели данных в реальную схему базы
данных целевой СУБД.
Обратное проектирование (Reverse Engineer) – процесс преобразования физической схемы базы данных в физическую модель, а затем и в логическую.
Такая двунаправленность проектирования дает большие возможности
по модернизации и развитию базы данных.
5 БАЗИСНЫЕСРЕДСТВА МАНИПУЛИРОВАНИЯ ДАННЫМИ
5.1 Эквивалентность механизмов реляционной алгебры и реляционного исчисления
Как отмечалось, в манипуляционной составляющей определяются два
базовых механизма манипулирования реляционными данными – основанная
на теории множеств реляционная алгебра и базирующееся на математической
логике (точнее, на исчислении предикатов первого порядка) реляционное исчисление. В свою очередь, обычно рассматриваются два вида реляционного
исчисления – исчисление доменов и исчисление предикатов.
Все эти механизмы обладают одним важным свойством: они замкнуты относительно понятия отношения. Это означает, что выражения реляционной алгебры и формулы реляционного исчисления оп44
ределяются над отношениями реляционных БД и результатом вычисления также являются отношения.
В результате любое выражение или формула могут интерпретироваться
как отношения, что позволяет использовать их в других выражениях или
формулах.
Реляционная алгебра и исчисление обладают большой выразительной
мощностью: очень сложные запросы к базе данных могут быть выражены с
помощью одного выражения реляционной алгебры или одной формулы реляционного исчисления.
Механизмы реляционной алгебры и реляционного исчисления эквивалентны, т. е. для любого допустимого выражения реляционной алгебры можно построить эквивалентную (т. е. производящую такой же результат) формулу реляционного исчисления и наоборот. Однако эти механизмы различаются уровнем процедурный. Выражения реляционной алгебры строятся на
основе алгебраических операций (высокого уровня), и подобно тому, как интерпретируются арифметические и логические выражения, выражение реляционной алгебры также имеет процедурную интерпретацию. Для формулы
реляционного исчисления однозначная интерпретация, вообще говоря, отсутствует. Формула только устанавливает условия, которым должны удовлетворять кортежи результирующего отношения. Поэтому языки реляционного
исчисления являются более непроцедурными или декларативными.
Заметим, что крайне редко алгебра или исчисление принимаются в качестве полной основы какого-либо языка БД. Обычно язык БД (как, например, SQL) основывается на некоторой смеси алгебраических и логических
конструкций. Тем не менее, знание алгебраических и логических основ языков баз данных часто бывает полезно на практике.
5.2 Элементы реляционной алгебры
Основная идея реляционной алгебры состоит в том, что, коль скоро отношения являются множествами, то средства манипулирования отношениями могут базироваться на традиционных теоретико-множественных операциях, дополненных некоторыми специальными операциями, специфичными для
баз данных.
Рассмотрим расширенный начальный вариант алгебры, который был
предложен Коддом. В этом варианте набор основных алгебраических операций состоит из восьми операций, которые делятся на два класса – теоретикомножественные операции и специальные реляционные операции.
В состав теоретико-множественных операций входят операции:
объединения отношений;
пересечения отношений;
взятия разности отношений;
прямого произведения отношений.
45
Специальные реляционные операции включают:
ограничение отношения;
проекцию отношения;
соединение отношений;
деление отношений.
Кроме того, в состав алгебры включается операция присваивания, позволяющая сохранить в базе данных результаты вычисления алгебраических
выражений, и операция переименования атрибутов, дающая возможность
корректно сформировать заголовок (схему) результирующего отношения.
Хотя в основе теоретико-множественной части реляционной алгебры
лежит классическая теория множеств, соответствующие операции реляционной алгебры обладают некоторыми особенностями.
Рассмотрим операцию объединения (все, что будет говориться по поводу объединения, переносится на операции пересечения и взятия разности) .
Смысл операции объединения в реляционной алгебре в целом остается теоретико-множественным. Но если в теории множеств операция объединения
осмысленна для любых двух множеств-операндов, то в случае реляционной
алгебры результатом операции объединения должно являться отношение.
Все это приводит к понятию совместимости отношений по объединению.
Два отношения совместимы по объединению в том и только в том
случае, когда обладают одинаковыми заголовками. Более точно это
означает, что в заголовках обоих отношений содержится один и тот
же набор имен атрибутов, и одноименные атрибуты определены на
одном и том же домене.
Если два отношения совместимы по объединению, то при обычном выполнении над ними операций объединения, пересечения и взятия разности
результатом операции является отношение с корректно определенным заголовком, совпадающим с заголовком каждого из отношений-операндов.
Два отношения «почти» совместимы по объединению, т. е. совместимы во всем, кроме имен атрибутов, то до выполнения операции
эти отношения можно сделать полностью совместимыми по объединению путем применения операции переименования.
Операция пересечения двух отношений производит отношение, включающее все кортежи, входящие в оба отношения-операнды.
Отношение, являющееся разностью двух отношений, включает все
кортежи, входящие в отношение – первый операнд, такие, что ни один из них
не входит в отношение, являющееся вторым операндом.
Примеры, иллюстрирующие выполнение операций объединения, пресечения и взятие разности, приведены на рис. 26.
46
Рисунок 26 – Операции объединения, пересечения и разности
Другие проблемы связаны с операцией взятия прямого произведения
двух отношений. В теории множеств прямое произведение может быть полу47
чено для любых двух множеств, и элементами результирующего множества
являются пары, составленные из элементов первого и второго множеств. Поскольку отношения являются множествами, то и для любых двух отношений
возможно получение прямого произведения. Но результат не будет отношением. Элементами результата будут являться не кортежи, а пары кортежей.
В реляционной алгебре используется специализированная форма операции взятия прямого произведения – расширенное прямое произведение отношений. При взятии расширенного прямого произведения двух
отношений элементом результирующего отношения является кортеж, являющийся конкатенацией (или слиянием) одного кортежа
первого отношения и одного кортежа второго отношения.
Если отношения-операнды обладают одноименными атрибутами, то
проблемой может быть именование атрибутов результирующего отношения.
Эти соображения приводят к появлению понятия совместимости по взятию
расширенного прямого произведения.
Два отношения совместимы по взятию прямого произведения в том и
только в том случае, если множества имен атрибутов этих отношений не пересекаются. Любые два отношения могут быть сделаны совместимыми по взятию прямого произведения путем применения операции переименования к одному из этих отношений.
Следует заметить, что операция взятия прямого произведения не является слишком осмысленной на практике. Во-первых, мощность ее результата
очень велика даже при допустимых мощностях операндов, а во-вторых, результат операции не более информативен, чем взятые в совокупности операнды.
Специальные реляционные операции
Рассмотрим специальные реляционные операции реляционной алгебры: ограничение, проекция, соединение и деление.
Операция ограничения
Операция ограничения требует наличия двух операндов: отношения и
простого условия ограничения. Простое условие ограничения может иметь
вид (a comp-op b) или (a comp-op const), где а и b – имена атрибутов исходного отношения, для которых осмысленна операция сравнения, const–
литерально заданная константа, а comp-op – допустимая в данном контексте
операция сравнения.
Результатом ограничения отношения по некоторому условию является
отношение, заголовок которого совпадает с заголовком отношения-операнда,
а в тело входят те кортежи отношения-операнда, для которых значением условия ограничения является true. Пример, иллюстрирующий выполнение
операции ограничения, приведен на рис. 27.
48
Рисунок 27 – Операция ограничения
Операция взятия проекции
Операция взятия проекции также требует наличия двух операндов –
проецируемого отношения A и списка имен атрибутов, входящих в заголовок
отношения A.
Результатом проекции отношения A по списку атрибутов a1, a2, ...,
anявляется отношение с заголовком, определяемым множеством атрибутов
a1, a2, ..., an, и с телом, состоящим из кортежей вида <a1:v1,a2:v2, ...,
an:vn>таких, что в отношении A имеется кортеж, атрибутa1которого имеет
значение v1, атрибут a2 имеет значение v2, ..., атрибут an имеет значение vn.
Пример, иллюстрирующий выполнение операции взятия проекции,
приведен на рис. 28.
Рисунок 28 – Операция взятия проекции
Операция соединения отношений
Общая операция соединения (называемая также соединением по условию) требует наличия двух операндов – соединяемых отношений и третьего
операнда – простого условия. Пусть соединяются отношения A и B.Как и в
случае операции ограничения, условие соединения comp имеет вид либо (a
comp-op b), либо (a comp-op const), где a и b – имена атрибутов отношений A
и B, const – литерально заданная константа, а comp-op – допустимая в данном
контексте операция сравнения.
Тогда по определению результатом операции сравнения является отношение, получаемое путем выполнения операции ограничения по условию
comp прямого произведения отношений A и B.
Имеется важный частный случай соединения – эквисоединение и про49
стое, но важное расширение операции эквисоединения – естественное соединение.
Операция соединения называется операцией эквисоединения, если условие соединения имеет вид (a = b), где a и b – атрибуты разных операндов соединения.
Этот случай важен потому, что, во-первых, он часто встречается на
практике, и, во-вторых, для него существуют эффективные алгоритмы реализации. Пример, иллюстрирующий выполнение операции соединения (эквисоединения), приведен на рис. 29.
Рисунок 29 – Операция соединения отношений
Операция естественного соединения применяется к паре отношений
AиB,обладающих(возможно составным)общим атрибутомc (т.е. атрибутом с
одним и тем же именем и определенным на одном и том же домене). Пусть ab
обозначает объединение заголовков отношений A и B. Тогда естественное соединение A и B – это спроектированный на ab результат эквисоединения A и B.
Если вспомнить введенное определение внешнего ключа отношения, то
должно стать понятно, что основной смысл операции естественного соединения – возможность восстановления сложной сущности, декомпозированной
по причине требования третьей нормальной формы.
Операция деления отношений
Эта операция наименее очевидна из всех операций реляционной алгебры и поэтому нуждается в более подробном объяснении. Пусть заданы два
отношения – A с заголовком {a1, a2, ..., an, b1, b2, ..., bm} и B с заголовком {b1,
b2, ..., bm}. Считается, что атрибут bi отношения A и атрибут отношения B не
только обладают одним и тем же именем, но и определены на одном и том же
домене. Назовем множество атрибутов {aj} составным атрибутом a, а множество атрибутов {bj} – составным атрибутом b. После этого можно говорить о
реляционном делении бинарного отношения A(a,b) на унарное отношение
B(b).
50
Результатом деления A на B является унарное отношение C(a), состоящее из кортежей v таких, что в отношении A имеются кортежи <v, w> такие,
что множество значений {w} включает множество значений атрибута b в отношении B.
5.3 Элементы реляционного исчисления
Реляционное исчисление полностью базируется на исчислении логики
предикатов, использующей специальный язык, называемый языком логики
предикатов.
Алфавит языка логики предикатов составляют следующие символы:
a) p, q, r, s, … – пропозициональные переменные (символы для предложений, выражающих суждения);
b) a, b, c, d, … – индивидные константы (символы для элементарных
имен объектов);
c) x, y, z, … – индивидные переменные;
d) Pk, Qk, Rk, Sk, … –k-местные предикаторные символы (этими символами заменяются общие имена отношений);
e) ¬, ∧, ∨, ⊃, ≡–логические операции отрицания, конъюнкции, дизъюнкции, импликации и эквивалентности;
f) ∀, ∃ – кванторы общности и существования.
Выражения языка логики предикатов называются формулами. Среди
формул выделяют правильно построенные формулы(ППФ).
Определение ППФ:
1) пропозициональная переменная является ППФ;
2) если t1, t2, …, tk – термы, а Аk – k-местный предикатор, то Ak(t1,t2, …,
tk) – ППФ. При этом термом является либо индивидная константа,
либо индивидная переменная;
3) если A, B, C – ППФ, а x – индивидная переменная, то ¬A,
(B∧C), (B∨C), (A⊃B), (A≡B), ∀xA, ∃xA – ППФ;
4) ничто иное не является ППФ.
В общем случае ППФ языка логики предикатов соответствуют предложениям естественного языка, выражающим суждения. Например, предложение «Некоторые науки являются гуманитарными» можно перевести на язык
логики предикатов следующим образом:∃xP1(x), т. е. существует x такой, что
x есть P1. В эту формулу входит индивидная переменная x. С переменной
связывается область, из которой она принимает значения (область значений
переменной). В данном случае областью значений переменной является
множество наук. Если изменить область значений переменной, например,
считать этой областью множество любых объектов, то указанное предложение может быть выражено другой формулой: ∃x(S1(x)∧P1(x)), т. е. существует
x такой, что x есть S1 и x есть P1, где S1 – символ общего имени. Смысл последней формулы заключается в том, что существует такой объект, который
51
является наукой и который является гуманитарным.
Предположим, что имеются отношения, обладающие схемами:
СТУДЕНТ (Номер зачетной книжки, Номер группы, Фамилия, Имя,
Отчество, Дата рождения, Коммерческий) и ГРУППА (Номер группы, Номер
факультета, Номер специальности, Курс), и требуется узнать имена, номера
факультетов и зачетных книжек студентов, обучающихся в группах с номером больше 1000.
Если бы для формулировки такого запроса использовалась реляционная алгебра, то было бы получено алгебраическое выражение, которое читалось бы, например, следующим образом:
- выполнить соединение отношений СТУДЕНТ и ГРУППА по условию
СТУДЕНТ.Номер группы = ГРУППА.Номер группы;
- ограничить полученное отношение по условию Номер группы > 1000;
- спроецировать результат предыдущей операции на атрибуты Имя, Номер
зачетной книжки, Номер факультета.
В данном случае четко сформулирована последовательность шагов выполнения запроса, каждый из которых соответствует одной реляционной
операции. Если же сформулировать тот же запрос с использованием реляционного исчисления, то будет получена формула, которую можно было бы
прочитать, например, следующим образом: Выдать Имя, Номер зачетной
книжки, Номер факультета для студентов из тех групп, номера которых существуют и имеют значение больше 1000.
В этой формулировке указаны лишь характеристики результирующего
отношения, но ничего не сказано о способе его формирования. В этом случае
система должна сама решить, какие операции и в каком порядке нужно выполнить над отношениями СТУДЕНТ и ГРУППА.
6 СИСТЕМА УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ MS ACCESS
6.1 Общая характеристика СУБД MS Access
СУБД Microsoft Access является системой управления реляционной базой данных, включающей все необходимые инструментальные средства для
создания локальной базы данных, общей базы данных в локальной сети с
файловым сервером или базы данных на SQL-сервере, а также для создания
приложения пользователя, работающего с этими базами данных. База данных
Access, создаваемая на локальном компьютере, хранит в файле не только все
таблицы с данными, но и объекты приложения — формы, отчеты, а также
программный код. Благодаря этому можно создать приложение, целиком
хранящееся в одном accdb-файле, что существенно упрощает как создание,
так и распространение приложений баз данных.
52
6.2 Инструментальные средства СУБД Access
СУБД Access включают разнообразные и многочисленные инструментальные средства, ориентированные на создание объектов базы данных и
приложений пользователя.
Средства графического конструирования позволяют создавать объекты базы данных и объекты приложения с помощью многочисленных графических элементов, не прибегая к программированию.
Разнообразные мастера в режиме ведения диалога с пользователем позволяют создавать объекты и выполнять разнообразные функции по реорганизации и преобразованию баз данных.
Среди многочисленных средств графического конструирования и диалоговых средств Access следует выделить средства для создания:
таблиц и схем баз данных, отображающих их связи;
запросов выборки, отбирающих и объединяющих данные нескольких таблиц в виртуальную таблицу, которая может использоваться
во многих задачах приложения;
запросов на изменение данных базы;
экранных форм, предназначенных для ввода, просмотра и обработки данных в диалоговом режиме;
отчетов, предназначенных для просмотра и вывода на печать данных из базы и результатов их обработки в удобном для пользователя
виде.
Средства программирования СУБД включают язык структурированных запросов SQL, язык макрокоманд и язык объектно-ориентированного
программирования для приложений Microsoft Visual Basic for Applications
(VBA). VBA является частью семейства Microsoft Visual Basic, которое входит в состав Visual Studio.
VBA является базовым компонентом Microsoft Office: он интегрирован
в Access, Excel, FrontPage, Outlook, PowerPoint и Word. Все эти приложения, в
том числе и локализованные на русском языке, используют англоязычный
вариант VBA (включая справочную систему). VBA входит во все варианты
поставок Microsoft Office.
VBA представляет собой базовую платформу программирования не
только в среде Microsoft Office, но и многих других приложений.VBA содержит средства доступа не только к базам данных Access, но и к базам данных
клиент-серверной архитектуры, таким как Microsoft SQL Server, Oracle и др.
6.3 Система доступа к данным
Система доступа к данным, начиная с Access 2007, построена на основе ядра базы данных Access Database Engine, заменившего прежнюю версию
ядра Microsoft Jet 4.0. Ядро базы данных выполняет загрузку, сохранение и
53
извлечение данных в пользовательских и системных базах данных. Обеспечивает высокую производительность и улучшенные сетевые характеристики,
поддержку двухбайтового представления символов — Unicode, позволяющего использовать символы нескольких национальных алфавитов. Для компенсации возрастающего при Unicode объема памяти применяет сжатие данных,
сохраняемых в Unicode.
Ядро базы данных Access 2010 настроено для приложений системы Microsoft Office 2010 и обеспечивает интеграцию со службами Microsoft Windows SharePoint Services 3.0 и Microsoft Office Outlook 2010.
6.4 Поддержка технологий корпоративных сетей
Корпоративные сети являются сетями уровня предприятия, которые базируются на клиент-серверных и интернет-технологиях. Эти сети могут подключаться или не подключаться к Интернету.
Технологии Интернета позволяют получить доступ к информации всего предприятия со своего рабочего места, не заботясь о совместимости аппаратных и программных платформ, используя обычную программу просмотра
— обозреватель Internet Explorer.
Access включает развитые средства, ориентированные на клиентсерверные технологии, которые позволяют создавать клиентские приложения
для работы с общими базами данных SQL Server.
Для организации совместной работы с данными и взаимодействия
пользователей с помощью единой веб-среды могут быть использованы служба Windows SharePoint Services, специальные технологии взаимодействия и
коммуникаций, которые легко интегрируются с приложениями Microsoft
Office. Служба Windows SharePoint Services является компонентом Microsoft
Windows Server. Обеспечивает пользователей набором инструментов для организации информации, управления документами и эффективного взаимодействия.
С помощью Windows SharePoint Services можно создавать веб-сайты
для хранения общих данных и совместной работы с ними. Доступ пользователей к содержимому Web-сайтов осуществляется через web-обозреватель
или приложения Microsoft Office из любой точки корпоративной сети.
Access предоставляет разнообразные простые и удобные средства размещения данных из баз на одном или нескольких сайтах SharePoint для доступа к ним пользователей корпоративной сети, а также средства использования списков SharePoint в приложениях Access.
6.4.1 Многопользовательская база данных Access
База данных, как правило, содержит данные, необходимые многим
пользователям. Создание многопользовательской базы данных Access и получение одновременного доступа нескольких пользователей к общей базе
54
данных возможно в одноранговой сети персональных компьютеров или в сети с файловым сервером.
Под одноранговой понимается сеть, каждый компьютер которой может
предоставлять остальным подключенным к сети компьютерам доступ ко
всем или некоторым своим ресурсам, т. е. являться сервером и рабочей станцией одновременно.
Сети больших масштабов используют выделенные файловые серверы.
В сети, поддерживающей концепцию файлового сервера, база данных Access
размещается на компьютере, выделенном в качестве файлового сервера.
СУБД Access может быть установлена или на файловом сервере, или на каждой рабочей станции, но выполняется она всегда на рабочей станции пользователя. Обработка данных базы в обоих случаях также осуществляется на рабочих станциях пользователей. Поэтому по сети передаются с сервера на рабочие станции большие объемы данных, что сильно загружает ее и делает
невозможным одновременное обслуживание большого числа пользователей.
6.4.2 Работа Access с базой данных SQL Server
Работа с общей базой данных в сети с файловым сервером становится
неэффективной уже при одновременной работе 15 пользователей. На обеспечение эффективной работы большого числа пользователей с общей базой
данных ориентирована технология "клиент-сервер". В этой технологии пользователь-клиент передает со своего компьютера запрос на компьютер сервера, там СУБД обрабатывает запрос и обратно посылает только результат выполнения запроса. Таким образом, значительно снижается объем передаваемых по сети данных.
Приложение пользователя разрабатывается и выполняется под управлением СУБД Access на компьютере клиента. Общая база данных размещается
на мощном компьютере, где функционирует сервер баз данных, управляемый
СУБД SQL Server. Эта СУБД выполняет обработку данных, размещенных на
сервере, и отвечает за их целостность и сохранность. Для доступа к данным
базы на сервере используется язык структурированных запросов SQL.
Широко известны серверы баз данных — SQL Server фирмы Microsoft
и Oracle Server фирмы Oracle. SQL-серверы баз данных являются самыми
мощными приложениями для сетевой обработки данных.
Подключение из Access к серверам баз данных SQL может быть осуществлено с помощью драйверов ODBC. Каждому серверу баз данных соответствует свой драйвер ODBC. В комплект поставки MS Access включены драйверы ODBC для MS SQL Server и Oracle SQL Server.
Использование унифицированного языка запросов SQL позволяет работать с одной и той же базой данных сервера разным пользователям из различных приложений. Данные из базы могут получать Access, Excel, FoxPro и
многие другие приложения, использующие протокол ODBC, посылая запросы на языке SQL серверу баз данных.
55
6.4.3 Интернет-технологии
Пользователи баз данных все больше ориентируются на уникальные
возможности быстрого сбора и совместного использования информации,
предоставляемые интернет-технологиями. Базы данных широко используются как в интернет-публикациях, так и в электронной коммерции. Новые технологии в Access 2010 позволяют создавать специальные веб-приложения —
веб-базы данных и публиковать их на сайтах Microsoft SharePoint Server, на
которых выполняются службы Access. Базу данных можно опубликовать как
на собственном сервере SharePoint в интрасети, так и в Интернете. Пользователи могут использовать базу данных с помощью стандартного браузера, не
устанавливая приложение Access на компьютере. Это делает простым совместное использование корпоративной информации в среде настольных систем.
При этом пользователи могут с помощью браузера открывать веб-формы и
отчеты. В то же время сохраняется возможность работы в Access с веббазами данных автономно, можно вносить изменения в макеты и данные, а
затем, восстановив подключение, синхронизировать их с сервером Microsoft
SharePoint Server 2010.
6.5 Схема данных
В СУБД Access процесс создания реляционной базы данных включает
создание схемы данных. Схема данных наглядно отображает логическую
структуру базы данных: таблицы и связи между ними, а также обеспечивает
использование установленных в ней связей при обработке данных.
Для нормализованной базы данных, основанной на одно-многозначных
и одно-однозначных отношениях между таблицами, в схеме данных для связей таких таблиц по первичному ключу или уникальному индексу главной
таблицы могут устанавливаться параметры обеспечения связной целостности.
При поддержании целостности взаимосвязанных данных не допускается наличия записи в подчиненной таблице, если в главной таблице отсутствует связанная с ней запись. Соответственно при первоначальной загрузке
базы данных, а также корректировке, добавлении и удалении записей система допускает выполнение операции только в том случае, если она не приводит к нарушению целостности.
Связи, определенные в схеме данных, автоматически используются для
объединения таблиц при разработке многотабличных форм, запросов, отчетов, существенно упрощая процесс их конструирования.
В схеме данных связи могут устанавливаться для любой пары таблиц,
имеющих одинаковое поле, позволяющее объединять эти таблицы.
56
6.6 Объекты Access
База данных Access включает следующие сохраняемые в одном accdbфайле объекты:
таблицы, запросы, схемы данных, непосредственно имеющие отношение к базе данных;
формы, отчеты, макросы и модули, называемые объектами приложения.
Формы и отчеты предназначены для типовых процессов обработки
данных — просмотра, обновления, поиска по заданным критериям, получения отчетов. Эти объекты приложений конструируются из графических элементов, называемых элементами управления. Основные элементы управления служат для отображения полей таблиц, являющихся источниками данных объекта.
Для автоматизации доступа к объектам и их взаимодействия используется программный код. Только с помощью программного кода получается
полноценное приложение пользователя, функции которого доступны через
меню, панели инструментов и формы. Для создания программного кода используются модули на языке VBA и макросы.
Каждый объект и элемент управления имеет свои свойства, определяя
которые, можно настраивать их. С каждым объектом и элементом управления связывается набор событий, которые могут обрабатываться макросами
или процедурами обработки событий на VBA, входящими в состав модулей
форм, отчетов.
Объекты представлены в области навигации окна базы данных Access.
Все операции по работе с объектами собственно базы данных и приложений
начинаются в этом окне.
Таблицы(Tables) создаются пользователем для хранения данных об одной сущности — одном информационном объекте модели данных предметной области. Таблица состоит из полей (столбцов) и записей (строк). Каждое
поле содержит одну характеристику информационного объекта предметной
области. В записи собраны сведения об одном экземпляре информационного
объекта.
База данных Access может включать до 32 768 объектов (в том числе
формы, отчеты и т. д.). Одновременно может открываться до 2048 таблиц.
Запросы(Queries). Запросы на выборку служат для выборки нужных
данных из одной или нескольких связанных таблиц. Результатом выполнения
запроса является виртуальная таблица. В запросе можно указать, какие поля
исходных таблиц следует включить в запись таблицы запроса и как отобрать
нужные записи. Таблица запроса может быть использована наряду с другими
таблицами базы при обработке данных. Запрос может формироваться с помощью конструктора запросов или инструкции языка SQL. Запросы на изме-
57
нение позволяют обновлять, удалять или добавлять данные в таблицы, а также создавать новые таблицы на основе существующих.
Формы(Forms) являются основным средством создания диалогового
интерфейса приложения пользователя. Форма может создаваться для работы
с электронными документами, сохраняемыми в таблицах базы данных. Вид
таких документов может соответствовать привычному для пользователя бумажному документу. Форма используется для разработки интерфейса по
управлению приложением. Включаемые в форму процедуры обработки событий позволяют управлять процессом обработки данных в приложении. Такие процедуры хранятся в модуле формы. В формы могут вставляться рисунки, диаграммы, звуковые фрагменты, видео. Возможна разработка форм с
набором вкладок, с каждой из которых связано выполнение той или иной
функции приложения.
Отчеты(Reports) предназначены для формирования на основе данных
базы выходных документов любых форматов, содержащих результаты решения задач пользователя, и вывода их на печать. Как и формы, отчеты могут
включать процедуры обработки событий. Использование графических объектов позволяет дополнять данные отчета иллюстрациями. Отчеты обеспечивают возможность анализа данных при использовании фильтрации, агрегирования и представления данных источника в различных разрезах.
Макросы(Macros) являются программами, состоящими из последовательности макрокоманд, которая выполняется по вызову или при наступлении некоторого события в объекте приложения или его элементе управления.
Макросы позволяют автоматизировать некоторые действия в приложении
пользователя. Создание макросов осуществляется в диалоговом режиме путем выбора нужных макрокоманд и задания параметров, используемых ими
при выполнении. Конструктор макросов упрощают создание, редактирование
макросов, позволяют сокращать количество ошибок кода и более эффективно
создавать надежные приложения. Макросы данных позволяют изменять данные на основе событий в исходных таблицах, используются для добавления
логики к данным и сосредоточения ее в исходных таблицах. В WebприложенияхAccess, базирующихся на базах данных, опубликованных в
SharePoint, для программирования необходимо использовать только макросы,
так как код VBA несовместим со средствами Web-публикации.
Модули(Modules) содержат процедуры на языке Visual Basic for Applications. Могут создаваться процедуры-подпрограммы, процедуры-функции,
которые разрабатываются пользователем для реализации нестандартных
функций в приложении пользователя, и процедуры для обработки событий.
Использование процедур позволяет создать законченное приложение, которое имеет собственный графический интерфейс пользователя, позволяющий
запросить выполнение всех функций приложения, обработать все ошибки и
нестандартные ситуации.
58
6.7 Сводные таблицы и сводные диаграммы
Сводная таблица представляет собой интерактивную таблицу, с помощью которой можно анализировать данные, быстро объединяя большие объемы данных и рассчитывая итоги (рис. 30). С помощью сводных таблиц выполнение сложного анализа данных делается просто.
Рисунок 30 – Сводная таблица для анализа суммарного количества отгруженного по любому из товаров, по различным покупателям и договорам, по
всем или некоторым месяцам, кварталам, годам
Сводные диаграммы служат для наглядного графического представления анализируемой информации, облегчая для пользователей сравнение и
выявление тенденций и закономерностей в данных (рис. 31).
Для получения различных итогов по исходным данным достаточно в
созданном макете сводной таблицы выбирать значения в поле строк (Наименование товара▼), поле столбцов (Наименование покупателя▼, Номер
договора▼) и поле страницы (фильтра) (Дата отгрузки по месяцам▼).
Сводные таблицы позволяют динамически изменять макет для всестороннего анализа данных. Существует возможность изменять заголовки строк,
столбцов, а также полей, определяющих страницу. Создавать и быстро модифицировать макет можно, выбирая и перетаскивая поля из раскрывающегося списка полей в рабочую область. При каждом изменении макета сводная
таблица немедленно выполняет вычисления заново в соответствии с новым
расположением данных.
59
Рисунок 31 – Сводная диаграмма для анализа суммарного количества отгруженного по любому из товаров, по различным покупателям и договорам, по
всем или некоторым месяцам, кварталам, годам
Access позволяет открывать в режимах сводной таблицы и сводной
диаграммы таблицы, запросы и формы.
Таким образом, источником записей для режима сводной таблицы и
режима сводной диаграммы может быть не только таблица, но и базовый источник данных для формы. В базе данных Access источником записей может
быть таблица, запрос или инструкция SQL; в проекте Access — таблица,
представление, инструкция SQL, хранимая процедура или табличная функция.
6.8 Размещение базы данных
Все таблицы, а также другие объекты базы данных Access — запросы,
формы, отчеты, макросы и модули, построенные для этой базы, и внедренные
60
объекты могут размещаться на диске в одном файле формата ACCDB. Это
упрощает технологию ведения базы данных и приложения пользователя.
Обеспечивается высокая компактность размещения всех объектов базы данных на диске и эффективность обработки данных.
Когда база данных открыта, для корректного внесения изменений требуются блокировки данных разных уровней. Контроль над ними осуществляется с помощью файла блокировки. Если в MS Access 2010 открыт mdb-файл,
для контроля блокирования создается файл с расширением ldb и тем же именем, что у mdb-файла. Для файлов в формате ACCDB блокирование управляется файлом с расширением laccdb. Как ldb-файлы, так и laccdb-файлы уничтожаются автоматически, когда база данных будет закрыта всеми пользователями.
Введение отдельных блокирующих файлов для файлов Access 2010 и
файлов, созданных в более ранних версиях Access, обеспечивает одновременное открытие в Access 2010 файлов mdb и accdb с одинаковым именем, и
это не приведет к возникновению конфликтов в блокирующем файле, поскольку будут созданы два разных блокирующих файла. Также можно открывать один и тот же файл mdb в Access 2010 и в более ранней версии
Access одновременно, обе версии используют один и тот же блокирующий
файл ldb.
База данных Access 2010 может быть превращена в базу данных, доступную только для выполнения, не доступную для изменений и скрывающую
свой код. Для этого она должна быть скомпилирована и сохранена в файле
формата ACCDE, заменившем файлы с расширением mdb предыдущих версий. В процессе преобразования из базы данных удаляется весь исходный
текст программ на VBA, база сжимается, что значительно сокращает размер
файла. В базе данных формата ACCDE код VBA может только выполняться,
но просматривать и изменять его нельзя. При этом у пользователей нет разрешений на изменение структуры форм, отчетов или модулей. Для преобразования файла базы данных ACCDB в формат ACCDE на вкладке Файл (File)
нажмите кнопку Сохранить и опубликовать (Save & Publish) и выберите в
списке Сохранить базу данных как(Save Database As) пункт Создать
ACCDE(Make ACCDE) и в окне Сохранить как(Save As) нажмите кнопку
Сохранить(Save).
Проекты Access, являясь клиентскими приложениями пользователя,
позволяют подключаться к базам данных SQL Server, размещенным на вашем компьютере или в сети. Проект размещается в adp-файле на компьютере
пользователя. В проекте пользователь может создавать базу данных на сервере SQL или использовать существующую. Файл проекта, как и файл базы
данных Access, может быть преобразован в исполняемый файл, который
приобретет расширение ade.
Начиная с Access 2007 появилось новое расширение файлов — accdr,
позволяющее открывать базу данных в режиме выполнения. С помощью
61
простой замены расширения файла базы данных с accdb на accdr можно создать исполняемую версию базы данных Access 2007, закрытую для изменений. Чтобы восстановить полную функциональность, можно просто вернуть
файлу старое расширение — accdb.
7 СОЗДНИЕ БАЗЫ ДАННЫХ В СУБД MS ACCESS 2010
7.1 Начало работы с Access. Интерфейс пользователя
Сразу после запуска Access отображается новый компонент пользовательского интерфейса Access 2010 — представление Backstage с открытой
вкладкой Файл (File) (рис. 32). Представление Backstage — это место, где
можно управлять файлами. В момент открытия здесь доступны команды
Создать (New), Открыть (Open), Параметры (Options). Доступен список
недавно использованных последних баз данных, который позволяет быстро
выполнить открытие одной из них. Всплывающая подсказка каждой представленной в списке последних баз данных отображает местоположение ее
файла — полный путь к нему. Представлены многочисленные шаблоны для
создания различных типовых баз данных. Для открытой базы данных при
выборе вкладки Файл (File) отображается представление Backstage с командами, применимыми ко всей базе данных, такими как Сохранить и опубликовать (Save& Publish), Сжать и восстановить (Compact & Repair, Зашифровать паролем (Encrypt with Password).
Рисунок 32 – Окно представленияBackstage
62
На странице представления можно перейти к настройке основных параметров Access, параметров текущей базы данных, безопасности документов и компьютера, открыть справку. Кнопка Выход (Exit Access) обеспечивает закрытие Access.
В Access 2010 используется интерфейс пользователя, который упрощает доступ к многочисленным функциональным возможностям в процессе
создания и работы с объектами базы данных и приложения пользователя.
Главный элемент пользовательского интерфейса MS Access 2010 представляет собой Ленту, которая идет вдоль верхней части окна каждого приложения (рис. 33). Лента управления содержит вкладки. По умолчанию их
пять: Файл, Главная, Создание, Внешние данные, Работа с базами данных. Каждая вкладка связана с видом выполняемого действия.
Рисунок 33 – Элементы интерфейса MS Access 2010
Панель быстрого доступа. Расположена в верхней части окна Access.
По умолчанию на панели быстрого доступа расположены четыре кнопки
управления.
Область навигации, расположенная по левому краю окна Access. Она
предназначена для отображения объектов или групп объектов открытой базы
данных, а также для перехода от объекта к объекту. Чтобы раскрыть группу
объектов следует щелкнуть мышкой по кнопке. Управлять объектами можно
командами ленты и командами контекстного меню.
Коллекция
Коллекция — это элемент интерфейса, который отображает группу ко63
манд, показывая результат выполнения каждой из них. Смысл состоит в том,
чтобы предоставить пользователю возможность по внешнему виду найти и
выбрать нужные действия в Access 2010, сосредоточившись на результате, а
не на поиске команды.
Коллекции различаются по форме и размерам. Примеры коллекций
можно видеть на вкладках конструктора форм и отчетов. На рис. 34 приведена коллекция кнопки Темы.
Дополнительную более тонкую настройку внешнего вида формы или
отчета можно выполнить, воспользовавшись командами вкладок Формат и
Упорядочить.
Рисунок 34 –Пример коллекции на вкладке конструктора при работе с макетом формы или отчета
Диалоговые окна
Диалоговые окна выводятся при выполнении некоторых команд для
уточнения операции и передачи параметров. При открытом диалоговом окне
нельзя перейти к выполнению других действий в данном приложении. Диалоговое окно имеет постоянные размеры, но может быть перемещено в другое
место.
В некоторых группах вкладок ленты имеются маленькие значки —
кнопки вызова диалоговых окон. Нажатие такой кнопки открывает соответствующее диалоговое окно или область задач, предоставляя дополнительные
возможности, относящиеся к этой группе.
Пример диалогового окна Формат таблицы для выбора дополнительных параметров форматирования открытой таблицы базы данных на вкладке
Главная приведен на рис. 35.
64
Рисунок 35 –Диалоговое окно Формат таблицы
Пример области задач для отображения содержимого буфера обмена,
открывающейся кнопкой в группе Буфер обмена на вкладке Главная, приведен на рис. 36.
Рисунок 36 –Область задач внутреннего обмена
Контекстное меню
65
Access практический каждый элемент объекта в любом режиме снабжает динамическим контекстным меню, вызываемым правой кнопкой мыши
и содержащим набор команд, применимых в данной ситуации. Эти меню
включают большое число команд, не доступных в других элементах интерфейса Access. Например, команды открытия существующего объекта (таблицы, формы, отчета) в режиме конструктора, режиме таблицы или макета
представлены только в контекстном меню этого объекта, выбранного в области навигации, которая представляет все объекты базы данных.
7.2 Основные этапы разработки базы данных в среде MS Access
Процесс разработки конкретного программного приложения в среде
Access в первую очередь определяется спецификой автоматизируемой предметной области. Однако для большинства из них можно выделить ряд типичных этапов:
разработка и описание структур таблиц данных;
разработка схемы данных и задание системы взаимосвязей между
таблицами;
разработка системы запросов к таблицам базы данных и (при необходимости их интеграция в схему данных;
разработка экранных форм ввода/вывода данных;
разработка системы отчетов по данным;
разработка программных расширений для базы данных, решающих
специфические задачи по обработке содержащейся в ней информации, с помощью иструментария макросов и модулей;
разработка системы защиты данных, прав и ограничений по доступу.
7.2.1 Описание предметной области
Пусть на рынке (в некоторой торговой системе) циркулирует определенный набор ценных бумаг (акций), каждая из которых характеризуется наименованием, номинальной ценой, суммарным объемом пакета (то есть сколько всего единиц данной бумаги был эмитировано), датой эмиссии. Одновременно на рынке действуют его субъекты (агенты), которые могут продавать и
покупать бумаги. Очевидно, что каждый агент характеризуется, по меньшей
мере, наименованием и величиной средств, которыми он обладает. Таким образом, достаточно естественно выкристаллизовываются четыре массива информации (четыре сущности): данные по бумагам, данные по агентам (рынка),
данные по принадлежности бумаг агентам (по портфелям) и, наконец, данные
по заявкам агентов на покупку или продажу тех или иных бумаг.
Теперь попытаемся описать структуры потоков информации, которые
фигурируют в автоматизируемой предметной области, на более логически
строгом уровне.
Массив (таблица) данных по существующим активам (присвоим ей имя
66
Бумаги) будет содержать колонки (поля):
Код бумаги;
Наименование бумаги;
Номинальная цена;
Суммарный объем пакета;
Дата эмиссии;
Тип бумаги (например, акция или облигация).
Соответственно, таблица Агенты будет состоять из колонок:
Код агента;
Наименование агента;
Объем денежных средств, которыми обладает агент;
Комментарий по агенту.
Заметим, что поля Код бумаги и Код агента являются ключами, обеспечивающими уникальную идентификацию записей в соответствующих таблицах.
Для хранения информации о содержании портфелей ценных бумаг, которыми владеют агенты, создадим таблицу Портфели со структурой:
Код бумаги;
Код агента;
Количество бумаг данного наименования в портфеле, которым обладает данный агент.
В таблице Портфели мы сталкиваемся с составным ключом, который
образует комбинация полей Код бумаги и Код агента. Наконец, информацию
о намерениях тех или иных агентов продать те или иные бумаги поместим в
таблицу Заявки:
Код заявки;
Код бумаги;
Код агента;
Объем заявки (в единицах измерения, соответствующих бумагам
данного наименования);
Цена заявки.
Отметим, что экономическое содержание, вкладываемое в величину,
содержащуюся в поле Объем заявки, может иметь различные интерпретации.
Например, можно считать, что если это значение положительно, то это заявка
на покупку, а если отрицательно, то – на продажу. Очевидно, что возможны и
альтернативные решения по организации данной таблицы. Например, можно
было бы создать два отдельных поля: Объем заявки на покупку и Объем заявки на продажу. Дополнительно хочется обратить внимание на те резоны, в
соответствии с которыми в качестве ключа использовано отдельное поле Код
заявки. Это позволяет одновременно хранить в таблице разные предложения
по одной и той же бумаге, поступающие от одного и того же агента.
67
7.2.2 Создание таблиц
Процесс разработки базы данных в СУБД MS Access начинается с задания описания структур таблиц. Рассмотрим этот процесс более подробно
для таблиц примера, описанного в подразделе 6.3.1.
Итак, для начала нам необходимо создать описание таблицы Бумаги.
Нажав кнопку Создать и выбрав в появившемся вслед диалоговом окне режим Конструктор, мы попадаем в окно, предназначенное для ввода описания структуры создаваемой таблицы. Оно изображено на рис. 37.
Рисунок37 – Создание описания структуры таблицы Бумаги
Как видно из рисунка 37, процесс описания атрибутов поля начинается
с присвоения ему имени (идентификатора). Желательно, чтобы это имя было,
с одной стороны, информативным, а с другой – кратким, что обеспечивает
несомненные удобства при дальнейших манипуляциях с ним. Далее необходимо определить тип поля, что, очевидно, должно делаться, исходя из содержания тех данных, которые будут в нем храниться.
Обратим внимание на тип Счетчик, присвоенный полю КодБум (код
бумаги). Он означает, что СУБД будет самостоятельно помещать в это поле
некоторое числовое значение для каждой вновь создаваемой записи таблицы,
обеспечивая таким образом его уникальность.
Выбор типа данных в Access одновременно определяет набор дополнительных атрибутов соответствующего поля. В частности, поле ДатаЭм (дата
эмиссии) имеет тип Дата и, как это показано на рис. 37, может иметь дополнительные атрибуты:
68
формат поля, определяющий условия вывода данных из этого поля
(по умолчанию);
маска ввода, определяющая условия ввода данных в поле;
подпись – содержит расширенный заголовок;
значение по умолчанию - позволяет указать значение, автоматически присваиваемое полю при создании новой записи. В нашем случае по умолчанию будет задаваться текущая дата, возвращаемая
встроенной функцией Date();
условие на значение – определяет требования к данным, вводимым
в поле. Например, для выполнения требования, чтобы дата эмиссии
предшествовала текущей, следует задать выражение <=Date();
сообщение об ошибке – определяет текст сообщения, которое будет выводиться в случае нарушения заданного выше условия;
обязательное поле – указывает, требует или нет поле обязательного
ввода значения;
индексированное поле – определяет индекс, создаваемый по данному полю. Индекс ускоряет выполнение запросов, в которых используются индексированные поля, и операции сортировки и группировки.
Основываясь на опыте проектирования различных баз, необходимо заметить, что не следует пренебрегать возможностями управления данными,
которые открывают дополнительные атрибуты полей. Их грамотное и продуманное использование позволяет организовать централизованный и эффективный контроль за корректностью и целостностью данных.
На завершающем этапе процесса проектирования структуры таблицы
происходит задание ключей и индексов. В первом случае достаточно выделить строки, которые должны составить ключевое выражение, и щелкнуть
мышью по кнопке Ключевое поле на вкладке Конструктор (рис. 38). В таблице Бумаги роль уникального ключевого идентификатора выполняет поле
КодБум.
Рисунок 38 – Вкладка Конструктор на ленте
Также при создании таблицы имеет смысл заранее продумать возможные упорядочения, которые могут понадобиться при работе с содержащимися в ней данными. Задание индексов с соответствующими ключевыми выражениями может в дальнейшем существенно ускорить процесс работы (особенно с большими массивами данных). В частности, при работе с данными из
69
таблицы Бумаги весьма вероятно, что нам придется выводить их в алфавитном порядке по названиям, а также отсортированными в порядке убывания
дат. Процесс задания соответствующих индексов показан на рис. 39.
Рисунок 39 – Создание индексов для таблицы
Эффективным методом решения задач контроля корректности входных
данных является ограничение множества допустимых значений поля некоторым списком. Рассмотрим это более подробно на примере поля ТипБум (тип
бумаги), которая, допустим, в рассматриваемой торговой системе может
быть либо акцией, либо облигацией. Нетрудно заметить, что будет разумным
присвоить типу Акция код 1, а типу Облигация – код 2. Это позволит существенно сэкономить место за счет уменьшения объема хранимой информации
(особенно при большом количестве записей). Однако с точки зрения восприятия вводимой информации пользователем гораздо удобнее иметь дело с осмысленным текстом, чем запоминать, какие коды ему соответствуют.
Средством решения этой проблемы в Access является задание подстановочного списка значений для поля. Для этого следует выбрать вкладку
Подстановка в окне Свойства поля, далее для свойства Тип элемента
управления задать значение Список. На рис. 40 показано, как описать другие
свойства элемента управления Список, чтобы организовать заполнение поля
ТипБум требуемыми значениями.
После создания описания структуры таблицы можно перейти в режим
непосредственного ввода в нее данных. Как уже говорилось, важным преимуществом интерфейса СУБД Access является продуманная гибкая система
перехода от режима Конструктора к режиму ввода данных в таблицу (Режим таблицы). Такой переход можно осуществить, щелкнув мышью по пиктограмме Вид, расположенной на панели инструментов, либо выбрав функцию меню Вид> Режим таблицы.
70
Рисунок40 – Задание списка подстановки для поля
На рис. 41 показано окно режима непосредственного ввода данных в
таблицу Бумаги,
Рисунок41 – Ввод данных в таблицу Бумаги
7.2.3 Создание схемы данных
Очевидно, что те действия, которые были подробно описаны для таблицы Бумаги, следует проделать и для остальных информационных массивов: Агенты, Портфели, Заявки. В результате мы получим систему таблиц
базы данных TradeTest. Подчеркнем, именно систему, так как находящиеся в
них данные тесно и содержательно связаны между собой. Действительно,
данные, находящиеся в поле Код агента таблицы Портфели, должны быть
согласованы по типу и размеру с данными, находящимися в одноименном
поле таблицы Бумаги. Более того, логика рассматриваемой задачи требует,
чтобы, работая с информацией, относящейся к портфелю, мы могли одновременно обратиться к данным, характеризующим текущего агента, и т. д.
71
Механизм описания логических связей между таблицами в Access реализован в виде объекта, называемого Схемой данных. Перейти к ее созданию можно из панели инструментов База данных, доступной из главного
окна. Альтернативный вариант вызова данного режима доступен через меню
Сервис > Схема данных. Вид, который будет иметь схема данных для построенных на предыдущих шагах таблиц, представлен на рис. 42.
Рисунок42 – Создание схемы данных
Интерфейс задания связей между полями в схеме основан на «перетаскивании» (перемещении при нажатой левой кнопки мыши) выбранного поля
и «наложении» его на то поле, с которым должна быть установлена связь.
Для связывания сразу нескольких полей их следует перемещать при нажатой
клавише Ctrl. Выделяют несколько типов связей между таблицами в схеме.
«Один к одному» (1:1) – одному значению поля в одной таблице соответствует только одно значение поля в другой. «Один ко многим» (1:М) – одному
значению поля в одной таблице соответствует несколько (одно или более)
значений в другой.
Важнейшей задачей, которую позволяет решать схема, является обеспечение логической целостности данных в базе. Так, в базе данных TradeTest
нарушение целостности может возникнуть в случае удаления из таблицы Бумаги записей по тем бумагам, о которых существуют записи в таблицах
Портфели или Заявки, в результате чего в их составе окажутся ссылки на
«потерянные» коды. Очевидно, что это можно предотвратить, если каскадно
удалить как записи из таблицы Бумаги, так и записи из связанных с ней таблиц. Такой эффект в Access может быть достигнут за счет задания определенных свойств для связи. Чтобы это сделать, необходимо щелкнуть кнопкой
мыши, находясь на линии схемы, обозначающей связь. После этого появля72
ется диалоговое окно, предназначенное для изменения свойств связи. Как
видно из рис. 4, в рамках режима обеспечения целостности данных можно по
выбранной связи задать как каскадное обновление значений для связанных
полей, так и каскадное удаление связанных записей.
Рисунок 43 – Задание свойств связи
Появление даже очень небольшой таблицы мгновенно приводит к возникновению целого комплекса проблем, связанных с необходимостью обработки
содержащихся в ней данных. К простейшим задачам обработки могут быть отнесены:
поиск записи по условию (см. функцию меню Правка>Найти);
сортировка записей в требуемом порядке (см. функцию меню Записи>Сортировка);
получение выборки записей таблицы, удовлетворяющей заданному
условию, или, как еще говорят, задание фильтра для таблицы (Записи>Фильтр).
7.2.4 Разработка запросов к базе данных
Перечисленные функции также доступны из контекстного меню, активизирующегося по нажатию правой клавиши мыши (рис. 44). Данный интерфейс представляется особенно удобным при практической работе с таблицами Access. Однако этих возможностей явно недостаточно для задач обработки данных, которые возникают в реальных экономических приложениях. Для
их решения в СУБД Access служит развитой инструментарий запросов к базе
данных. Понятие запроса в Access употребляется в расширительном плане.
Его следует трактовать как некоторую команду на выбор, просмотр, изменение, создание или удаление данных. Также нельзя не отметить значение запросов для решения задач анализа данных.
Наиболее распространенным и, если так можно выразиться, естественным типом запросов является запрос на выборку. Данный тип, собственно
говоря, и устанавливается по умолчанию для вновь создаваемого запроса.
73
Рисунок 44– Контекстное меню работы с данными в таблице
При работе с системой данных очень часто возникает задача соединения данных из различных связанных таблиц в одну. Так, в рамках нашего
примера естественной представляется проблема построения таблицы, содержащей информацию по содержанию портфелей и имеющей следующую
структуру:
Наименование бумаги;
Наименование агента;
Тип бумаги;
Номинальная стоимость пакета, вычисляемая как произведение
номинальной цены на количество бумаг данного вида, которым обладает текущий агент.
Для ее решения следует перейти к разделу Запросы главного окна базы
данных, нажать на кнопку Создать и выбрать режим Конструктор. Процесс
создания запроса начинается с выбора таблиц (в том числе и Других запросов), на основе которых строится запрос. В дальнейшем состав этого набора
может быть изменен. Наш запрос будет построен на основе данных таблиц
Портфели, Агенты и Бумаги. Заметим, что при добавлении таблиц к запросу
по умолчанию добавляются и связи между ними, заданные в схеме. В процессе формирования запроса можно выделить ряд принципиальных этапов:
описание структуры запроса (то есть указание того, какая информация
должна выводиться в колонках таблицы запроса);
задание порядка, в котором данные должны выводиться при выполнении запроса;
задание условий вывода записей в запросе.
На рис. 5показано окно конструктора запроса.
Отметим, что колонки таблицы запроса на рис. 45 содержат как поля
таблиц, так и выражения, построенные на основе полей. В частности, последняя колонка (ей присвоено имя НоминСтоим) содержит выражение
74
[Номинал]*[СуммОбъем], при этом записи будут выводиться отсортированными по типу бумаг.
Рисунок 45 – Окно конструктора запроса
По аналогии с принципами организации интерфейса работы с таблицами данных, при конструировании запросов также существует возможность
оперативного перехода из режима Конструктор в Режим таблицы. При
первом входе в Режим таблицы появляется приглашение сохранить вновь
созданный запрос. В данном случае ему дано имя Структура Портфелей. На
рис. 46 показано окно, в котором выводятся записи, соответствующие этому
запросу.
Рисунок46 – Вывод данных по запросу Структура Портфелей
Следует обратить внимание на исключительно важную роль механизма
запросов в решении проблемы обеспечения минимальной избыточности сохраняемой в базе информации. Действительно, с их помощью мы можем получать произвольное количество виртуальных таблиц, представляющих в самых различных видах и разрезах единственную реально хранимую совокупность данных.
75
Рассмотрим еще один случай применения запросов для решения задач
обработки данных. Достаточно типичной является проблема группировки
данных по тому или иному признаку. Например, в рамках построенной нами
базы данных может быть поставлена задача определения суммарного (или
среднего) спроса и предложения по ценным бумагам, циркулирующим на
рынке. Решить ее можно, построив запрос, содержащий групповые операции.
Для активизации возможности их задания в окне Конструктора запросов
необходимо включить функцию меню Вид>Групповые операции.
Рисунок 47 – Создание запроса с групповыми операциями
На рис. 47 показано окно конструктора в процессе создания запроса,
выводящего информацию по суммарному спросу и предложению на ценные
бумаги. Операция свертки нескольких записей из таблицы Заявки в одну результирующую запись, осуществляемая для каждого наименования бумаги,
определяется командой Группировка, расположенной в строке Групповая
операция. Для двух последующих колонок запроса (СуммСпрос и СуммПредл) определены операции суммирования по группе (Sum), расположенные в той же строке, а в строке Поле находятся производные выражения,
суммы которых мы хотим получить в запросе. В соответствии с ранее принятыми соглашениями объем суммарного спроса определяется совокупностью
всех записей по данной бумаге, имеющих положительное значение в поле
ОбъемЗаявки, а объем суммарного предложения – записями, содержащими в
данном поле отрицательную величину. Таким образом, для вычисления
СуммСпрос необходимо просуммировать:
If[ОбъемЗаявки]>=0; [Цена3аявки] * [0бъем3аявки];0),
а для вычисления СуммПредл:
If[ОбъемЗаявки]<=0;-1* [Цена3аявки]*[0бъем3аявки];0).
76
ПРИМЕЧАНИЕ. Встроенная функция If(bArg; Arg1; Arg2) возвращает
значение аргумента Arg1, если значение аргумента bArg, который может содержать только логическую величину, является истинным (bArg = ИСТИНА), и значение Arg2, если bArg = ЛОЖЬ.
Также следует обратить внимание на такие важные возможности конструктора запросов, как:
задание параметров, запрашиваемых при открытии запроса;
встроенные статистические функции, доступные при задании групповых операций. Они делают запросы мощным инструментом анализа хранимой информации.
В завершение обзора средств построения запросов в СУБД Access следует указать также и на то, что в нее помимо мощного и эффективного визуального конструктора встроен также и режим непосредственного ввода SQLвыражений, определяющих запрос. Данный режим существует параллельно и
доступен из меню Вид > Режим SQL (а также из пиктограммы Вид на панели инструментов). Перейдя в него, в частности, можно просмотреть SQLвыражение, соответствующее ранее построенному запросу СводнСпросПредл. Оно выглядит так:
SELECT Бумаги.НаимБум,
Sum(IIf([ОбъемЗаявки]>=0,[Цена3аявки]*[0бъем3аявки],0))
AS СуммСпрос,
Sum (IIf ([ОбъемЗаявки]<=0,-[ЦенаЗаявки]*[0бъемЗаявки],0))
AS СуммПредл
FROM Бумаги INNER JOIN
(Агенты INNER JOIN Заявки ON Агенты.КодАг = Заявки.КодАг)
ON Бумаги.КодБум = Заявки.КодБум
GROUP BY Бумаги.НаимБум
ORDER BY Бумаги.НаимБум;
Пользователь, владеющий синтаксисом языка SQL, может модифицировать данное выражение в ручном режиме. Очевидно, что такая техника работы требует существенно большей квалификации, но одновременно она дает в руки разработчика мощный и универсальный аппарат управления данными.
Говоря о связи между режимом визуального конструктора запросов и
режимом построения SQL-выражений, необходимо отметить, что существует
естественная и логичная связь между типами запросов и реализующими
ихSQL-операторами. В частности, запросу на выборку соответствует оператор SELECT, запросу на создание – CREATE, запросу на обновление – UPDATE, запросу на удаление – DELETE и т. д.
77
7.2.5 Конструирование экранных форм для работы с данными
В 6.3.2 был рассмотрен режим непосредственного ввода данных в таблицу. Очевидно, что он имеет весьма ограниченное применение. Это обусловливается как тем, что длина записи может оказаться достаточно большой
и вводить информацию в нее в табличной форме будет технически неудобно,
так и соображениями более принципиального характера:
во-первых, структура таблицы должна строиться на основе логики
задач хранения информации, которая, вообще говоря, может существенно отличаться от логики ее накопления и ввода;
во-вторых, важным показателем качества автоматизированной системы является организация ее системы ввода/вывода в виде, максимально приближенном к традиционным формам представления
информации на немашинных носителях. Такие формы, как правило, делают программное обеспечение привлекательным для конечного пользователя, уменьшают период его адаптации ко вновь внедряемой системе и позволяют быстро сосредоточиться на решении
основных профессиональных задач;
в-третьих, в сложной и развитой автоматизированной информационной системе должно обеспечиваться разделение доступа к различным группам полей и записей для различных категорий пользователей в зависимости от выполняемых ими функций. Также в определенных ситуациях требуется представить одну и ту же информацию либо в различных видах и разрезах, либо в различных сочетаниях с другой информацией.
Для решения как этих, так и многих других проблем организации интерфейса ввода/ вывода данных в Access служит механизм электронных форм. Выберем вкладку Формы главного окна базы данных и нажмем кнопку Создать.
Появляющееся диалоговое окно позволяет выбрать как таблицу или запрос, для
работы с данными которых составляется форма, так и режим ее создания. В зависимости от квалификации пользователя и, естественно, сложности разрабатываемой формы можно либо воспользоваться встроенными программными
надстройками-мастерами, либо сразу начать ее создание с нуля в режиме Конструктора. Весьма плодотворным также оказывается комбинированный подход: сначала используется соответствующий мастер, а затем полученная форма
дополнительно дорабатывается в «ручном режиме». Проиллюстрируем сказанное на примере. Создадим форму для работы с таблицей Бумаги, воспользовавшись надстройкой Автоформа: в столбец. В результате получим окно следующего вида (рис. 48).
По умолчанию форме было предложено присвоить такое же имя, как и
у таблицы, на основе которой она была создана, то есть Бумаги. Как видно из
рис. 47, при создании подписей полей программная надстройка использовала
их соответствующие атрибуты, заданные при конструировании таблицы. По78
следнее не всегда бывает удобным с точки зрения интерфейса пользователя.
Для устранения этих и подобных недостатков нам придется вернуться в режим изменения макета формы (кнопка Конструктор либо пиктограмма Вид
на панели инструментов).
Рисунок48 – Форма Бумаги в режиме Автофильтра
На рис. 49 показана та же форма в режиме Конструктор.
Рисунок 49 – Форма Бумаги в режиме конструктора
Технология процесса проектирования форм в среде Access сводится к
добавлению управляющих элементов и изменению их свойств. В связи с
этим при переходе в режим Конструктор на экране по умолчанию появляются два дополнительных окна:
окно Панель элементов, которое предназначено для выбора очередного
добавляемого к проектируемой форме управляющего элемента. В конструктор форм Access встроены такие элементы управления, как надпись,
поле, кнопка, флажок, переключатель, список, набор вкладок и др. Помимо этого к форме можно подключать специальные (дополнительные) эле79
менты управления OLE, что значительно расширяет возможности развития интерфейса управления данными.
окно свойств текущего элемента управления, предназначенное для изменения его атрибутов и настроек, например, цвета, шрифта, размера и т. п.
В режиме Конструктор явно видна структура формы. Она состоит из
трех частей: Заголовок формы, Область данных и Примечание формы.
Такая структура в первую очередь ориентирована на возможности представления таблично организованных данных. При этом как сама форма, так и ее
разделы также рассматриваются как элементы управления, обладающие некоторыми настраиваемыми наборами свойств.
В качестве иллюстрации возможностей конструктора по изменению
интерфейса ввода/вывода проведем следующие манипуляции над формой
Бумаги:
1. Удалим фоновый рисунок: очистим свойство Рисунок, когда текущим
выбранном элементом является вся форма.
2. Изменим цвет фона: выберем элемент Область Данных и изменим у
нее атрибут Цвет фона (рис. 50).
Рисунок 50 – Окно свойств элемента управления
3. Изменим внешний вид полей: выделим группу полей (поля выбираются
с помощью мыши при нажатой клавише Shift) и в окне свойств изменим значение атрибута Оформление на Утопленное.
4. Отредактируем подписи полей и несколько изменим их расположение
друг относительно друга: для этого достаточно воспользоваться возможностями визуального редактирования элементов.
5. Добавим разделительную линию после поля НаимБум (Наименование
бумаги): для этого следует воспользоваться элементом Линия.
6. Добавим кнопку завершения работы с формой: в большинстве ситуаций эту и подобные операции проще и удобнее делать в режиме мастера (нажата соответствующая кнопка на панели Элементы управле80
ния). В этом случае от пользователя требуется лишь ввести минимальное количество параметров для добавляемого программного компонента. Добавленную кнопку поместим в область Примечания формы.
В результате отредактированная форма Бумаги примет вид, показанный на рис 51.
Рисунок 51 – Форма Бумаги после редактирования
Пример организации ввода/вывода данных в таблицу Бумаги с помощью
одноименной формы носит в некотором смысле вырожденный характер: в нем
структура полей в форме однозначно соответствует их структуре в таблице.
Однако, как правило, при создании реальных приложений приходится решать
задачу управления данными, находящимися в системе взаимосвязанных таблиц, из единой формы. В качестве примера рассмотрим задачу построения
формы, в которой для каждой данной бумаги одновременно выводится информация по заявкам на ее покупку и продажу. Верхняя (заголовочная) часть
формы соответствует текущей строке таблицы Бумаги и меняется при переходе от записи к записи, который может производиться с помощью стрелок, расположенных в нижней части окна. Одновременно должны меняться строки
таблиц Заявки на продажу и Заявки на покупку, в которые выводится только
информация, относящаяся к текущей бумаге.
Рассмотрим более подробно те средства Access, с помощью которых
может быть получен такой результат. Это так называемая сложная/или составная форма (Заявки по бумагам). Процесс ее создания состоит из двух
принципиальных этапов:
создание основной (главной) формы. Для этого осуществляются
действия, аналогичные тем, которые выполнялись при создании
формы Бумаги;
создание подчиненных форм. Для этого в созданную главную форму добавляется элемент управления Подчиненная форма.
При создании подчиненной формы в Access существует две принципиальные возможности:
81
создать новую форму на базе некоторой таблицы или запроса;
воспользоваться уже существующей формой, сделав ее подчиненной.
В данном случае созданы две новые подчиненные формы. Причем созданы они на базе специальных запросов. Такое решение позволяет выделить
по отдельности из общей таблицы Заявки записи с заявками на продажу и на
покупку. В частности, запрос ЗаявПрод, возвращающий выборку из заявок на
продажу ценных бумаг, имеет структуру, показанную на рис. 52.
Рисунок 52 – Структура запроса ЗаявПрод (заявки на продажу)
В качестве преимуществ такого подхода к организации источника данных для подчиненной формы следует отметить следующие моменты:
во вспомогательном запросе достаточно просто обработать условие, идентифицирующее тип заявки (если объем заявки меньше нуля, то это заявка на продажу). Более того, для конечного пользователя в качестве объема заявки вместо отрицательных величин выводятся выглядящие более естественно положительные значения:
1*[Объем3аявки];
данные выводятся отсортированными по возрастанию предлагаемых цен, что несомненно упрощает процесс работы с ними в экранной форме.
Запрос, возвращающий записи с заявками на покупку, создается аналогично с учетом модификации условия отбора.
Наиболее существенным моментом в процессе внедрения подчиненной
формы в главную является правильное задание условия связи между ними.
Во многих случаях с этим корректно справляются программные надстройки
мастеров. При этом они используют информацию из схемы данных и описаний структуры таблиц. В то же время не следует забывать и о возможностях
изменения условий связи между ведущей и подчиненной формами в ручном
82
режиме. Для этого необходимо изменить атрибуты в элементе управления
Подчиненная форма, находясь в режиме Конструктор
7.2.6 Конструирование отчетов
Под отчетом традиционно понимается специальным образом структурированное представление хранимых данных, выводимое (как правило) на
бумажный носитель. Перечислим принципиальные отличия отчетов от экранных форм, обусловившие выделение их в отдельный программный объект
СУБД Access:
во-первых, отчеты являются исключительно средством вывода информации;
во-вторых, организация данных в отчетах предполагает возможность их сложного, многоуровневого структурирования;
в-третьих, структура информации, выводимой в отчете, должна
быть согласована со структурой носителя. Например, разбиение
отчета на страницы предполагает организацию вывода регулярных
элементов в начале и конце каждого листа (колонтитулов), дублирование шапок таблиц и т.д. Также на внешний вид отчета значительное влияние оказывают параметры конкретного печатающего
устройства, которое будет использовано для его вывода.
В то же время, к числу важных достоинств Access относится то, что
идеология работы как с экранными формами, так и с отчетами максимально
универсализирована. В частности, интерфейс режима конструирования макета отчета аналогичен режиму конструктора для экранных форм.
Рассмотрим способы решения задач разработки отчетов, которые могут
возникать в рамках описываемой нами программной системы управления
торгами ценными бумагами. Простейшие отчеты, которые, скорее всего, будут необходимы пользователям системы, – это распечатанные списки бумаг
и агентов. Для их создания можно воспользоваться надстройками Автоотчет
в столбец или Автоотчет ленточный. На рис. 53 показан макет отчета по
агентам, созданный в режиме Автоотчет ленточный.
Из рис. 53 видно, что в процессе конструирования в макет отчета могут
быть добавлены те же самые управляющие элементы, что и при конструировании макета экранной формы. В то же время следует отметить, что структура отчета как объекта базы данных имеет свою специфику. Во-первых, она
определяется уровнями группировки данных, выводимых в отчет, а вовторых, содержит секции, соответствующие регулярным элементам, помещаемым в начале и конце каждого листа – верхнему и нижнему колонтитулам. Для задания уровней группировки данных используется функция меню
Вид > Сортировка и группировка или же одноименная пиктограмма на панели инструментов Конструктор отчетов.
83
Рисунок 53 – Отчет по агентам в режиме конструктора
При работе с отчетами активно используются (это видно из рис. 53)
встроенные переменные [Page] и [Pages], возвращающие номер текущей
страницы отчета и общее, количество страниц в нем, а также функция Now(),
определяющая текущую дату и время по системному календарю.
Остановимся теперь на более сложном примере. Поставим задачу построить отчет, выводящий сведения о спросе и предложении по ценным бумагам с учетом их типа, то есть записи должны быть структурированы по
следующим уровням:
все бумаги;
тип бумаги;
агент;
предложения агента по данной бумаге.
Также по каждому из уровней желательно предусмотреть вывод промежуточных итогов (или же соответствующих средних значений).
Информация для данного отчета (назовем его РаспределЗаявок) должна
браться из различных таблиц, поэтому в качестве источника данных для него
целесообразно использовать специально построенный запрос. Для наглядности приведем SQL-выражение, соответствующее данному запросу:
SELECT
Заявки.КодБум,
Бумаги.НаимБум,
Бумаги.Номинал,
Агенты.НаимАг,
IIf ([0бъем3аявки]<0,-1*[0бъем3аявки],0) AS ОбъемПродажи,
IIf ([ОбъемЗаявки]<0,[ЦенаЗаявки],0) AS ЦенаПродажи,
84
IIf ([0бъем3аявки]>0,[0бъем3аявки],0) AS ОбъемПокупки,
IIf ([ОбъемЗаявки]>0, [ЦенаЗаявки],0) AS ЦенаПокупки,
FROM Бумаги
INNER JOIN (Агенты INNER JOIN Заявки ON Агенты.КодАг = Заявки.КодАг)
ON
КодБум = Заявки.КодБум
ORDER BY IIf ([ТипБум]="1", "Акции", "Облигации"),
Бумаги.НаимБум;
На основе построенного запроса можно перейти к разработке отчета.
На начальном этапе представляется рациональным воспользоваться услугами
мастера отчетов. Он в режиме диалога с пользователем позволяет создать походящую "заготовку", избавляя нас от многих рутинных операций, например
таких, как добавление полей и подписей к ним.
Далее полученный макет вручную "доводится" до желаемого вида в
режиме Конструктор
Важным этапом при создании многоуровневого отчета является задание уровней группировки выводимых данных. Это делается в окне, показанном на рис. 54, которое вызывается из меню Вид > Сортировка и группировка.
Рисунок 54 – Задание уровней группировки и сортировки
Для каждого из заданных уровней группировки данных могут быть определены раздел типа Заголовок, выводимый в начале каждой группы, и
раздел типа Примечание, формируемый, когда группа заканчивается.
Задачи получения средних и итоговых значений по группам данных
решаются с помощью встроенных функций Sum() и Avg(). Например, для
получения среднего значения цены продажи бумаги в соответствующем элементе управления свойство Данные содержится строка:
=Avg([ОбъемПродажи]),
а для определения итогового спроса используется формула:
=Sum([ОбъемПродажи]*[ЦенаПродажи]).
85
7.2.7 Средства макропрограммирования в MS Access
Access, как и любая другая развитая программная система, обладает
средствами разработки программных приложений, ориентированных на конечных пользователей. Эти средства базируются на инструментах двух типов: макросах и модулях. Само понятие макроса подразумевает наличие набора некоторых стандартных команд системы, или макрокоманд (допустим,
таких, как открытие формы, выполнение запроса, вывод отчета), из которых
и конструируется сам макрос.
Макрос может быть как собственно макросом, состоящим из последовательности макрокоманд, так и группой макросов. Группой макросов называют их набор, сохраняемый под общим именем. В некоторых случаях для
решения, должна ли в запущенном макросе выполняться определенная макрокоманда, может применяться условное выражение.
Особый интерес вызывает механизм вызова макросов в Access. Для
этого существует две принципиальных возможности:
вызов макроса по команде пользователя (либо непосредственно из раздела Макросы главного окна базы данных, либо с помощью меню или
панели инструментов, с которыми он также может быть ассоциирован);
вызов макроса по некоторому системному событию (открытие или закрытие формы, изменение управляющего элемента и т. п.).
Весьма полезной представляется возможность организовать автоматическое выполнение ряда действий при открытии базы данных. Для этого они
должны быть описаны в специальном макросе с именем Autoexec.
Возможности применения макросов при работе в среде СУБД Access
можно наглядно продемонстрировать на следующем примере. Предположим,
что в ранее созданную форму Бумаги мы хотим добавить процедуру дополнительного контроля вводимых значений дат эмиссии ценных бумаг, которая
должна будет выдавать предупреждающее сообщение, если вводится слишком «ранняя» дата. Допустим, что к таковым относятся даты, предшествующие 1 января 1991 года.
Технически решение представляется удобным реализовать в виде макроса, вызываемого по событию «до обновления», ассоциированному с полем
ДатаЭм в форме Бумаги.
На рис. 55 показан процесс разработки данного макроса (ему дано имя
КонтрольДатаЭм).
Рисунок 55 – Создание макроса
86
Из него видно, что макрос содержит три макрокоманды:
Первая, Остановить Макрос – прерывает работу, если введена дата
более поздняя, чем 1 января 1991 года.
Вторая, Остановить Макрос – выполняется, если пользователь считает, что несмотря на сделанное предупреждение введенная дата является
верной. Для вывода предупреждения используется встроенная функция
MsgBox.
Третья – отменяет событие ввода данных, если они после предупреждения признаются ошибочными.
Хорошим стилем разработки макросов является снабжение их комментариями, располагаемыми в соответствующей колонке.
На рис. 56 показана привязка разработанного макроса к событию «до
обновления» поля ДатаЭм формы Бумаги.
Рисунок 56 – «Привязка» макроса к событию
7.2.8 Разработка программных приложений для MS Access
Модули, в отличие от макросов, являются более тонким и мощным
средством создания программных расширений в среде Access, максимально
приближающимся по своим функциональным возможностям к таким профессиональным инструментам, как Delphi, Visual Basic или PowerBuilder.
Одновременно применение модулей требует от пользователя навыков и квалификации программиста, а также знания основных принципов объектноориентированного программирования.
Для программирования в Access используется процедурный язык Visual Basic для приложений (VBA – Visual Basic for Applications) с добавлением
объектных расширений и элементов SQL. Сам процесс создания программных расширений в среде Access предполагает активное использование технологии объектно-ориентированного программирования (ООП). В основе ООП
лежит идея «упакованной функциональности», в соответствии с которой программа строится из фундаментальных сущностей, называемых объектами.
87
Каждый из объектов характеризуется набором свойств (англ. – property) и
операций, которые он может выполнять (англ. – method). Реализация взаимодействий между объектами ложится на исполняющую среду того средства
разработки, на котором пишется программа, и поэтому работа программиста
в рамках технологии ООП сводится к созданию объектов, описанию их
свойств и реакций на те или иные внешние события.
Фундаментальным понятием ООП является класс. Класс – это шаблон,
на основе которого может быть создан конкретный программный объект.
Созданный объект в таком случае становится экземпляром класса. К основополагающим принципам ООП относятся:
инкапсуляция – объединение свойств и действий, присущих объекту, в
едином пакете и сокрытие подробностей их реализации от окружающего мира. Это означает, что пользовательский доступ к объекту допускается только через его свойства и методы;
наследование – предусматривает создание новых классов на базе существующих, что дает возможность классу-потомку иметь (наследовать)
все свойства класса-родителя;
полиморфизм – (от греч. «многоликость») означает, что порожденные
объекты обладают информацией о том, какие методы они должны использовать в зависимости от того, где они находятся в цепочке наследования;
модульность – объекты заключают в себе полное определение их характеристик, никакие определения методов и свойств объекта не должны располагаться вне его, что делает возможным свободное копирование и внедрение одного объекта в другие.
Многие программные объекты в Access совпадают с физическими объектами базы данных, такими как таблицы, формы, отчеты. Для названия составных объектов, которые включают в себя совокупность более простых
объектов, используется термин семейство. Например, объект Отчет входит в
семейство Отчеты. Помимо «видимых» объектов существует и большое количество «скрытых» объектов, управлять которыми можно только из программных приложений.
В Access существуют два типа модулей: стандартные и модули класса.
Стандартные модули содержат процедуры и функции, которые могут
быть вызваны из любого окна базы данных. Как правило, такие модули содержат программный код универсального характера, предназначенный для
применения в различных местах текущего приложения или даже в различных
приложениях.
Модули класса используются, для создания новых классов объектов.
При создании конкретного объекта, являющегося экземпляром такого класса,
любые процедуры, определенные в модуле, становятся свойствами и методами этого объекта.
88
Модули форм и модули отчетов являются модулями класса, связанными с определенной формой или отчетом. Заметим, что в ранних версиях
Access они являлись единственно возможным инструментом объектноориентированного программирования. Эти модули содержат процедуры обработки событий, запускаемых в ответ на их возникновение в форме или отчете. Процедуры обработки событий используются для управления поведением формы или отчета и их откликом на события, например такие, как нажатие кнопки.
Важнейшей областью применения объектно-ориентированного программирования в Access является программирование доступа к данным. Для
решения данной задачи фирмой Microsoft был разработан специальный интерфейс – DАО (Data Access Objects). DAO – это набор объектных классов,
которые моделируют структуру реляционной базы данных. Они обеспечивают свойства и методы, которые позволяют выполнять такие операции, как
создание базы данных, определение таблиц и индексов, задание связей между таблицами, формирование запросов и отчетов и т. п. Существенным достоинством объектной модели DАО является ее универсальный характер: она
доступна для большинства средств разработки программного обеспечения,
поддерживаемогоMicrosoft, в частности, для Visual Basic. Классы объектов
доступа к данным организованы по иерархической схеме. На ее вершине находится объект DB Engine, представляющий собой ядро базы данных. Далее
следуют объекты, отвечающие за управление сеансами доступа пользователя
к данным, – Workspace (от англ. «рабочая область»). Каждая рабочая область
включает один или несколько объектов класса база данных – Database, а они,
в свою очередь, содержат семейства объектов таблиц (TableDef), запросов
(QueryDef), наборов записей (RecordSet) и т. д.
В заключение раздела, посвященного модулям, отметим, что вопросы
теории и практики создания программ на VBA в среде Access не затрагиваются в данном пособии, так как они являются весьма обширными. В случае
необходимости с ними можно ознакомиться в специальных профессиональных изданиях и руководствах.
7.3. Организация защиты данных в СУБД MS Access
MS Access обеспечивает два традиционных способа защиты базы данных:
установка пароля, требуемого при открытии базы данных;
защита на уровне определения прав пользователей, которая позволяет
ограничить возможность получения или изменения той или иной информации в базе данных для конкретного пользователя.
Кроме того, можно удалить изменяемую программу Visual Basic из базы данных, чтобы предотвратить изменения структуры форм, отчетов и модулей, сохранив базу данных как файл MDE.
89
Установка пароля на открытие базы данных представляет собой простейший способ защиты. После того как пароль установлен (функция меню
Сервис > Защита> Задать пароль базы данных), при каждом открытии базы
данных будет появляться диалоговое окно, в котором требуется ввести пароль.
Открыть базу данных и получить доступ к ее ресурсам могут получить только
те пользователи, которые введут правильный пароль. Этот способ достаточно
надежен (MS Access шифрует пароль, так что к нему нет прямого доступа при
чтении файла базы данных). Однако проверка проводится только при открытии базы данных, после чего все ее объекты становятся полностью доступными. В результате, установка пароля обычно оказывается достаточной мерой
защиты для БД, которые совместно используются небольшой группой пользователей или установлены на автономном компьютере.
Гораздо более надежным и гибким способом организации защиты является защита на уровне пользователей. Он подобен способам, используемым в
большинстве сетевых систем. Процесс задания защиты на уровне пользователей состоит из двух принципиальных этапов:
создание системы пользователей, объединенных в группы (Сервис >
Защита > Пользователи и группы);
задание прав доступа различных пользователей и групп по отношению
к объектам базы данных (Сервис > Защита > Разрешения).
Информация о системе пользователей сохраняется в специальном файле,
называемом файлом рабочих групп. По умолчанию это файл System.mdw. Однако с помощью специальной программы, входящей в поставку Access, различные базы данных можно ассоциировать с различными файлами рабочих
групп. При запуске Access от пользователей требуется идентифицировать себя
и ввести пароль. Отдельные пользователи могут объединяться в группы, причем один и тот же пользователь может являться членом различных групп. Такая организация системы пользователей позволяет весьма гибко манипулировать набором их прав доступа, исходя из функциональной специфики предметной области. В файле рабочих групп Access по умолчанию создаются две
группы: администраторы (группа Admins) и группа Users, в которую включаются все пользователи. Допускается также определение других групп. Процесс создания системы пользователей и определения их принадлежности к
группам показан на рис. 57.
Как группам, так и пользователям предоставляются разрешения на доступ, определяющие допустимые для них действия по отношению к каждому
объекту базы данных. Набор возможных прав, очевидно, определяется спецификой объекта.
По умолчанию члены группы Admins имеют все разрешения на доступ
ко всем объектам базы данных. Поскольку группа Users объединяет всех пользователей, то ей имеет смысл присваивать некоторый минимальный набор
прав. Далее имеется возможность установить более разветвленную структуру
90
управления, создавая собственные учетные записи групп, предоставляя этим
группам соответствующие разрешения и добавляя в них пользователей. Процесс задания прав доступа пользователей по работе с формами базы данных
TradeTest показан на рис. 58.
Рисунок 57 – Задание системы пользователей
Рисунок 58 – Задание прав пользователей
91
8 ОСНОВЫ ИСПОЛЬЗОВАНИЯ ЯЗЫКА СТРУКТУРИРОВАННЫХ ЗАПРОСОВ
8.1 Структурированный язык запросов Transact-SQL
Язык SQL на сегодняшний день является стандартом языков манипулирования реляционными данными. Разработка языка началась в середине 70-х
годов компанией IBM. Первоначально язык был назван SEQUEL (Structured
English Query Language – структурированный английский язык запросов), однако в 1980 году был переименован в SQL (Structured Query Language – структурированный язык запросов). В настоящее время действует уже шестая версия стандарта SQL:2008.
В данном учебном пособии рассматривается диалект Transact-SQL, реализованный в Microsoft SQL Server.
В соответствии со стандартом все команды SQL определены в подразделы:
Data Definition Language (DDL) –язык определения данных содержит
ко-манды создания, изменения и удаления объектов базы данных, таких как
таблицы, индексы, представления и др.;
Data Manipulation Language (DML) –язык манипулирования данными
содержит команды извлечения и изменения данных, хранящихся в таблицах;
Data Control Language (DCL) –язык управления данными включает в себя
команды предоставления пользователю привилегий доступа или их отмены.
Идентификаторы
Идентификатор используется для определения объектов, таких как базы
данных, таблицы, столбцы, переменные.
В Transact SQL определено два класса идентификаторов:
обычные идентификаторы;
идентификаторы с разделителем.
Обычные идентификаторы не разделяются при использовании в инструкциях языка Transact-SQL.
Существуют следующие правила задания обычного идентификатора:
Идентификатор может включать любые символы, кроме запрещенных символов, к которым относятся: ― ―(пробел), ‖(―, ―)‖, ―{―, ―}‖,
―!‖, ―%‖, ―&‖, ―~‖, ―^‖, ―-―, ―.‖, ―\‖, ― ‗ ― (апостроф).
В идентификатор не должны входить слова, являющиеся зарезервированными.
Первым символом в идентификаторе может быть:
буква латинского, национального алфавита или символ «_»;
символ ―@‖ в идентификаторах временных переменных или символ ―#‖ в идентификаторах временных таблиц и хранимых процедур.
Длина идентификатора от 1 до 128 символов.
92
Идентификаторы, не соответствующие правилам формата обычных
идентификаторов, называются идентификаторами с разделителем. В качестве
разделителей могут быть использованы квадратные скобки ([ ]) или двойные
кавычки ("). Например:
[номер группы], [% вклада] или
"номер группы", "% вклада"
Один и тот же идентификатор может использоваться в качестве имен
объектов, которые хранятся в разных базах данных. Разным объектам одной
базы данных также может быть присвоено одно имя, если они принадлежат
разным пользователям. В этом случае для обращения к объекту нужно использовать полное имя. Полное имя объекта состоит из четырех идентификаторов:
[имя_сервера.][база_данных].[имя_схемы].имя_объекта
Имя сервера, базы данных и схемы называются квалификаторами имени объекта.
Схема является коллекцией объектов базы данных, которыми владеет
один пользователь.
Некоторые квалификаторы могут быть опущены, их позиции отмечаются точками, например:
lti.студент
В примере текущий пользователь обращается к своему объекту студент, хранящемуся в базе данных lti.
Константы
Константами называются постоянные величины, значения которых не
могут быть изменены.
Допускается использование числовых, десятично-шестнадцатеричных
и алфавитно-цифровых констант.
Числовые константы включают все целые числа, числа с фиксированной или плавающей точкой. Примеры числовых констант:
10; -15; 105.25; -0.48E3; 0,25E-2
Строковая константа представляет собой последовательность символов, заключенных в одинарные кавычки (апострофы).
Константы разрешается указывать явно в некоторых командах языка и
в выражениях.
Выражения
Выражение – это совокупность операндов и операторов.
Операндами в выражении могут быть: константы, скалярные функции,
имена столбцов таблицы, переменные и подзапросы. Подзапрос – это запрос,
данные которого используются другим запросом.
93
К арифметическим операторам относятся унарные операторы: (-) для
обозначения отрицательных чисел и (+) для обозначения положительных чисел. К бинарным арифметическим операторам относятся: сложение (+), вычитание (-), умножение (*), деление (/), остаток от деления (%).
Над операндами строкового типа можно выполнять единственную операцию (+) – конкатенацию (сложение или слияние строк).
Для сравнения значений используются следующие операторы: равно ―=‖, больше - ―>‖, меньше - ―<‖, меньше или равно - ―<=‖, больше или равно
- ―>=‖, не равно - ―<>‖.
Операторы сравнения можно использовать в логических выражениях
для задания ограничений и условий.
Ограничения и условия могут быть заданы сложными логическими выражениями. Сложные логические выражения строятся с использованием логических операторов: NOT – отрицание, AND – конъюнкция и OR – дизъюнкция. К логическим операторам относятся также:
BETWEEN – проверяет, принадлежит ли значение указанному диапазону;
LIКE – проверяет, соответствует ли значение указанному шаблону; IN –
проверяет, присутствует ли значение в указанном списке;
ISNULL – выполняет проверку на отсутствие значения;
ALL – выполняет проверку для набора данных, если условие выполнено для всего набора данных, возвращает значение TRUE;
ANY – выполняет проверку для набора данных, если условие выполнено хотя бы для одного элемента из набора данных, возвращает значение
TRUE;
EXISTS – проверяет существование данных.
Типы данных
Тип данных определяет, какого рода данные и какого диапазона значений
могут храниться в переменной или в столбце таблицы.
SQL Server предоставляет набор системных типов данных, определяющих все типы данных, которые могут использоваться в нем. Типы данных в
SQL Server объединены в следующие категории: точные числа, приблизительные числа, дата и время, символьные строки, двоичные данные и прочие
типы. В табл. 8 – 11 описаны свойства некоторых системных типов данных.
В дополнение к рассмотренным в таблицах типам важным является тип
table. Этот тип относится к категории прочих и применяется, главным образом, для временного хранения набора строк, возвращаемого в качестве результирующего набора. Переменные типа table могут использоваться в
функциях и хранимых процедурах.
94
Таблица 8 – Свойства точных типов
1
Десятичные типы предназначены для хранения чисел с фиксированным количеством знаков до и после запятой. Размер числа задается двумя значениями: точностью (p – общее количество цифр) и масштабом (s – количество
цифр после запятой).
Таблица 9 – Свойства приблизительных типов
2
Аргумент n определяет количество разрядов мантиссы. Если n имеет значение от 1 до 24, то поддерживается точность 7 цифр, а если n от 25 до 53,
то поддерживается точность 15 цифр.
95
Таблица 10 – Свойства типов даты и времени
С данными типа дата и время можно выполнять арифметические операции сложения и вычитания, и операции сравнения.
Таблица 11 – Свойства символьных типов данных
Функции SQL
Встроенные функции SQL предназначены для облегчения и ускорения
обработки данных. Особенностью является то, что они могут указываться
непосредственно в выражении. Все встроенные функции можно условно раз96
делить на группы: математические функции, строковые функции, функции
для работы с датами и др.
Приведем функции преобразования типов данных:
CAST (значение AS тип_данных)
CONVERT(тип_данных, значение)
Аргумент значение в функциях задает величину, которую необходимо
преобразовать.
8.1 Команды языка определения данных
Язык определения данных содержит команды, которые предназначены
для создания (CREATE), изменения (ALTER) и удаления (DROP) базы данных и ее объектов.
Создание таблицы
Создание новой таблицы выполняется командой CREATE TABLE. В
команде выполняется описание структуры таблицы, каждого столбца таблицы и ограничений целостности, которые должны устанавливаться для таблицы.
Синтаксис команды:
CREATE TABLE имя_таблицы
({ описание_столбца | имя_вычисляемого_столбца AS выражение |
ограничения_целостности_уровня_таблицы} [, ...] )
Значение вычисляемого столбца определяется выражением, которое
хранится в структуре таблицы. Изменять данные вычисляемого столбца
нельзя, поэтому для него не могут быть установлены ограничения целостности NOT NULL, UNIQUE, PRIMARY KEY, FOREIGN KEY и значение DEFAULT.
Синтаксис описания столбца таблицы имеет вид:
имя_столбца тип_данных [(размер)]
[{DEFAULT значение_по_умолчанию |
IDENTITY [(значение, шаг)]}]
[ограничения_целостности_уровня_столбца]
Где
DEFAULT – позволяет задать значение, присваиваемое столбцу по
умолчанию во вновь добавляемой строке;
IDENTITY – указывает, что создается столбец с поддержкой автоматической нумерации (столбец-счетчик). IDENTITY может быть задано только
для тех столбцов, которые имеют целочисленные или десятичные типы.
97
Вставка значений в столбец IDENTITY запрещена. В таблице может быть определен только один столбец-счетчик.
Существует две группы ограничений целостности, обрабатываемых
СУБД:
декларативные ограничения целостности, которые объявляются при
создании или изменении таблицы;
процедурные ограничения целостности, которые обрабатываются триггерами.
Декларативные ограничения целостности могут быть определены на
уровне таблицы или на уровне столбца. Ограничения на уровне столбца применяется только к одному столбцу. Каждому декларативному ограничению
целостности может быть присвоено имя.
Описание ограничений уровня столбца имеет следующий синтаксис:
[ CONSTRAINT имя_ограничения]
{ { PRIMARY KEY | UNIQUE | NOT NULL }
| FOREIGN KEY REFERENCES имя_таблицы(имя_столбца)
[ ON UPDATE { NO ACTION|CASCADE| SET NULL|SET DEFAULT } ] [
ON DELETE { NO ACTION|CASCADE|SET NULL|SET DEFAULT } ]
|CHECK логическое_выражение }
Имя ограничения целостности данных должно быть уникальным в пределах базы данных. Рассмотрим ограничения, которые могут быть определены на уровне столбца:
ограничение по первичному ключу PRIMARY KEY. Все значения первичного ключа таблицы должны быть уникальными и отличаться от
значения NULL. В таблице может быть только один первичный ключ;
ограничения уникальности значения столбца UNIQUE. Это означает,
что в таблице не может быть двух записей, имеющих одно и то же значение в этом столбце;
ограничение NOT NULL, запрещающее хранить в столбце значение
NULL;
ограничение по внешнему ключу FOREIGN KEY (ограничение ссылочной целостности). Для столбца, который является внешним ключом,
с помощью REFERENCES указывается имя таблицы и имя столбца
этой таблицы, на которые указывает ссылка. Такая таблица является
главной (родительской) по отношению к создаваемой таблице. Для
столбца главной таблицы, по значениям которого устанавливается
связь, должно быть установлено ограничение PRIMARY KEY.
Если между таблицами устанавливается ссылочная целостность, то необходимо указать правила изменения связанных данных. Предложения
ONUPDATE и ON DELETE для внешнего ключа определяют следующие правила изменения связанных данных:
98
NO ACTION – разрешает изменять (удалять) только те значения в
главной таблице, которые не имеют соответствующих значений внешнего ключа в дочерней таблице. Это правило действует по умолчанию;
CASCADE означает, что каждое значение внешнего ключа дочерней
таблицы будет автоматически изменяться (удаляться) при модификации значения первичного ключа родительской таблице;
SETNULL означает, что в случае изменения (удаления) первичного
ключа родительской таблицы, во всех ссылающихся строках дочерней
таблицы значениям внешнего ключа будут автоматически присвоены
значения NULL;
SET DEFAULT означает, что в случае изменения (удаления) первичного ключа родительской таблицы, во всех ссылающихся строках дочерней таблицы значениям внешнего ключа будут автоматически присвоены значения по умолчанию.
Если первичный или внешний ключи таблицы являются составными,
то соответствующие ограничения должны задаваться на уровне таблицы.
Приведем запросы на создание таблиц учебной базы данных «Университет», проектирование которой рассматривалось в разд. 3.3. Будем руководствоваться инфологической моделью БД приведенной на рис. 14 и описаниями логической структуры таблиц (табл. 2 – 5).
Как видно из схемы БД (рис. 14) таблица ФАКУЛЬТЕТ является независимой таблицей, поэтому она создается первой. Запрос на создание таблицы с учетом описания логической структуры в табл. 4 будет иметь вид:
CREATE TABLE факультет
( [номер факультета] tinyint PRIMARY KEY, [наименование факультета] char(50) )
Таблица СПЕЦИАЛЬНОСТЬ также является независимой, ее соз-
даем второй. При создании запроса использует описание логической
структуры в табл. 5.
CREATE TABLE [специальность]
([номер специальности] int PRIMARY KEY,
[наименование специальности] char (60),
[стоимость обучения] [money])
Таблица ГРУППА является зависимой от ФАКУЛЬТЕТА и СПЕЦИАЛЬНОСТИ таблицей. Используем таблицу 3 при создании запроса и учтем,
что столбцы номер факультета и номер специальности являются внешними
ключами:
CREATE TABLE [группа] (
[номер группы] smallint PRIMARY KEY,
[номер специальности] int FOREIGN
99
KEY
REFERENCES
специальность(номер специальности) ON DELETE CASCADE ON
UPDADE CASCADE,
[номер факультета] tinyint FOREIGN KEY REFERENCES
факультет(номер факультета) ON DELETE CASCADE ON
UPDADE CASCADE, [номер курса] tinyint )
Таблица СТУДЕНТ является зависимой от ГРУППЫ таблицей. На основании данных таблицы 2 составим запрос. Также учтем, что столбец номер группы является внешними ключами:
CREATE TABLE [студент] (
[номер зачетной книжки] char(8) PRIMARY KEY,
[номер группы] smallint NOT NULL FOREIGN KEY
REFERENCES группа(номер группы),
[фамилия] char(15) NOT NULL ,
[дата рождения] datetime NOT NULL ,
[коммерческий] bit NOT NULL ,
[имя регистрации] char(9))
Изменение структуры таблицы
Изменение структуры таблицы выполняется командой ALTER TABLE.
С помощью команды можно выполнять изменение свойств существующих
столбцов, удалять их или добавлять в таблицу новые столбцы, управлять ограничениями целостности, как на уровне столбцов, так и на уровне таблицы.
Назначение многих параметров и ключевых слов аналогично назначению соответствующих параметров и ключевых слов команды CREATE TABLE.
Удаление таблицы
Удаление таблицы выполняется при помощи команды DROP TABLE.
Синтаксис команды:
DROP TABLE таблица
При удалении таблицы СЛЕДУЕТ учитывать связи, установленные в
базе данных между таблицами. Если на удаляемую таблицу с помощью ограничения целостности FOREIGN KEY ссылается другая таблица, то СУБД не
разрешит ее удаление.
8.2 Команды языка манипулирования данными
Выборка данных из таблицы
Выборка данных из таблицы (таблиц) выполняется командой
SELECT. При выполнении команды осуществляется поиск указанной таб100
лицы или таблиц, извлечение данных, соответствующих условию отбора,
их группировка или сортировка в указанном порядке и возвращение в виде
таблицы запроса. Команда SELECT не изменяет данные в базе данных.
Команда имеет синтаксис:
SELECT [предикат] список_столбцов
FROM имена_таблиц
[WHERE условие_отбора]
[GROUP BY критерий_группировки ]
[HAVING критерий_отбора]
[ORDER BY критерий_столбца]
Команда состоит из шести разделов. Два первых раздела являются обязательными, остальные включаются по необходимости.
В разделе SELECT указываются элементы данных, которые будут возвращены в результате запроса. Раздел имеет следующий синтаксис:
SELECT [ALL|DISTINCT] [TOP n [PERCENT]] список_столбцов.
Аргумент список_столбцов определяет список и происхождение столбцов (полей), значение которых будут возвращены в результате выполнения
команды. Список может быть задан одним из следующих способов:
{ [таблица.]* | [представление. ]* | [псевдоним.]* } – что означает выбрать все столбцы из таблицы или представления с указанием их имени или
псевдонима. Псевдонимом является другое имя таблицы (представления), которое может быть использовано в запросе для ссылки на таблицу.
{[таблица.]столбец выражение}[AS псевдоним][,...] –с помощью этого
способа можно указать имена столбцов, значение которых требуется получить в результате выполнения команды. Если имя столбца уникально среди
указанных таблиц, то перед именем столбца имя таблицы можно не указывать. С помощью выражения можно задать вычисляемый столбец. Значение
такого столбца будет вычисляться во время выполнения запроса. Столбцам
таблиц или вычисляемым полям можно присваивать псевдонимы. Они задаются по правилам именования объектов. Псевдонимы столбцов –это имена,
которые станут заголовками столбцов вместо исходных названий столбцов в
таблице результатов.
В разделе SELECT могут быть указаны предикаты ALL или DISTINCT.
Предикат – это выражение, которое может быть истинным,
ложным или неопределенным.
Предикат ALL используется для выбора всех строк, удовлетворяющих
условию отбора, и действует по умолчанию.
Предикат DISTINCT используется для исключения строк, содержащих
повторяющиеся значения в столбце.
101
Аргумент TOP n [PERCENT] указывает на необходимость выбора не
всех строк, а только первых n.
Раздел FROM определяет имена одной или нескольких таблиц или
представлений, которые содержат отбираемые данные.
Синтаксис раздела:
FROM {таблица [AS псевдоним]|представление [AS псевдоним][,…]}
Раздел WHERE позволяет задать правило отбора строк из таблиц, перечисленных в разделе FROM для включения их в результат выполнения команды SELECT.
Синтаксис раздела:
WHERE условие_отбора
Условие_отбора определяет логическое условие, при выполнении которого строка будет включена в результат.
Стандартом определены следующие предикаты (условия отбора):
предикат сравнения – проверяемое значение сравнивается со значением выражения;
предикат «между» – проверяется, попадает ли значение в указанный
диапазон;
предикат «в» – проверяется, совпадает ли значение с одним из значений заданного множества;
предикат «как» – проверяется, соответствует ли строковое значение
заданному шаблону;
«NULL – предикат» – проверяется, не содержится ли в столбце
значение NULL;
NULL – это специальное значение, представляющее собой отсутствие любого значения. Стандарт ANSY/ISO определяет, что результатом сравнения любого значения со значением NULL не могут
быть такие значения как TRUE или FALSE. Результатом сравнения будет UNKNOWN (неизвестно).
«Предикат существования» – проверяется, получены ли в результате
работы подзапроса одна или несколько строк.
Наиболее часто используется предикат сравнение. Проверяемое значение может сравниваться со значением другого столбца, константой, выражением, содержащим арифметические операторы, или с результатом подзапроса. Условие отбора может быть задано сложным логическим выражением, в
котором простые логические условия связанны логическими операторами,
такими как NOT, AND и OR.
Предикат «между» записывается с помощью оператора BETWEEN.
Синтаксис предиката:
выражение [NOT] BETWEEN значение1 AND значение2
Аргументы значение1 и значение 2 определяют начало и конец диа102
пазона значений и могут быть заданы числовыми, или символьными константами.
Для записи предиката «в» используется оператор IN. Синтаксис оператора:
выражение [NOT] IN {(значение1, значение2 [,…])| подзапрос}
Предикат «как» реализуется в языке оператором LIKE.
Оператор LIKE выполняет проверку строкового значения (тип Char,
VarChar) на соответствие шаблону. Шаблон строится с помощью обычных и
подстановочных символов. Синтаксис оператора:
выражение [NOT] LIKE шаблон
«NULL – предиката» имеет синтаксис:
выражение IS [NOT] NULL
Раздел ORDER BY позволяет задать сортировку результатов запроса.
Синтаксис раздела:
ORDER BY критерий_столбца [{ASC|DESC}][,…]
Критерий_столбца задается именем столбца или его номером в списке столбцов. По значениям этого столбца будет упорядочена таблица результатов запроса. С помощью ключевых слов ASC и DESC можно указать
порядок сортировки (ASC – по возрастанию значений, DESC – по убыванию
значений). Сортировка может выполняться по значениям нескольких столбцов. Стандарт позволяет управлять порядком сортировки отдельно по каждому столбцу.
Выборка данных из таблицы с группировкой
Раздел GROUP BY указывает на необходимость группировки строк
таблиц по определенным критериям для выполнения вычислений над значениями строк таблицы попавшими в группу. Синтаксис раздела:
GROUP BY критерий_группировки
Критерий_группировки содержит имя одного, или нескольких столбцов, которые называются столбцами группировки. Столбцы группировки определяют, по какому признаку строки делятся на группы.
Как правило, группировка данных выполняется с целью получения
итоговых данных по некоторому признаку. Поэтому если в команде SELECT
указывается раздел GROUP BY, то в аргументе список_столбцов раздела
SELECT для одного или нескольких столбцов должна быть указана агрегатная (статистическая) функция.
Агрегатные (статистические) функции позволяют выполнять статистическую обработку данных. К ним относятся:
Функция AVG() – вычисляет среднее значение для группы значений.
Синтаксис функции: AVG ([выражение | DISTINCT имя_столбца])
Если задан предикат DISTINCT, то агрегирование выполняется только
для строк имеющих неповторяющиеся значения столбца.
103
Функция COUNT() – подсчитывает количество значений в группе.
Синтаксис функции: COUNT ({[DISTINCT] имя_столбца | * })
Если задан аргумент ‗*‘, то функция подсчитывает общее количество
строк независимо от того, содержат ли они значения NULL или нет.
Функция SUM() – выполняет суммирование всех значений указанного
столбца для каждой группы. Синтаксис функции:
SUM ([выражение | DISTINCT имя_столбца])
Функция MAX() – возвращает максимальное значение столбца в каждой группе. Синтаксис функции: MAX (выражение)
Функция MIN() – возвращает минимальное значение столбца в каждой
группе. Синтаксис функции: MIN (выражение)
SQL позволяет группировать результаты запроса на основании значения, полученного объединением значений нескольких столбцов. Однако SQL
обеспечивает только один уровень группировки.
Последовательность имен столбцов в разделе GROUP BY не обязательно должна соответствовать последовательности имен в списке SELECT.
Совместно с разделом GROUP BY команда SELECT может содежать
раздел HAVING для задания условия отбора групп строк. Синтаксис раздела:
HAVING критерий_отбора
Указанное в разделе HAVING условие отбора будет применяться к каждой строке, полученной в результате группировки данных. И только те из
них, для которых условие будет выполняться, попадут в таблицу результатов
запроса.
Выборка данных из нескольких таблиц
SQL позволяет получать данные, которые находятся в нескольких таблицах. Для этого в разделе FROM команды SELECT необходимо указать
имена таблиц, которые содержат нужные данные.
Соединение таблиц – это процесс формирования пар строк путем сравнения содержимого соответствующих столбцов.
Таблица, получившаяся в результате формирования пар строк и содержащая данные двух таблиц, называется соединением двух таблиц.
Для соединения таблиц можно использовать две различные формы:
- явный синтаксис соединения с помощью оператора JOIN, указанного
в разделе SELECT;
- неявный синтаксис соединения, когда условия каждой операции соединения определяется неявно в разделе WHERE.
Синтаксис неявного соединения таблиц:
SELECT список_столбцов
FROM таблица1 , таблица2
WHERE таблица1.столбец1 оператор таблица2.столбец1
104
Явный синтаксис соединения таблиц имеет вид:
FROM таблица1 { INNER | {LEFT|RIGHT|FULL} [OUTER] } JOIN
таблица2 ON таблица1.столбец1 = таблица2.столбец1
INNER JOIN указывает на выполнение внутреннего соединения строк.
{LEFT |RIGHT| FULL} [OUTER] JOIN используется для создания
внешнего соединения. Результатом этого соединения будут все пары строк,
соответствующие условию соединения, и строки, которые не нашли себе пару и имеющие в выходных столбцах значение NULL.
Пример. Получить сведения о наименовании тех специальностей, на
которых больше одной группы студентов.
SELECT
[Наименование
специальности],
COUNT([Номер группы]) AS [количество групп]
FROM Специальность s INNER JOIN Группа g
ON s.[Номер специальности]=
g.[Номер специальности]
GROUP BY [Наименование специальности]
HAVING COUNT([Номер группы])>1
Подзапросы
SQL позволяет вкладывать запросы друг в друга. Такой механизм позволяет использовать результаты одного запроса в качестве составной части
другого.
Подзапрос (подчиненный запрос) – это запрос, содержащийся в
предложении WHERE, HAVING или FROM другого (основного) запроса.
Подзапрос отличается от обычного запроса тем, что возвращаемый
подзапросом результат можно использовать в качестве операнда выражения
или в более сложном запросе. Запрос с подзапросом зачастую является самым естественным способом выражения запроса, так как структура такого
запроса лучше всего соответствует словесному описанию запроса.
Наиболее часто подзапросы используются в качестве части раздела
WHERE или HAVING. В разделе WHERE значения, полученные в результате выполнения подзапроса, используются в критериях отбора строк из исходной таблицы или из результата соединения таблиц. В разделе HAVING
полученные в результате выполнения подзапроса значения используется для
отбора групп строк.
Подзапрос всегда заключается в круглые скобки . В качестве подзапроса может использоваться только команда SELECT, содержащая раздел FROM
и необязательные разделы WHERE, GROUP BY и HAVING.
Команда SELECT в подзапросе:
- может возвращать таблицу результатов, состоящую только из одного
значения столбца, или из столбца значений, или из нескольких столбцов;
105
- не должна содержать раздел ORDER BY. Так как результат подзапроса используется основным запросом, то не имеет смысла его сортировать;
- имена столбцов подзапроса могут являться ссылками на столбцы основного запроса.
Подзапрос не может быть запросом на объединение (UNION) нескольких команд SELECT.
Синтаксис критерия отбора имеет вид:
выражение [NOT] IN подзапрос
Критерий отбора может выполнять проверку на существование данных
подзапроса. Синтаксис проверки на существование:
EXISTS подзапрос
Оператор EXISTS проверяет, содержится ли в таблице результатов
подзапроса хотя бы одна строка. Если результат подзапроса содержит хотя
бы одну строку, то оператор возвращает значение TRUE, в противном случае
FALSE.
Подзапрос может возвращать столбец значений, в этом случае в разделе WHERE основного запроса должно выполнять многократное сравнение для
каждого значения, полученного в результате выполнения подзапроса. Синтаксис многократного сравнения:
выражение операция_сравнения {ANY|ALL} подзапрос
Оператор ANY выполняет проверку для каждого значения столбца, возвращенного подзапросом и, если условие выполнено хотя бы для одного значения из столбца, то возвращает значение TRUE.
Оператор ALL также выполняет проверку для каждого значения столбца,
возвращенного подзапросом, однако возвращает значение TRUE, если условие выполнятся для всех значений столбца.
Пример: Требуется вывести список студентов, обучающихся на специальности «Управление качеством»:
SELECT [Номер группы], Фамилия,
[Номер зачетной книжки]
FROM студент WHERE [Номер группы] IN
(SELECT [Номер группы] FROM Группа
WHERE [Номер специальности]=
(SELECT [Номер специальности]
FROM Специальность
WHERE [Наименование специальности]=
‘Управление качеством’))
Это пример «трехуровневого» запроса. Вложенный подзапрос возвращает номер специальности «Управления качеством». Подзапрос основного
запроса, используя это значение, находит и возвращает номера групп этой
специальности. Основной запрос включает в таблицу результатов сведения о
тех студентах, номера групп которых равны одному из возвращенных подза106
просом значений.
Стандарт не определяет максимальное число уровней вложенности,
однако когда запрос имеет более двух вложенных подзапросов, он становится трудным для понимания. Кроме этого, с увеличением числа уровней вложенности запросов увеличивается и время на их выполнение.
Коррелированные подзапросы
Подзапрос называется коррелированным подзапросом, если внутренний запрос зависит от внешнего запроса для всех его значений.
Пример: Определить сведения о студентах, каких групп отсутствуют в
таблице СТУДЕНТ.
SELECT [Номер группы] FROM Группа g
WHERE NOT EXISTS
( SELECT * FROM Студент s
WHERE s.[Номер группы]=g.[Номер группы] )
Имя столбца, не входящего ни в одну из таблиц подзапроса и принадлежащего таблице основного запроса, называется коррелирующей (внешней)
ссылкой. Подзапрос может иметь внешнюю ссылку на таблицу основного запроса независимо от его уровня вложенности. В этом случае в качестве
внешней ссылки следует указать полное имя столбца. В отличие от простого
подзапроса, коррелированный подзапрос логически выполняется каждый раз,
когда отыскивается новая строка внешнего запроса.
Стандарт разрешает использовать подзапросы в разделе FROM. В этом
случае подзапрос может возвращать множество столбцов . Если основной запрос содержит подзапрос в разделе FROM, то сначала выполняется подзапрос и по результатам его выполнения создается временная таблица. Затем
выполняется основной запрос, который использует эту временную таблицу в
качестве источника данных точно так же, как и обычную таблицу, хранящуюся в базе данных.
Добавление данных
Добавление данных в таблицу выполняется с помощью команд
INSERT INTO и SELECT INTO.
Команда INSERT INTO позволяет добавить одну или несколько строк
в уже существующую таблицу. Синтаксис команды на добавление строк:
INSERT INTO таблица [ (столбец1 [, столбец2 [, ...] ] ) ]
{ VALUES (значение1 [,значение2 [, ...] ) [,…] | запрос }
В списке столбец1,столбец2,… указываются имена столбцов, в которые команда будет добавлять значения. Если список столбцов отсутствует,
то вставка значений выполняется во все столбцы записи таблицы, начиная с
первой. Порядок следования имен столбцов в списке может не соответство107
вать их расположению в строке таблицы. Список может содержать не все
столбцы таблицы.
Раздел VALUES используется для добавления в таблицу одной или нескольких строк. Количество значений в разделе VALUES определяется списком столбцов. Значения могут быть заданы одним из способов:
{ значение|DEFAULT|NULL }
Значение DEFAUNT – это значение, определенное для столбца по
умолчанию при создании таблицы.
Значение NULL может быть помещено в столбец, если при создании
таблицы это было разрешено.
Пример: Добавить сведения о результатах сдачи экзаменов студентом в сессию.
INSERT INTO [Группа]
([Номер специальности],[Номер факультета],Курс)
VALUES (3801, 90900, 2, 4), (1111,221400, 4, 3)
Добавить в таблицу несколько строк можно с помощью запроса на извлечение данных (команда SELECT). Синтаксис команды:
INSERT INTO таблица [ ( столбец1[, столбец2 [, ...]] ) ]
SELECT столбец1[, столбец2[, ...]
FROM список_таблиц
Команда SELECT...INTO позволяет создать новую таблицу на основании данных, полученных по запросу. Структура создаваемой таблицы будет
соответствовать структуре запроса. В базе данных не должно существовать
таблицы, имя которой совпадает с именем таблицы, указанной в SELECT...INTO. Синтаксис команды:
SELECT столбец1[, столбец2[, ...]] INTO
новая_таблица
FROM список_таблиц
В списке определяются имена столбцов таблиц, значения которых будут включены в таблицу результатов. Имена столбцов в разделе SELECT
должны принадлежать одной из таблиц, перечисленных в списке FROM.
Пример: Создать таблицу ―Список групп‖, содержащую сведения о количестве студентов в группах специальности «Управление качеством».
SELECT c.[Номер группы], COUNT(Фамилия) as [Количество студентов]
INTO [Список групп]
FROM Студент c INNER JOIN Группа g ON c.[Номер группы]=g.[Номер группы] INNER JOIN Специальность s ON g.[Номер специальности]=s.[Номер специальности]
WHERE [Наименование специальности]=’Управление качеством’
GROUP BY c.[Номер группы]
SELECT * FROM [Список групп]
Изменение данных
108
Изменение данных выполняется с помощью команды UPDATE . Команда позволяет обновлять данные одного или нескольких столбцов таблицы
в одной или нескольких строках. Синтаксис таблицы:
UPDATE имя_таблицы
SET столбец= {новое_значение | DEFAULT | NULL} [,…]
[WHERE критерий_отбора]
SET определяет изменения, которые необходимо выполнить для одного, нескольких, или всех столбцов таблицы. Новое значение может быть задано выражением. Раздел WHERE задает условие отбора тех строк, которые
нужно изменить.
Пример: Создать запрос на изменение номера специальности «Управление
качеством».
UPDATE Специальность
SET [Номер специальности]= 221401
WHERE [номер специальности]=220501
Удаление данных
Для удаления данных из таблицы используется команда DELETE. Удаление данных выполняется построчно. За одну операцию можно удалить одну или нескольких строк. Синтаксис команды:
DELETE таблица
[WHERE критерий_отбора]
Пример: Создать запрос на удаление из таблицы Студент сведений о студенте Иванове из группы 1191.
DELETE Студент
WHERE [номер группы]=1191 AND Фамилия=’Иванов’
Если раздел WHERE отсутствует, команда удалит все строки таблицы.
Удаление всех строк из таблицы не приводит к удалению сомой таблицы.
9 ОСНОВНЫЕ ФУНКЦИИ И ТИПОВАЯ ОРГАНИЗАЦИЯ СОВРЕМЕННЫХ СИСТЕМ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ
9.1. Основные функции систем управления базами данных
Языково-программным средством управления БД является система
управления базами данных (СУБД).
Системой управления базами данных называют программную
систему, предназначенную для создания базы данных на ЭВМ, поддержания этой БД в актуальном состоянии и обеспечения доступа пользователей к содержащимся в ней данным.
По степени универсальности различают два больших класса СУБД:
системы общего назначения;
специализированные системы.
109
СУБД общего назначения не ориентированы на какую-либо предметную область или информационные потребности какой-либо группы пользователей . Каждая система такого класса реализуется как программное средство, способное функционировать на некоторой модели ЭВМ в определенной
операционной системе и поставляемое как программный продукт. Этим
СУБД присущи развитые функциональные возможности по организации,
хранению и управлению данными.
Специализированные СУБД создаются в редких случаях при невозможности или нецелесообразности использования СУБД общего назначения
(как, например, в военном деле).
К числу основных функций СУБД принято относить следующие:
управление данными во внешней памяти;
управление буферами оперативной памяти;
управление транзакциями;
журнализация и восстановление БД после сбоев;
поддержание языков БД.
Непосредственное управление данными во внешней памяти
Эта функция включает обеспечение необходимых структур внешней
памяти как для хранения данных, непосредственно входящих в БД, так и для
служебных целей, например, для ускорения доступа к данным в некоторых
случаях (обычно для этого используются индексы). В некоторых реализациях
СУБД активно используются возможности существующих файловых систем,
в других работа производится вплоть до уровня устройств внешней памяти.
Управление буферами оперативной памяти
СУБД обычно работают с БД значительного размера; по крайней мере,
этот размер обычно существенно больше доступного объема оперативной памяти. Понятно, что если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной
памяти. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной замены буферов.
Управление транзакциями Транзакция – это последовательность
операций над БД, рассматриваемых СУБД как единое целое.
Либо транзакция успешно выполняется, и СУБД фиксирует (COMMIT)
изменения БД, произведенные этой транзакцией, во внешней памяти, либо ни
одно из этих изменений никак не отражается на состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД. Поддержание механизма транзакций является обязательным условием даже однопользовательских СУБД. Но понятие транзакции гораздо более важно в мно110
гопользовательских СУБД.
С управлением транзакциями в многопользовательской СУБД связаны
важные понятия сериализации транзакций и сериального плана выполнения
смеси транзакций. Под сериализаций параллельно выполняющихся транзакций понимается такой порядок планирования их работы, при котором суммарный эффект смеси транзакций эквивалентен эффекту их некоторого последовательного выполнения. Сериальный план выполнения смеси транзакций – это такой план, который приводит к сериализации транзакций. Существует несколько базовых алгоритмов сериализации транзакций. В централизованных СУБД наиболее распространены алгоритмы, основанные на синхронизационных захватах объектов БД (блокировках). При использовании
любого алгоритма сериализации возможны ситуации конфликтов между
двумя или более транзакциями по доступу к объектам БД. В этом случае для
поддержания сериализации необходимо выполнять откат (ликвидировать все
изменения, произведенные в БД) одной или более транзакций.
Журнализация
Одним из основных требований к СУБД является надежность хранения
данных во внешней памяти.
Под надежностью хранения понимается то, что СУБД должна
быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя.
Поддержание надежности хранения данных в БД требует избыточности
хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным
методом поддержания такой избыточной информации является ведение журнала изменений БД.
Журнал – это особая часть БД, не доступная пользователям СУБД
и поддерживаемая с особой тщательностью, в которую поступают записи обо всех изменениях основной части БД.
Существуют разные модели восстановления баз данных, но их реализация невозможна без журнала транзакций и архивных копий БД.
Поддержка языков БД
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная
от ее создания, и обеспечивающий базовый пользовательский интерфейс с
базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL. Он содержит все необходимые механизмы для ведения реляционных баз данных.
Ниже приведены основные характеристики, которые составляют качество СУБД.
111
Производительность СУБД. Оценивается: временем выполнения запросов; скоростью поиска информации в неиндексированных полях; временем выполнения операций импортирования данных из других форматов; скоростью выполнения таких операций, как обновление , удаление и вставка;
максимальным числом параллельных обращений к данным в многопользовательском режиме.
Обеспечение целостности данных. Эта характеристика подразумевает наличие средств, позволяющих соблюдать правила целостности, установленные при создании БД и хранящиеся вместе с ней. Целостность данных
должна обеспечиваться независимо от того, каким образом данные заносятся
в память (в интерактивном режиме, посредством импорта или с помощью
приложения).
Обеспечение безопасности. Средства безопасности обеспечивают выполнение следующих функций: шифрование прикладных программ; шифрование данных; защиту паролем; ограничение уровня доступа (к БД, к таблице, к словарю).
Работа в многопользовательских средах. При этом предполагается,
что средства СУБД обеспечивают: блокировку БД, таблицы, записи, поля;
идентификацию станции, установившей блокировку; обновление информации после модификации; контроль времени и повторение обращения; обработку транзакций; работу с сетевыми системами (LAN Manager, NetWare,
Unix).
Импорт – экспорт. Эта характеристика отражает: возможность обработки информации, подготовленной другими программными средствами;
возможность использования данных другими программами.
Доступ к данным посредством SQL.СУБД имеют доступ к данным
посредством SQL в следующих случаях: БД совместима с ODBC (Open Data
Base Connectivity – соединение открытых баз данных); реализована естественная поддержка SQL; возможна реализация SQL-запросов локальных данных.
Разработка прикладных программ. Характеристика отражает возможность создания автономного приложения средствами СУБД. Большинство современных СУБД поддерживают эту возможность.
9.2. Типовая организация систем управления базами данных
Логически в современной реляционной СУБД можно выделить:
1) наиболее внутреннюю часть – ядро СУБД (часто его называют Data Base
Engine);
2) компилятор языка БД (обычно SQL);
3) подсистему поддержки времени выполнения;
4) набор утилит.
112
Ядро СУБД отвечает за управление данными во внешней памяти,
управление буферами оперативной памяти, управление транзакциями и журнализацию. Соответственно, можно выделить такие компоненты ядра (по
крайней мере, логически, хотя в некоторых системах эти компоненты выделяются явно), как менеджер данных, менеджер буферов, менеджер транзакций и менеджер журнала. Функции этих компонентов взаимосвязаны, и для
обеспечения корректной работы СУБД все эти компоненты должны взаимодействовать по тщательно продуманным и проверенным протоколам. Ядро
СУБД является основной резидентной частью СУБД. При использовании архитектуры «клиент-сервер» ядро является основной составляющей серверной
части системы.
Основной функцией компилятора языка БД является компиляция операторов языка БД в некоторую выполняемую программу. Результатом компиляции всегда является выполняемая программа, представляемая в некоторых системах в машинных кодах, но более часто в выполняемом внутреннем
машинно-независимом коде. В последнем случае реальное выполнение оператора производится с привлечением подсистемы поддержки времени выполнения, представляющей собой, по сути дела, интерпретатор этого внутреннего языка.
Наконец, в отдельные утилиты БД обычно выделяют такие процедуры,
которые не выполняются с использованием языка БД, например, загрузка и
выгрузка БД, сбор статистики, глобальная проверка целостности БД и т. д.
9.3. Архитектуры приложений, использующих базы данных
Наиболее актуальными на сегодняшний день являются архитектуры
«клиент-сервер». В архитектуре «клиент-сервер» (рис. 59) информационная
система делится на неоднородные части – сервер и клиент БД.
Рисунок 59 – Двухуровневая клиент-серверная архитектура информационной
системы («толстый» клиент)
В связи с тем, что компьютер-сервер распложен отдельно от клиента,
его также называют удаленным сервером. Существенно, что сервером назы113
вается как специальная программа, которая управляет БД, так и компьютер,
на котором установлены эти БД и программа.
Поскольку в основе организации запросов к БД лежит язык SQL,
то программу, управляющей БД, называют SQL-сервером, а БД –
базой данных SQL.
Клиентом является приложение пользователя, которое также называют
приложением-клиентом. Для обращения к данным приложение-клиент формулирует и отсылает запрос удаленному серверу, содержащему БД. После
получения запроса удаленный сервер направляет его SQL-серверу (серверу
баз данных). SQL-сервер обеспечивает выполнение за-проса и выдачу клиенту его результата – требуемых данных. Вся обработка запроса происходит на
удаленном сервере.
В роли SQL-сервера выступают СУБД, такие как InterBase, Oracle, Informix, Sybase, DB2, MS SQL Server и др.
Данная архитектура позволяет получить следующие преимущества:
снижение нагрузки на сеть; повышение уровня защищенности информации,
обусловленное тем, что обработка запросов всех клиентов осуществляется
единой программой, расположенной на сервере; снижение сложности клиентских приложений, в которых отсутствует код, связанный с контролем БД
и разграничением доступа к ней.
Рассмотренная архитектура является двухуровневой, в которой уровни
соотносятся с приложением-клиентом и сервером БД. В этой архитектуре
клиентское приложение называют сильным или «толстым» клиентом. Развитие «клиент-серверных» технологий привело к появлению трехуровневой архитектуры (рис. 60),в которой помимо сервера БД и приложений-клиентов
дополнительно присутствует сервер приложений.
Рисунок 60 – Трехуровневая клиент-серверная архитектура информационной
системы («тонкий» клиент)
114
Сервер приложений является промежуточным уровнем, который
обеспечивает организацию взаимодействия клиентов («тонких»
клиентов) и сервера БД.
К функциям сервера приложений могут, например, относиться: выполнение соединения с сервером, разграничение доступа к данным, реализация
бизнес-правил и т. д. Кроме того, сервер приложений может организовывать
взаимодействие с клиентами, установленными на различных аппаратных
платформах, функционирующих на компьютерах различного типа под
управлением разных информационных систем. Сервер приложений называют
также брокером данных.
Основные достоинства трехуровневой архитектуры «клиент-сервер»
состоят в следующем: разгрузка сервера БД; уменьшение размера клиентских
приложений за счет сокращения объема лишнего кода; единая линия поведения всех клиентов ; упрощение настройки клиентов – при изменении общего
кода сервера приложений автоматически меняется поведение приложений
клиентов.
115
ЛИТЕРАТУРА
1.
Федеральный закон Российской Федерации от 27 июля 2006 г. № 149-ФЗ
«Об информации, информационных технологиях и о защите информации»
2.
Агальцов, В. П. Базы данных. Книга 1. Локальные базы данных / В.П.
Агальцов. – М.: Форум, Инфра-М, 2011. – 352 с.
3.
Агальцов В.П. Базы данных. Книга 2. Распределенные и удаленные базы
данных / В.П. Агальцов. – М.: Форум, Инфра-М, 2011. – 272 с.
4.
Бен-Ган, Ицик. Microsoft SQL Server 2008. T – SQL: учебный курс / Ицик
Бен-Ган. – СПб.: БХВ-Петербург, 2009. – 432 с.
5.
Бекаревич, Ю.Б. Самоучитель Access 2010 / Ю.Б. Бекаревич, Н.В. Пушкина. – СПб.: БХВ - Петербург, 2011. — 432 с.
6.
Гурвиц, Г.А. Microsoft Access 2010. Разработка приложений на реальном
примере / Г.А. Гурвиц. – СПб.: БХВ-Петербург, 2010. — 496 с.
7.
Информационные системы в экономике / под ред. Г. А. Титоренко. – М.:
Инити-Дана, 2008. – 463 с.
8.
Кириллов, В. В.,. Введение в реляционные базы данных / В.В. Кириллов,
Г.Ю. Громов. – СПб.: БХВ-Петербург, 2009. – 464 с
9.
Кузин, А.В. Базы данных: учебное пособие. – 4-е изд. / А.В. Кузин,
С.В. Левонисова. – М.: Академия, 2010. – 320 с.
10. Мердина, О.Д. Информационное обеспечение, базы данных: учебное пособие / О.Д. Мердина, Е.В. Стельмашонок, Н.Н. Быкова. – СПб. : Изд-во
СПбГЭУ, 2014. – 82 с.
11. Фуфаев, Э.В., Базы данных: учебное пособие / Э.В. Фуфаев, Д.Э. Фуфаев. – М.: Академия, 2011. – 320 с.
12. Петкович Д. Microsoft SQL Server 2008. Руководство для начинающих /
Д. Петкович. – СПб.: БХВ-Петербург, 2009, – 752 с.
13. Тарасов В.Л. Работа с базами данных в Access 2010. Часть 1: Учебнометодическое пособие / В.Л. Тарасов – Нижний Новгород: Нижегородский госуниверситет, 2014. – 126 с.
116
Кафедра системного анализа и информационных технологий
Учебное пособие
Базы данных
Халимон Виктория Ивановна
Мамаева Галина Александровна
Рогов Александр Юрьевич
Чепикова Вера Николаевна
___________________________________________________________
Отпечатано с оригинал-макета. Формат 60х90 1/16
Печ.л. 7,4. Тираж экз.
_____________________________________________________________
Санкт-Петербургский государственный технологический институт
(технический университет)
_____________________________________________________________
190013, Санкт-Петербург, Московский пр., 26
Типография издательства СПбГТИ(ТУ). Тел. 494-93-65
117