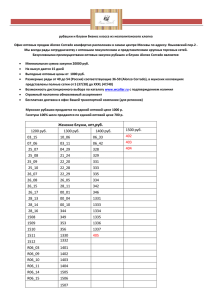
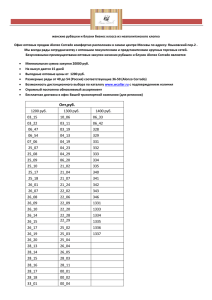
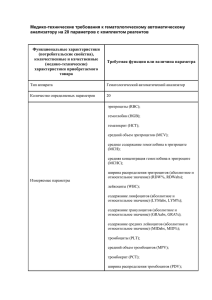
Важнейшие законы распределения дискретных и
непрерывных случайных величин
Сначала загрузим все необходимые для работы библиотеки
In [1]:
import
import
import
import
pandas as pd
numpy as np
matplotlib.pyplot as plt
scipy.stats as sts
matplotlib может выводить графики на экран разными способами (использовать различные backend).
Для построения графиков в Jupiter Notebook нам нужен backend, способный работать с браузером, т.е.
основанный на javascript. Чтобы его подключить нужна команда
In [2]:
%matplotlib inline
Разумеется, для работы с matplotlib в Spyder эта команда не нужна
Законы распределения непрерывных случайных
величин
Нормальное распределение
Сгенерируем выборку из значений нормально распределенной случайной величины с параметрами m
иσ
In [3]:
m=2
sigma=0.5
# создаем нормально распределенную случайную величину с именем norm_rv
# нормальное распределение - функция norm из пакета stats
norm_rv = sts.norm(m,sigma)
# сгенерируем 10 значений случайной величины
norm_rv.rvs(10)
Out[3]:
array([3.01138822, 2.68695265, 1.98464881, 1.88789464, 1.99915153,
1.91876321, 1.60921193, 2.38642799, 1.56853471, 2.06141442])
Для вычисления значения функции распределения F (x) в точке x используется функция cdf
In [4]:
norm_rv.cdf(2.2)
Out[4]:
0.6554217416103243
Мы знаем, что P (a < X < b) = F (b) − F (a) . Можем найти вероятность попадания нормально
распределенной случайной величины в интервал
In [5]:
norm_rv.cdf(3)-norm_rv.cdf(1)
Out[5]:
0.9544997361036416
Например, проверим правило "трех сигм": практически все возможные значения нормально
распределенной случайной величины принадлежат промежутку (m − 3 ⋅ σ; m + 3 ⋅ σ)
In [6]:
norm_rv.cdf(m+3*sigma)-norm_rv.cdf(m-3*sigma)
Out[6]:
0.9973002039367398
Построим график функции распределения F (x)
In [7]:
# формируем массив из 100 абсцисс точек в диапазоне от 0 до 4
x = np.linspace(0,4,100)
# считаем F(x) для каждого x
cdf = norm_rv.cdf(x) # функция cdf может принимать и вектор x
#cтроим график функции распределения
plt.plot(x, cdf)
# добавим названия для осей и графика
plt.ylabel('$F(x)$')
plt.xlabel('$x$')
plt.title("Функция распределения нормального закона")
Out[7]:
Text(0.5, 1.0, 'Функция распределения нормального закона')
Для вычисления значения функции плотности вероятностей f (x) в точке x используется функция
pdf
In [8]:
norm_rv.pdf(2.2)
Out[8]:
0.7365402806066466
Построим график функции плотности f (x) :
In [9]:
x = np.linspace(0,4,100)
pdf = norm_rv.pdf(x)
plt.plot(x, pdf)
plt.ylabel('$f(x)$')
plt.xlabel('$x$')
plt.title("Плотность вероятностей нормального закона")
Out[9]:
Text(0.5, 1.0, 'Плотность вероятностей нормального закона')
Посмотрим, как ведут себя нормально распределенные величины при разных значениях параметров.
Сначала исследуем влияния параметра m при фиксированном параметре σ = 1 .
In [10]:
sigma=1
x = np.linspace(-6,6,100)
for m in [-2, 0, 2]:
rv = sts.norm(m, sigma)
cdf = rv.cdf(x)
plt.plot(x, cdf, label="m=%s" % m) #аргумент label нужен для легенды
plt.legend() #добавим легенду
plt.title("Функция распределения нормального закона")
plt.ylabel('$F(X)$')
plt.xlabel('$x$')
Out[10]:
Text(0.5, 0, '$x$')
In [11]:
for m in [-2, 0, 2]:
rv = sts.norm(m, sigma)
pdf = rv.pdf(x)
plt.plot(x, pdf, label="m=%s" % m)
plt.legend()
plt.title("Плотность вероятностей нормального закона")
plt.ylabel('$F(X)$')
plt.xlabel('$x$')
Out[11]:
Text(0.5, 0, '$x$')
А теперь исследуем влияния параметра σ при фиксированном параметре m
= 0
.
In [12]:
m=0
x = np.linspace(-4,4,100)
for sigma in [0.5, 1, 2]:
rv = sts.norm(m, sigma)
cdf = rv.cdf(x)
plt.plot(x, cdf, label="sigma=%s" % sigma)
plt.legend()
plt.title("Функция распределения нормального закона")
plt.ylabel('$F(X)$')
plt.xlabel('$x$')
Out[12]:
Text(0.5, 0, '$x$')
In [13]:
x = np.linspace(-4,4,100)
for sigma in [0.5, 1, 2]:
rv = sts.norm(m, sigma)
pdf = rv.pdf(x)
plt.plot(x, pdf, label="sigma=%s" % sigma)
plt.legend()
plt.title("Плотность вероятностей нормального закона")
plt.ylabel('$f(X)$')
plt.xlabel('$x$')
Out[13]:
Text(0.5, 0, '$x$')
Равномерное распределение
Сгенерируем выборку из значений равномерно распределенной на отрезке [a, b] случайной величины
In [14]:
a = 1
b = 4
# создаем равномерно распределенную случайную величину с именем uniform_rv
# равномерное распределение - функция uniform из пакета stats
# обратите внимание, что в этой функции задается левая граница и масштаб, а не левая и
правая границы
uniform_rv = sts.uniform(a, b-a)
uniform_rv.rvs(10)
Out[14]:
array([1.28407581, 1.21311567, 3.76498308, 1.67015849, 2.3553841 ,
3.52769406, 3.44770038, 1.34517103, 2.90690785, 1.87110479])
Для вычисления значения функции распределения F (x) в точке x используется функция cdf , для
вычисления значения функции плотности вероятностей f (x) в точке x используется функция pdf
In [15]:
# значение функции распределения F(3)
uniform_rv.cdf(3)
Out[15]:
0.6666666666666666
In [16]:
# значение плотности вероятностей f(3)
uniform_rv.pdf(3)
Out[16]:
0.3333333333333333
Построим график функции распределения F (x)
In [17]:
x = np.linspace(0,5,100)
cdf = uniform_rv.cdf(x)
plt.plot(x, cdf)
plt.ylabel('$F(x)$')
plt.xlabel('$x$')
plt.title("Функция распределения равномерного закона")
Out[17]:
Text(0.5, 1.0, 'Функция распределения равномерного закона')
Построим график функции плотности f (x) :
In [18]:
x = np.linspace(0,5,1000)
pdf = uniform_rv.pdf(x)
plt.plot(x, pdf)
plt.ylabel('$f(x)$')
plt.xlabel('$x$')
plt.title("Плотность вероятностей равномерного закона")
Out[18]:
Text(0.5, 1.0, 'Плотность вероятностей равномерного закона')
Показательное (экпоненциальное) распределение
Сгенерируем выборку из значений случайной величины, имеющей показательное распределение с
параметром λ
In [19]:
lamda=0.3
# создаем случайную величину expon_rv c показательным распределением
# показательное распределение - функция expon из пакета stats
expon_rv = sts.expon(lamda)
uniform_rv.rvs(10)
Out[19]:
array([1.70228407, 3.63454393, 1.99370089, 2.03016075, 3.54813031,
1.85365909, 2.56362254, 3.2865129 , 3.73384582, 3.50411048])
Для вычисления значения функции распределения F (x) в точке x используется функция cdf , для
вычисления значения функции плотности вероятностей f (x) в точке x используется функция pdf
In [20]:
# значение функции распределения F(1)
expon_rv.cdf(1)
Out[20]:
0.5034146962085905
In [21]:
# значение плотности вероятностей f(1)
expon_rv.pdf(1)
Out[21]:
0.4965853037914095
Построим график функции распределения F (x)
In [22]:
x = np.linspace(-1,6,100)
cdf = expon_rv.cdf(x)
plt.plot(x, cdf)
plt.ylabel('$F(x)$')
plt.xlabel('$x$')
plt.title("Функция распределения показательного закона")
Out[22]:
Text(0.5, 1.0, 'Функция распределения показательного закона')
Построим график функции плотности f (x) :
In [23]:
x = np.linspace(-1,6,100)
pdf = expon_rv.pdf(x)
plt.plot(x, pdf)
plt.ylabel('$f(x)$')
plt.xlabel('$x$')
plt.title("Плотность вероятностей показательного закона")
Out[23]:
Text(0.5, 1.0, 'Плотность вероятностей показательного закона')
Законы распределения дискретных случайных величин
Биномиальное распределение
Сгенерируем выборку из значений случайной величины, имеющей биномиальное распределение с
параметрами n и p
In [24]:
n=20
p=0.7
# создаем случайную величину binomial_rv с биномиальным распределением
# биномиальное распределение - функция binomial из пакета stats
binomial_rv = sts.binom(n, p)
binomial_rv.rvs(10)
Out[24]:
array([16, 14, 13, 17, 13, 11, 15, 14, 11, 13])
Для вычисления значения функции распределения F (x) в точке x используется функция cdf
In [25]:
binomial_rv.cdf(14)
Out[25]:
0.5836291705525185
Построим график функции распределения F (x)
In [26]:
x = np.linspace(0,20,21)
cdf = binomial_rv.cdf(x)
plt.step(x, cdf)
plt.ylabel('$F(x)$')
plt.xlabel('$x$')
plt.title("Функция распределения биномиального закона")
Out[26]:
Text(0.5, 1.0, 'Функция распределения биномиального закона')
Для дискретных случайных величин используется функция вероятности pmf , считающая вероятность
P (x = x) случайной величине X принять значение x
In [27]:
binomial_rv.pmf(14)
Out[27]:
0.19163898275344177
Построим "многоугольник" распределения
In [28]:
x = np.linspace(0,20,21) # x = 0, 1, 2, ..., 19, 20
pmf = binomial_rv.pmf(x)
plt.step(x, pmf,'o') # 'o' в качестве "типа линии" означает рисовать точки кружочками и
не соединять их линиями
plt.ylabel('$P(X=x)$')
plt.xlabel('$x$')
plt.title("Вероятности биномиального закона")
Out[28]:
Text(0.5, 1.0, 'Вероятности биномиального закона')
Посмотрим, как ведут себя биномиально распределенные величины при разных значениях
параметров
In [29]:
x = np.linspace(0,20,23)
for n in [10, 20]:
for p in [0.2, 0.7]:
rv = sts.binom(n, p)
cdf = rv.cdf(x)
plt.step(x, cdf, label="$n=%s, p=%s$" % (n,p))
plt.legend()
plt.ylabel('$F(X)$')
plt.xlabel('$x$')
plt.title("Функция распределения биномиального закона")
Out[29]:
Text(0.5, 1.0, 'Функция распределения биномиального закона')
In [30]:
symbols = iter(['o', 's', '^', '+']) #круги для 1-ой линии, квадраты для 2-ой, треуголь
ники для 3-ей и плюсы для 4-ой
x = np.linspace(0,20,21)
for n in [10, 20]:
for p in [0.2, 0.7]:
rv = sts.binom(n, p)
pmf = rv.pmf(x)
plt.step(x, pmf, next(symbols), label="$n=%s, p=%s$" % (n,p))
plt.legend()
plt.ylabel('$P(X=x)$')
plt.xlabel('$x$')
plt.title("Вероятности биномиального закона")
Out[30]:
Text(0.5, 1.0, 'Вероятности биномиального закона')
Распределение Пуассона
Сгенерируем выборку из значений случайной величины, имеющей распределение Пуассона с
параметром λ
In [31]:
lamda=5
# создаем случайную величину poisson_rv с распределением Пуассона
# распределение Пуассона - функция poisson из пакета stats
poisson_rv = sts.poisson(lamda)
poisson_rv.rvs(10)
Out[31]:
array([4, 2, 5, 3, 5, 7, 6, 6, 3, 6])
Для вычисления значения функции распределения F (x) в точке x используется функция cdf
In [32]:
poisson_rv.cdf(3)
Out[32]:
0.2650259152973616
Построим график функции распределения F (x)
In [33]:
x = np.linspace(0,30,31) # x = 0, 1, 2, ...
cdf = poisson_rv.cdf(x)
plt.step(x, cdf)
plt.ylabel('$F(x)$')
plt.xlabel('$x$')
plt.title("Функция распределения закона Пуассона")
Out[33]:
Text(0.5, 1.0, 'Функция распределения закона Пуассона')
Для вычисления вероятность P (x
функция pmf
= x)
случайной величине X принять значение x используется
In [34]:
poisson_rv.pmf(3)
Out[34]:
0.1403738958142805
Построим "многоугольник" распределения
In [35]:
x = np.linspace(0,30,31)
pmf = poisson_rv.pmf(x)
plt.plot(x, pmf,'o')
plt.ylabel('$P(X=x)$')
plt.xlabel('$x$')
plt.title("Вероятности закона Пуассона")
Out[35]:
Text(0.5, 1.0, 'Вероятности закона Пуассона')
Распределение Бернулли
Сгенерируем выборку из значений случайной величины, имеющей биномиальное распределение с
параметром p
In [36]:
p=0.3
# создаем случайную величину bernoulli_rv c распределением Бернулли
# распределение Бернулли - функция bernoulli из пакета stats
bernoulli_rv = sts.bernoulli(p)
bernoulli_rv.rvs(10)
Out[36]:
array([0, 0, 0, 0, 1, 0, 0, 1, 0, 1])
Для вычисления значения функции распределения F (x) в точке x используется функция cdf
In [37]:
bernoulli_rv.cdf(0)
Out[37]:
0.7
Построим график функции распределения F (x)
In [38]:
x = np.linspace(0,1,2) # x = 0, 1
cdf = bernoulli_rv.cdf(x)
plt.step(x, cdf)
plt.ylabel('$F(x)$')
plt.xlabel('$x$')
plt.title("Функция распределения закона Бернулли")
Out[38]:
Text(0.5, 1.0, 'Функция распределения закона Бернулли')
Для вычисления вероятность P (x
функция pmf
= x)
случайной величине X принять значение x используется
In [39]:
bernoulli_rv.pmf(0)
Out[39]:
0.7000000000000001
Построим "многоугольник" распределения
In [40]:
x = np.linspace(0,1,2)
pmf = bernoulli_rv.pmf(x)
plt.plot(x, pmf,'o')
plt.ylabel('$P(X=x)$')
plt.xlabel('$x$')
plt.title("Вероятности закона Бернулли")
Out[40]:
Text(0.5, 1.0, 'Вероятности закона Бернулли')
Другие распределения
Полный список функций SciPy для работы со всеми распределениями можно найти тут:
http://docs.scipy.org/doc/scipy-0.14.0/reference/stats.html (http://docs.scipy.org/doc/scipy0.14.0/reference/stats.html)