Прослушали 1)РА, Реляционное исчисление 2)Знакомы с Firebird/MSSQL 3)Нормализация
реклама
РА, Реляционное исчисление 2)Знакомы с Firebird/MSSQL 3)Нормализация")
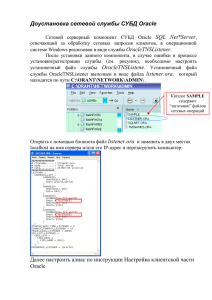
Прослушали 1)РА, Реляционное исчисление 2)Знакомы с Firebird/MSSQL 3)Нормализация 4)ER-модель 5)Средства моделирования 6)SQL 92 + некоторые его расширения 7) Общие вопросы оптимизации 8) Concurrency control 9) Целостность БД 10) NULL-значения 11) Двухфазная фиксация (?) Распределенные и интегрированные БД. 34 часа (17 пар?). Темы. 1) Нераспределенные и распределенные СУБД. Потребности в распределенных СУБД, классификация. Основные свойства распределенных БД. Репликация данных (на примерах Oracle, MSSQL, PostgreSQL). Промышленные интегрированные СУБД (на примере средств СУБД Oracle). (2 лекции – свойства распределенных БД/репликация и интегрированные БД, 1 практика – настройка репликации между Oracle и MSSQL) 2) Проблемы интероперабельности СУБД – совместимость SQL, нереляционные ИД (в том числе работа с WS, оптимизация работы с WS), совместимость схем. Определение отображения схем. Пример интеграции СУБД на основе работы с WS: работы Carrol и Calvo (1-2 лекции). 3) Обработка транзакций в распределенной среде: 2PC (presumed abort, presumed commit), 3PC, проблемы блокировки, Optimistic Commit Processing (1 лекция). 4) Различные подходы к интеграции данных. GAV (большинство СУБД), LAV(на примере Information Manifold), GLAV. . Проблема поддержания отображений схем (пример – работа R.McCann). (1.5 лекции) 5) Оптимизация запросов в интегрированной/распределенной СУБД. Основные проблемы. Борьба с устаревшей статистикой. Перекомпиляция запроса (POP/FED). Request Window (группировка запросов к одному ИД) (1.5 лекции). 6) NULL значения в распределенной среде и борьба с ними (Query Processing over Incomplete Autonomous Databases – вероятностный подход, Multiplex – обработка недоступности узлов) (1 лекция). 7) Использование онтологий в интеграции данных. Определение онтологий. Что они дают в области интеграции данных. RDF, OWL, (SPARQL?). Системы интеграции данных, использующие онтологии вместо схемы данных P2P системы интеграции данных. Работы Cruz и Xiao. Система интеграции данных Piazza. (3 лекции + практика – работа с онтологиями в Oracle 11g). Piazza 8) Управление моделями данных. Общие концепции. (Model Management 2.0, Composing Mappings Among Data Sources), полуавтоматические алгоритмы построения отображений. (лекция + практика с Oracle Data Integrator) Итого: 15 лекций + 3 практики Зачет – по билетам… 1. Введение Цель: описание основ построения распределенных систем, включая минимальные практические навыки. 1.1 Вводная лекция. Распределенные СУБД. Появление распределенных СУБД: 1) Территориальное распределение (Например, данные о продажах «Балтики». Центральный офис — в Питере, есть завод в Ростове и т.д.) 2) Рост БД, использование partitioning'а или кластера систем, как правило, связанного локальной сетью 3) Репликация БД с целью ее высокой доступности 4) Репликация части основной БД мобильными устройствами (ноутбук командированного сотрудника, работа на дому с БД и т.д.) 5) Исторически сложившиеся приложения на базе различных СУБД (интеграция данных). Основные свойства распределенных систем: локальная независимость, отсутствие опоры на центральный узел, непрерывное функционирование, независимость от расположения, независимость от фрагментации, обработка распределенных запросов, управление распределенными транзакциями, аппаратная независимость, независимость от ОС, независимость от сети, независимость от типа СУБД. 1.2 Репликация Организация репликации (master-slave, master-master). Oracle Streams. Модель подписок на публикации в SQL Server. Warm standby на базе WAL в PostgreSQL. 1.3 Пример интегрированных БД. Интегрированные БД. Oracle Transparent Gateway. Рассмотрение сценария репликации данных из схемы scott/tiger Oracle в SQL Server. 1.4 Практика: Настройка репликации из схемы scott/tiger Oracle в SQL Server. Литература: 1. К.Дж. Дейт «Введение в системы баз данных». Седьмое издание. Глава 20 «Распределенные базы данных» // Вильямс, 2001 2. J.Gray, P. Helland, P.O'Neil, D.Shasha. The Dangers of Replication and Solution //ACM SIGMOD 1996 3. MSDN. SQL Server replication // http://msdn.microsoft.com/enus/library/ms151198.aspx 4. Портал Oracle Data Replication and Integration // http://www.oracle.com/technology/products/dataint/index.html 5. PostgreSQL 8.3: Warm Standby Servers for High Availability // http://www.postgresql.org/docs/8.3/static/warm-standby.html 2. Проблемы интероперабельности СУБД. Цель: Дать понятие об основных проблемах при интеграции данных разнотипных источников, показать один из способов их решения. Проблемы интероперабельности СУБД. Пример схемы пользователей и подразделений в LDAP и соответствующей реляциионной схемы. Проблемы отображения схем. Отображение реляционных схем. Проблемы стандартизации: нестандартизированные расширения SQL (хранимые процедуры, процедурные языки). Отображение типов различных СУБД. Логические эквивалентные представления одной схемы. Формальное определение отображения схем. Обращение к Web-сервисам (WS) из CУБД. Поддержка WS путем создания специальных хранимых процедур (пример — экспериментальная поддержка WS в PostgreSQL). Интеграция СУБД с помощью Web-сервисов. Принципы построения оптимального DAG графа для определения порядка обращения к множеству зависимых WS. Литература: 1. P.A.Bernstein, S.Melnik. Model Management 2.0: Manipulating Richer Mappings //ACM SIGMOD 2007 2. N.L.Carrol, R.A.Calvo. Querying Data from Distributed Heterogeneous Database Syste ms through Web Services // AUSWEB 2004 3. U.Srivastava, K.Munagala, J.Widom, R.Motwani. Query Optimization over Web Services // VLDB 2006 3. Обработка транзакций в распределенной среде. Цель: Рассмотреть наиболее популярные алгоритмы фиксации распределенных транзакций, а также их модификации. Проблемы обеспечения ACID свойств транзакций в распределенной СУБД(атомарность, непротиворечивость, изоляция, долговечность). Невозможность создания надежного протокола фиксации транзакций в распределенной среде. Двухфазные алгоритмы фиксации (2PC). Presumed abort, presumed commit. Трехфазный алгоритм фиксации транзакций(3PC). Проблемы блокировки. Optimistic Commit Processing: уменьшение простоя путем позволения доступа на чтение грязных данных. Литература: 1. К.Дж. Дейт «Введение в системы баз данных». Седьмое издание. Глава 14 «Восстановление» // Вильямс, 2001 2. S.R.Gaddam Three-Phase Commit Protocol // http://ei.cs.vt.edu/~cs5204/sp99/distributedDBMS/sreenu/3pc.html#cond 3. R.Gupta, J.Haritsa, K.Ramamritham. Revisiting Commit Processing in Distributed Database Systems // ACM SIGMOD, 1997 4. Общие вопросы поддержки отображений схем источников данных(ИД). Цель: Разобрать основные подходы к отображению схем ИД. 4.1 Различные подходы к интеграции данных. Пример отображения GAV(Global As View). Общий вид отображений GAV (SQL и Datalog). Пример отображений LAV(Local As View). Общий вид отображений LAV(SQL и Datalog). Использование отображений LAV: проект Information Manifold. Сравнение подходов LAV и GLAV. GLAV: общий вид отображений(Datalog). Пример отображений. Алгоритм преобразования запросов к глобальной схеме в программы Datalog'а над отношениями локальных ИД. 4.2 Обнаружение нарушения отображений. Необходимость отслеживания изменений ИД. Рассмотрение проекта Maveric, предназначенного для обнаружения нарушения отображений. Общая архитектура системы Maveric, основанной на анализе показаний множества сенсоров. Виды используемых сенсоров. Тренировка сенсоров. Фильтрация ложных alarm'ов. Литература: 1. A.Y.Levy. The Information Manifold Approach to Data Integration //IEEE Intelligent Systems, 1998 2. M.Friedman, A.Levy, T.Millstein. Navigational Plans for Data integration //16th AAAI Conference, 1999 3. O.M.Duschka, M.R.Genesereth, A.Y.Levy. Recursive Query Plans for Data Integration //Journal of Logic Programming, 2000 4. R.McCann, R.AlShebli, Q.Le, H.Nguyen, L.Vu, A.Doan. Mapping Maintenance for Data Integration Systems //VLDB 2005 5. Оптимизация запросов в распределенных СУБД. Цель: Ознакомление с основами оптимизации запросов и методами оптимизации, специфичными для распределенных СУБД 5.1 Основы оптимизации запросов в распределенной СУБД. Основы оптимизации запросов. Статистика, необходимая для оптимизации. Селективность запросов. Ожидание селективности операций реляционной алгебры. Пространство поиска и упорядочивание операций JOIN. Виды соединений. Минимизация времени, затрачиваемого на коммуникацию. Передача отношений между узлами распределенной системы. 5.2 Разделение данных между различными транзакциями. Комбинирование cходных запросов к сторонним ИД (пакетная обработка). Борьба с устаревшей статистикой механизм оптимизации запросов POP/FED, используемый в IBM WebSphere Federation Server(DB2). Литература: 1. S.Chaudhuri. An Overview of Query Optimization in Relational Systems //Proceedings of the seventeenth ACM SIGACT-SIGMOD-SIGART symposium on Principles of database systems, pp. 34 — 43, 1998 2. P.Bezany. Optimization of Distributed Queries // http://www.par.univie.ac.at/~brezany/teach/gckfk/07ss/skriptum/070416-opt-distquery.ppt 3. Wikipedia: Join (SQL) (и связанные статьи) // http://en.wikipedia.org/wiki/Join_(SQL) 4. S.Even, H.Kache, V.Markl, V.Raman. Progressive Query Optimization for Federated Queries //Advances in Database Technology - EDBT 2006, Berlin, 2006 5. R.Lee, M.Zhou, H.Liao. Request Window: an Approach to Improve Throughput of RDBMS-based Data Integration System by Utilizing Data Sharing Across Concurrent Distributed Queries //VLDB 2007,Vienna,Austria 6. Неопределенные значения в распределенной среде Цель: Рассмотрение проблемы неопределенных значений в распределенной среде NULL значения в обычных СУБД. Важность неопределенных значений в интегрированных СУБД и причины их возникновения. Вероятностный подход к работе с неопределенными значениями (QPIAD – query processing over incomplete autonomus databases). Архитектура системы QPIAD. Приближенные функциональные зависимости. Алгоритм преобразования запросов в системе QPIAD. Расчет вероятных значений неопределенных значений. Литература: 1. К.Дж. Дейт «Введение в системы баз данных». Седьмое издание. Глава 18 «Отсутствующая информация» // Вильямс, 2001 2. G.Wolf, H.Khatri, B.Chokshi, J.Fan, Y.Chen, S.Kambhampati. Query Processing over Incomplete Autonomous Databases //VLDB 2007,Vienna,Austria 7. Технологии Semantic Web в области интеграции данных. Цель: получить представление о технологиях Semantic Web и о их значении в области интеграции данных 7.1 Технологии Semantic Web Потребность в P2P системах. Проблемы: синтаксические и семантические разнородности. Необходимость в расширенном языке описания данных. Онтологии: определение, языки описания: RDF, RDFS и OWL. Граф RDF. Триплеты RDF. Основные классы и свойства RDF Schema. Расширения RDF — OWL Lite, OWL DL, OWL Full, их основные конструкции. Примеры онтологии: винная онтология. 7.2 Использование онтологий в системах интеграции данных Способы использование онтологий в системах интеграции данных. Использование одной глобальной онтологии, использование множества онтологий, гибридный подход. Разбор основных свойств системы интеграции данных Piazza. Различные виды узлов системы. Язык описания отображений. Алгоритм ответа на запросы в системе Piazza. 7.3 Обзор framework'а Xiao и Cruz. Обзор framework'а Xiao и Cruz для создания систем интеграции данных, основанных на онтологии. Многослойная архитектура. Представление метаданных. Язык описания отображений. Язык запросов RQL и алгоритм ответа на запросы в рассматриваемом framework'е. 7.4 Практика - работа с онтологиями в Oracle 11g В ходе практики студенты знакомятся с пакетами разрабатывают собственную онтологию и реализуют работу с ней средствами пакета SEM_APIS в СУБД Oracle 11g. Литература: 1. Resource Description Framework (RDF):Concepts and Abstract Syntax // W3C Recommendation, http://www.w3.org/TR/rdf-concepts/ 2. RDF Vocabulary Description Language 1.0: RDF Schema // W3C Recommendation, http://www.w3.org/TR/rdf-schema/ 3. OWL Web Ontology Language Overview // W3C Recommendation, http://www.w3.org/TR/owl-features/ 4. I.Cruz, H.Xiao. The Role of Ontologies in Data Integration // Journal of Engineering Intelligent Systems, 13(4): 245-252, 2005 5. A.Halevy, Z.Ives, P.Mork, I.Tatarinov. Piazza: Data Management Infrastructure for Semantic Web Applications // Twelfth World Wide Web Conference, May 2003 6. H.Xiao, I.Cruz. Ontology-based Query Rewriting in Peer-to-Peer Networks //Proceedings of ICKEDS 2006, pp. 11-18, 2006 7. C.Murray. Oracle Database Semantic Technologies Developer's Guide 11g Release 1 // http://www.oracle.com/pls/db111/to_pdf?pathname=appdev.111/b28397.pdf 8. Управление моделями данных. Цель: Познакомиться с основами управления моделями данных и в частности с сопоставлением и отображением схем данных 8.1 Необходимость в инструментах управления отображениями схем. Высокозатратность работ, связанных с созданием и поддержанием отображений. Вероятностные и спроектированные (точные) отображения схем. Сферы применения: ETL(extract-transformload) утилиты, утилиты отображения сообщений, медиаторы в системах ИД, графически дизайнеры запросов и др. Система управления отображениями. Схемы, метамодели, формальное определение отображения. Сопоставление схем(Schema matching(напр., Cupid)). Определение отобажающего элемента (mapping element). Классификация систем сопоставления схем: по обрабатываемым схемам и используемой информации, по способам использования информации, по результатам сопоставления. Способы обнаружения одинаковых элементов схем: 1. Сопоставление элементов. Сравнение имен (токенизация строк, морфологический анализ, удаление незначащих символов), сравнение типов, сравнение кардинальностей значений, лингвистический анализ (использование тезауруса, цеопчек синонимов), использование предыдущих сопоставленных схем, 2. Сопоставление структур. Cопоставление графов, представляющих схемы(расстояние от сопоставленных объектов, сопоставление дочерних узлов, сопоставление листьев подграфа, сопоставление отношений между узлами), ведение репозитория сопоставленных структур, использование некоторых аксиоматических систем, характерных для области применения. Задача генерации преобразования схем. 8.2 Праккический пример – использование Oracle Data Integrator для преобразования схем двух БД и загрузки информации. Литература: 1. P.A.Bernstein, S.Melnik. Model Management 2.0: Manipulating Richer Mappings //SIGMOD 2007 2. P.Shvaiko, J.Euzenat. A Survey of Schema-based Matching Approaches //Journal on Data Semantics IV, pp. 146-171, 2005 3. Oracle Data Integrator Getting Started with an ETL Project // http://www.oracle.com/technology/products/oracle-dataintegrator/10.1.3/htdocs/documentation/oracledi_getting_started.pdf Приложение. База данных пользователей. Users (UID, Name, Surname, Login, Password, Email) Groups (GID, Name, Password) UR (UID,GID) LDAP: ou=USERS,dc=my,dc=domain uid=<UID>,ou=USERS,dc=my,dc=domain //Запись пользователя gid=<GID>,uid=<UID>,ou=USERS,dc=my,dc=domain //Запись группы Пример отображений LAV. Например, отображение схемы UserEmails локального ИД(Глобальная схема — та же, локальная - UserEmails (Login, Email)): UserEmails=SELECT Login,Email FROM Persons. Пример отображения GAV. База данных пользователей. Глобальная схема: Persons (Surname,Name, Login,Email). Persons = SELECT Surname,Name,Login,Email FROM Users, Groups,UR WHERE UR.GID=Groups.GID AND UR.UID=Users.UID AND Groups.name='main'