Тема 1. Среда анализа и визуализации статистических данных: пакет EXCEL,... Задача темы: дать слушателям курса ... дальнейшем будут осуществляться анализ статистических ...
реклама

Тема 1. Среда анализа и визуализации статистических данных: пакет EXCEL, пакет G7
Задача темы: дать слушателям курса представление о том языке, на котором в
дальнейшем будут осуществляться анализ статистических данных, построение моделей и
проводится прогнозно-аналитические расчеты. Для этого необходимо напомнить основные
возможности пакета EXCEL, а также дать первоначальные представления о возможностях
пакета G7, с тем, чтобы в дальнейшем иметь возможность проводить обработку
статистических данных, строить уравнения, собирать и компилировать модели,
осуществлять прогнозные расчеты в единой программной среде.
Приступая к изложению материала данной темы, рассмотрим вначале к основным
понятиям данного курса – прогноза.
a) Прогноз (понятие) – научно – обоснованное суждение о возможных состояниях
объекта в будущем и / или об альтернативных путях и сроках их достижения. Процесс
разработки прогнозов называется прогнозированием.
b) Принципы прогнозирования
Наиболее важными являются следующие требования, которые должны соблюдаться при
разработке прогнозов:
1) вариантность – разработка нескольких вариантов прогноза, исходя из
особенностей рабочей гипотезы, постановки цели (в нормативном
прогнозировании) и вариантов прогнозного фона;
2) верифицируемость – проверка достоверности, точности и обоснованности
прогнозов;
3) непрерывность – принцип прогнозирования, требующий корректировки методов
прогнозирования по мере необходимости при поступлении новых данных об
объекте прогнозирования;
4) рентабельность – превышение экономического эффекта от использования
прогноза над затратами на его разработку;
5) системность взаимная увязка всех прогнозируемых показателей, а также
параметров прогнозов;
6) согласованность – принцип прогнозирования, требующий согласования
нормативных и поисковых прогнозов различной природы и различного периода
упреждения.
c) Виды прогнозов (кратко-, средне-, долгосрочный, …).
Классификаци Вид прогноза
Комментарий
- онный
признак
1
2
3
Поисковый
Прогноз, содержанием которого является определение:
- возможных состояний объекта прогнозирования в
Содержание
будущем.
прогноза
Нормативный
- путей и сроков достижения возможных состояний
(принимаемых в качестве заданных).
Комплексный
Прогноз, содержащий элементы поискового и
нормативного прогноза.
Характер
Количествен
Прогноз, который базируется на:
отражаемых
ный
- количественных показателях
свойств
Качественный
Системный
Интервальный
Дискретность
Точечный
Период
упреждения
Количество
прогнозируемых характ.
Ареал
государства
(государств)
Структура
национальног
о хозяйства
Оперативный
Краткосрочны
й
Среднесрочны
й
Долгосрочный
Дальнесрочны
й
Одномерный
Многомерный
Локальный
Региональный
Межрегиональ
ный
Общегосударс
твенный
Межгосударст
венный
Глобальный
Отраслевой
Межотраслево
й
Террит.произв.
- качественных показателях
- системном представлении объекта прогнозирования
Прогноз, результат которого представлен в виде:
- доверительного интервала характеристики объекта
прогнозирования
- единственного значения характеристики объекта
прогнозирования без указания доверительного
интервала.
Прогноз с периодом упреждения для объектов
прогнозирования:
- до 1 месяца.
- от 1 месяца до 1 года.
- от 1 года до 5 лет.
- от 5 до 15 лет.
- свыше 15 лет.
Прогноз содержит:
-одну качественную или количественную
характеристику объекта прогнозирования.
- несколько качественных или количественных
характеристик объекта прогнозирования
Прогноз, относящийся к:
- части региона данного государства.
- региону данного государства
- нескольким регионам данного государства
- государству в целом
- нескольким государствам
Земле и человечеству в целом.
Прогноз, относящийся к:
- какой-либо отрасли
- нескольким отраслям
- териториально – производственным образованиям
d) Параметры прогнозов
1) Достоверность прогноза – оценка вероятности осуществления прогноза для
заданного доверительного интервала.
2) Источник ошибки прогноза – фактор, обуславливающий появление ошибки
прогноза;
3) Обоснованность прогноза – степень соответствия методов и исходной
информации объекту, целям и задачам прогнозирования;
4) Ошибка прогноза – апостериорная (из послеследующего) величина отклонения
прогноза от действительного состояния и объекта и путей и сроков его
осуществления;
5) Период упреждения – промежуток времени от настоящего в будущее, на который
разрабатывается прогноз.
6) Прогнозный горизонт – максимально возможный период упреждения прогноза.
7) Точность прогноза – оценка доверительного интервала прогноза для заданной
вероятности его осуществления.
После рассмотрения понятия прогноза, его параметров и видов, а также принципов
прогнозирования перейдем теперь к изложению основных возможностей пакета Excel,
которые Вам понадобятся в дальнейшем для построения Леонтьевской модели, ценовой
модели межотраслевого баланса, модели
оценки реального НДС и для работы с
эконометрическим пакетом G7. К таким основным возможностям отнесены нижеследующие
функции Excel:
1. Транспонирование данных (ТРАНСП () или TRANSPOSE() в англоязычной версии)
Возвращает вертикальный диапазон ячеек в виде горизонтального и наоборот. Функция
ТРАНСП должна быть введена как формула массива в интервал, который имеет столько
же строк и столбцов, соответственно, сколько столбцов и строк имеет аргумент массив.
Функция ТРАНСП используется для того, чтобы поменять ориентацию массива на
рабочем листе с вертикальной на горизонтальную и наоборот. Например, некоторые
функции, такие как ЛИНЕЙН, возвращают горизонтальные массивы. Функция ЛИНЕЙН
возвращает горизонтальный массив, содержащий данные о наклоне прямой и ее
пересечении с осью координат y. Следующая формула возвращает вертикальный массив,
получаемый из горизонтального массива, возвращаемого функцией ЛИНЕЙН:
ТРАНСП(ЛИНЕЙН(ЗначенияY;ЗначенияX))
Синтаксис
ТРАНСП(массив)
Массив — это транспонируемый массив или диапазон ячеек на рабочем листе.
Транспонирование массива заключается в том, что первая строка массива становится
первым столбцом нового массива, вторая строка массива становится вторым столбцом
нового массива и так далее.
2. Перемножение двух матриц (MУМНОЖ или MMULT). Возвращает произведение
матриц (матрицы хранятся в массивах). Результатом является массив с таким же числом
строк, как массив1 и с таким же числом столбцов, как массив2.
Синтаксис
МУМНОЖ(массив1;массив2)
Массив1, массив2 - это перемножаемые массивы.
Количество столбцов аргумента массив1 должно быть таким же, как количество
сток аргумента массив2, и оба массива должны содержать только числа.
Массив1 и массив2 могут быть заданы как интервалы, массивы констант или
ссылки.
Если хотя бы одна ячейка в аргументах пуста или содержит текст, или если число
столбцов в аргументе массив1 отличается от числа строк в аргументе массив2, то
функция МУМНОЖ возвращает значение ошибки #ЗНАЧ!.
3. Обращение матрицы (МОБР или MINVERSE) Возвращает обратную матрицу для
матрицы, хранящейся в массиве.
Синтаксис
МОБР(массив)
Массив - это числовой массив с равным количеством строк и столбцов.
Массив может быть задан как диапазон ячеек, например A1:C3; как массив констант,
например {1;2;3: 4;5;6: 7;8;9} или как имя диапазона или массива.
Если какая-либо из ячеек в массиве пуста или содержит текст, то функция МОБР
возвращает значение ошибки #ЗНАЧ!.
МОБР также возвращает значение ошибки #ЗНАЧ!, если массив имеет неравное
число строк и столбцов.
Замечания
Формулы, которые возвращают массивы, должны быть введены как формулы
массива.
Обратные матрицы, как и определители, обычно используются для решения систем
уравнений с несколькими неизвестными. Произведение матрицы на ее обратную —
это единичная матрица, то есть квадратный массив, у которого диагональные
элементы равны 1, а все остальные элементы равны 0.
В качестве примера того, как вычисляется обратная матрица, рассмотрим массив из
двух строк и двух столбцов A1:B2, который содержит буквы a, b, c и d,
представляющие любые четыре числа. В следующей таблице приведена обратная
матрица для A1:B2:
Столбец A Столбец B
Строка 1
d/(a*d-b*c) b/(b*c-a*d)
Строка 2
c/(b*c-a*d) a/(a*d-b*c)
МОБР производит вычисления с точностью до 16 значащих цифр, что может
привести к небольшим численным ошибкам округления.
Некоторые квадратные матрицы не могут быть обращены, в таких случаях функция
МОБР возвращает значение ошибки #ЧИСЛО!. Определитель такой матрицы равен 0.
4. ( Линейн или LINEST) Рассчитывает статистику для ряда с применением метода
наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом
аппроксимирует имеющиеся данные. Функция возвращает массив, который описывает
полученную прямую. Поскольку возвращается массив значений, функция должна
задаваться в виде формулы массива.
Уравнение для прямой линии имеет следующий вид:
y = mx + b или y = m1x1 + m2x2 + ... + b (в случае нескольких диапазонов значений x)
где зависимое значение y является функцией независимого значения x. Значения m — это
коэффициенты, соответствующие каждой независимой переменной x, а b — это
постоянная. Заметим, что y, x и m могут быть векторами. Функция ЛИНЕЙН возвращает
массив {mn;mn-1;...;m1;b}. ЛИНЕЙН может также возвращать дополнительную
регрессионную статистику.
Синтаксис
ЛИНЕЙН(известные_значения_y;известные_значения_x;конст;статистика)
Известные_значения_y — это множество значений y, которые уже известны в
соотношении y = mx + b.
Если массив известные_значения_y имеет один столбец, то каждый столбец массива
известные_значения_x интерпретируется как отдельная переменная.
Если массив известные_значения_y имеет одну строку, то каждая строка массива
известные_значения_x интерпретируется как отдельная переменная.
Известные_значения_x — это необязательное множество значений x, которые уже
известны в соотношении y = mx + b.
Массив известные_значения_x может содержать одно или несколько множеств
переменных. Если используется только одна переменная, то известные_значения_y и
известные_значения_x могут иметь любую форму, при условии, что они имеют
одинаковую размерность. Если используется более одной переменной, то
известные_значения_y должны быть вектором (то есть диапазоном высотой в одну
строку или шириной в один столбец).
Если известные_значения_x опущены, то предполагается, что это массив {1;2;3;...}
такого же размера, как и известные_значения_y.
Конст — это логическое значение, которое указывает, требуется ли, чтобы константа b
была равна 0.
Если аргумент конст имеет значение ИСТИНА или опущено, то b вычисляется
обычным образом.
Если аргумент конст имеет значение ЛОЖЬ, то b полагается равным 0 и значения m
подбираются так, чтобы выполнялось соотношение y = mx.
Статистика — это логическое значение, которое указывает, требуется ли вернуть
дополнительную статистику по регрессии.
Если аргумент статистика имеет значение ИСТИНА, то функция ЛИНЕЙН
возвращает дополнительную регрессионную статистику, так что возвращаемый
массив будет иметь вид: {mn;mn-1;...;m1;b:sen;sen1;...;se1;seb:r2;sey:F;df:ssreg;ssresid}.
Если аргумент статистика имеет значение ЛОЖЬ или опущена, то функция ЛИНЕЙН
возвращает только коэффициенты m и постоянную b.
Дополнительная регрессионная статистика
Величина
Описание
se1,se2,...,sen
Стандартные значения ошибок для коэффициентов m1,m2,...,mn.
seb
Стандартное значение ошибки для постоянной b (seb = #Н/Д, если
конст имеет значение ЛОЖЬ).
r2
Коэффициент детерминированности. Сравниваются фактические
значения y и значения, получаемые из уравнения прямой; по
результатам сравнения вычисляется коэффициент
детерминированности, нормированный от 0 до 1. Если он равен 1,
то имеет место полная корреляция с моделью, т.е. нет различия
между фактическим и оценочным значениями y. В
противоположном случае, если коэффициент
детерминированности равен 0, то уравнение регрессии неудачно
для предсказания значений y. Для получения информации о том,
как вычисляется r2, см. "Замечания" в конце данного раздела.
sey
Стандартная ошибка для оценки y.
F
F-статистика, или F-наблюдаемое значение. F-статистика
используется для определения того, является ли наблюдаемая
взаимосвязь между зависимой и независимой переменными
случайной или нет.
df
Степени свободы. Степени свободы полезны для нахождения Fкритических значений в статистической таблице. Для определения
уровня надежности модели нужно сравнить значения в таблице с
F-статистикой, возвращаемой функцией ЛИНЕЙН.
ssreg
Регрессионая сумма квадратов.
ssresid
Остаточная сумма квадратов.
Замечания
Любую прямую можно описать ее наклоном и пересечением с осью y:
Наклон (m):
Для того, чтобы определить наклон прямой, обычно обозначаемый через m, нужно
взять две точки прямой (x1,y1) и (x2,y2); тогда наклон равен (y2 - y1)/(x2 - x1).
Y-пересечение (b):
Y-пересечением прямой, обычно обозначаемым через b, является значение y для
точки, в которой прямая пересекает ось y.
Уравнение прямой имеет вид y = mx + b. Если известны значения m и b, то можно
вычислить любyю точку на прямой, подставляя значения y или x в уравнение. Можно
также использовать функцию ТЕНДЕНЦИЯ. Для получения более подробной
информации см. справку по функции ТЕНДЕНЦИЯ.
Если имеется только одна независимая переменная x, можно получить наклон и yпересечение непосредственно, используя следующие формулы:
Наклон:
ИНДЕКС(ЛИНЕЙН(известные_значения_y;известные_значения_x);1)
Y-пересечение:
ИНДЕКС(ЛИНЕЙН(известные_значения_y;известные_значения_x);2)
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН,
зависит от степени разброса данных. Чем ближе данные к прямой, тем более точной
является модель, используемая функцией ЛИНЕЙН. Функция ЛИНЕЙН использует
метод наименьших квадратов для определения наилучшей аппроксимации данных.
Функции аппроксимации ЛИНЕЙН и ЛГРФПРИБЛ могут вычислить прямую или
экспоненциальную кривую, наилучшим образом описывающую данные. Однако они
не дают ответа на вопрос, какой из двух результатов в наибольшей степени подходит
для решения поставленной задачи. Можно также вычислить функцию
ТЕНДЕНЦИЯ(известные_значения_y; известные_значения_x) для прямой или
функцию РОСТ(известные_значения_y; известные_значения_x) для
экспоненциальной кривой. Эти функции, если не задавать аргумент
новые_значения_x, возвращают массив вычисленных значений y для фактических
значений x в соответствии с прямой или кривой. Теперь можно сравнить
вычисленные значения с фактическими значениями. Можно также построить
диаграммы для визуального сравнения.
Проводя регрессионный анализ, Microsoft Excel вычисляет для каждой точки квадрат
разности между прогнозируемым значением y и фактическим значением y. Сумма
этих квадратов разностей называется остаточной суммой квадратов. Затем Microsoft
Excel подсчитывает сумму квадратов разностей между фактическими значениями y и
средним значением y, которая называется общей суммой квадратов (регрессионая
сумма квадратов + остаточная сумма квадратов). Чем меньше остаточная сумма
квадратов по сравнению с общей суммой квадратов, тем больше значение
коэффициента детерминированности r2, который показывает, насколько хорошо
уравнение, полученное с помощью регрессионного анализа, объясняет взаимосвязи
между переменными.
Формулы, которые возвращают массивы, должны быть введены как формулы
массивов. При вводе массива констант в качестве, например, аргумента
известные_значения_x, следует использовать точку с запятой для разделения
значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут
быть различными и зависят от установок для разных стран.
Значения y, предсказанные с помощью уравнения регрессии, возможно не будут
правильными, если они располагаются вне интервала значений y, которые
использовались для определения уравнения.
Практические задания и упражнения:
-
дайте понятия прогноза;
назовите основные принципы прогнозирования;
какие виды прогнозов Вы знаете;
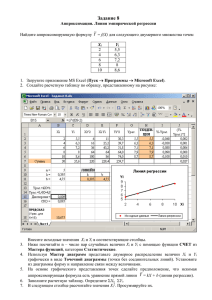
постройте в пакете EXCEL графики с использованием 2-х осей;
постройте в пакете EXCEL график зависимости y = f(x);
скопируйте формулу с фиксированием адреса строки;
скопируйте формулу с фиксированием адреса столбца;
скопируйте строку переменных в столбец, сохранив ссылки;
объясните назначение следующих функций пакета EXCEL: TRANSPOSE,
MMULT, MINVERSE, LINEST.
постройте в пакете EXCEL файл, в котором приведены примеры
использования следующих функций TRANSPOSE, MMULT, MINVERSE,
LINEST.
После разбора основных функций пакета Excel перейдем к рассмотрению основ
эконометрического пакета G7. Для знакомства с основами пакета G7 активизируйте
гиперссылку показать.
Практические задания и упражнения:
Какие параметры настройки есть в конфигурационном файле “G.cfg”?
Какие функции выполняют параметры настройки конфигурационного файла?
Какие компоненты входят в состав интегрированного пакета G7?
Назовите меню входящие в состав главного меню;
Опишите функции, входящие в состав меню File, Edit, Bank, Graph, Regression, Editor,
Model, Help;
Какие функции представлены на панели инструментов?
С помощью какой функции строится уравнение регрессии?
Что означают показатели уравнения регрессии SEE, RSQ, RHO, DW, Mexval, Elast,
NorRes, Beta?
Как построить в G7 график функции?
В чем различие между командами mgr, gr, gr*, gr resid, gr lever?
Каким образом сохраняется график в G7 (опишите два подхода)?
Опишите способы написания комментариев в G7;
С помощью какой функции осуществляется просмотр банка данных?
Как в G7 подключить несколько банков данных?
Какая команда позволяет подключить файл с данными?
Опишите основные этапы формирования файла с данными для подключения?
Перечислите основные ошибки, допускаемые при подключении файла с данными и
способы их устранения.
Какую функцию выполняет команда update?
Как осуществляется ввод новых переменных в банк данных?