Предлагаемая в настоящей работе методика является
реклама

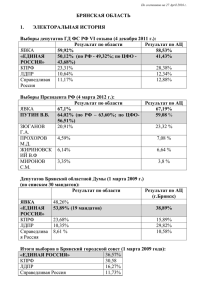
Сравнительное исследование предвыборных партийных программ 2007 и 2011 гг. на основе латентно-семантического анализа Е.Д.Корнилина, А.П.Петров Институт прикладной математики им. М.В.Келдыша РАН ekornilina@gmail.com, petrov.alexander.p@yandex.ru 1. Введение. Настоящий доклад посвящен сравнительному анализу предвыборных программ политических партий на выборах 2007 и 2011 годов в Государственную Думу, методика которого была предложена на XII Конференции по проблемам развития экономики и общества ([Петров, Корнилина, 2012], см. также, напр., [Kornilina, Petrov, 2010]). Сравнения проведены для четырех партий: Единая Россия, КПРФ, ЛДПР, Яблоко. Три из них традиционно представлены в Государственной Думе, мы также включили в круг рассмотрения программу Яблока, так как эта партия имеет репутацию «наиболее непохожей» на три других. Эта ожидаемая «непохожесть» послужила причиной того, что значительное место в докладе занимает сравнение ЕР и Яблока. Программы других (кроме четырех указанных) партий - участников выборов также могут быть включены в рассмотрение, методика не содержит ограничений на количество изучаемых партийных программ. Основой данной методики является латентно-семантический анализ (ЛСА) - метод анализа текстов естественного языка, разработанный группой американских ученых в 1988 году (см., напр., [Landauer et al, 1998]). Заметим, что ЛСА может быть реализован лишь программно, так как исследование даже сравнительно небольшого текста требует проведения довольно сложных и массивных вычислений, которые не могут быть проведены вручную. интеллектуального Основной поиска. Среди сферой других применения приложений ЛСА являются отметим задачи эпизодические исследования произведений художественной литературы [Nakov, 2001a, 2001b, 2001c]. Работы, использующие ЛСА в целях политического анализа, нам неизвестны. 2. Описание методики. Традиционные методики анализа и сравнения политических программ основаны на применении контент-анализа. Наиболее известная из них представлена в проекте “Manifesto” [Werner, Lacewell, Volkens], ее основным элементом является специального вида рубрикатор. Анализируя тексты, выражающие предвыборные партийные манифесты 1 (под которыми понимаются не только официальные предвыборные программы, но и прочие тексты, публикуемые партиями с целью привлечения избирателей), эксперты определяют позиции партий по различным пунктам рубрикатора, и в результате агрегирования получают для каждой из партий определенное числовое значение на так называемой шкале Rile (сокр. от right-left), имеющей пределы -100 (крайне левая партия) и 100 (крайне правая партия). Расположение политических позиций на прямой в настоящее время укоренено в политической науке, и было введено в [Downes, 1957], обзор современного состояния теории см., например, в [Ахременко, 2007]. Предлагаемая в настоящей работе методика является альтернативной прежде всего в том смысле, что она базируется не на контент-анализе, а на латенто-семантическом анализе (ЛСА). Кроме того, она предполагает попарное сравнение партийных программ, поэтому результат имеет вид расстояний между партийными позициями, а не их шкальных значений. ЛСА основан на «гипотезе о том, что между отдельными словами и обобщенным контекстом (предложениями, абзацами и целыми текстами), в которых они встречаются, существуют неявные (латентные) взаимосвязи, обуславливающие совокупность взаимных ограничений» [Митрофанова, 2005]. Наше предположение состоит в том, что данные взаимосвязи являются различными в текстах, выражающих различные политические позиции. Так, нетрудно представить себе, что фамилия политического деятеля употребляется, как правило, в положительном контексте его сторонниками, и в негативном – противниками. Это относится не только к фамилиям и названиям партий, но также к отдельным политическим событиям, проектам и т.д. Тем самым, выражающие политические позиции тексты могут быть классифицированы путем выделения контекста, в который эти тексты погружают отдельные слова. Вероятно, возможности ЛСА еще шире – как свидетельствуют наши эксперименты, не обязательно сравнивать различные тексты, посвященные одному и тому же узкому, локализованному вопросу. Например, при сопоставлении партийных программ нет необходимости сравнивать отдельно экономические разделы программ, отдельно – армейский вопрос и т.д. Различия между партийными программами оказываются достаточно явными и при сравнении программ «в целом». Наш оптимизм основан на известных результатах [Nakov, 2001a, 2001b, 2001c], свидетельствующих о том, что ЛСА способен улавливать довольно тонкие особенности текста – например, различия между произведениями Пушкина, Гоголя и Булгакова, различия между отдельными произведениями Гоголя и пр. 2 Контекст, в понимании ЛСА – это слова, близкие к данному слову по фактическому расположению в тексте. Более конкретно: исследуемый текст в целях проведения анализа нарезается на фрагменты, и контекст образуется всеми словами, входящими в один фрагмент с данным. Далее, ЛСА устанавливает для каждых двух фрагментов меру их близости, которую мы называем синтагматической близостью. Более подробно о синтагматическом подходе к измерению семантических расстояний в тексте и между тестами см. [Митрофанова, 2005] Фактически, наша основная гипотеза заключается в том, что близость политических позиций связана с синтагматической близостью текстов (фрагментов, образующих тексты), выражающих эти позиции. Остановимся более подробно на технологии ЛСА, точнее его варианта, реализованного в нашей работе. Входной информацией для ЛСА является единый текст, скомпонованный из последовательно расположенных анализируемых текстов предвыборных программ политических партий. В ходе предварительной обработки из этого текста изымаются так называемые стоп-слова (местоимения, предлоги, слова «конечно», «возможно», и пр.), а также слова, встречающиеся в нем лишь один раз. После предварительной обработки текст разбивается на отдельные фрагменты, и составляется матрица «фрагмент-слово», строки которой соответствуют фрагментам, столбцы – словам, а элемент матрицы имеет смысл количества употреблений данного слова в данном фрагменте. Заметим, что в анализе данных ее, как правило, называют матрицей «документ-терм» (в ранних работах, напр. [Landauer et al, 1998] – «word by context»), однако, имея в виду политологические приложения, мы предпочитаем избегать применения слова «документ» в смысле, отличном от «партийный документ», «закон» и т.д. Типичная размерность матрицы составляет, например, при попарном анализе партийных программ, от полусотни до немногим более 100 строк (в зависимости от выбранной длины фрагментов) и несколько тысяч столбцов (количество различных слов, встречающихся более одного раза в текстах программ двух партий, за вычетом стоп-слов). При этом удачный выбор длины фрагментов может сделать результат несколько более четким. Так, в более ранних исследованиях [Петров, Корнилина, 2012] мы рассматривали небольшие фрагменты по 30-40 слов, чтобы обеспечить достаточно большое количество фрагментов в одной партийной программе. В настоящей работе мы увеличили длину фрагментов, иногда до 100 слов; это позволило более четко визуально выделять отдельные программы (см., например, Рис.1). Фрагменты, существенно превышающие 100 слов, не использовались по причине того, что предвыборные программы представляют 3 собой сравнительно небольшие тексты. Заметим, что при исследованиях художественной литературы проблема выбора длины фрагмента стоит менее остро, так как размер повести или романа обычно позволяет произвести разбиение на весьма крупные фрагменты, оставляя достаточно большим и количество фрагментов. Матрица построчно нормируется на энтропию, и затем подвергается специальной математической процедуре, состоящей из (а) ее декомпозиции, сингулярного разложения (singular value decomposition, SVD), (б) обнуления младших сингулярных значений, (в) композиции, т.е. перемножения матриц – множителей. Результатом является новая матрица, строки которой по-прежнему соответствуют фрагментам, а столбцы – словам исходного единого текста. Суть данной математической процедуры можно пояснить на основе информационного подхода. Содержащаяся в том или ином сигнале (например, радиосигнале) полезная информация бывает, как правило, загрязнена шумом. Очистка сигнала проводится на основе предположения о том, что этот шум существенно слабее полезной информации. Проводится определенное разложение сигнала, затем малые компоненты отождествляются с шумом и обнуляются. Оставшиеся компоненты агрегируются в сигнал, который оказывается близким к изначальному, но очищенным от шума. С точки зрения данного подхода, ЛСА рассматривает матрицу «фрагмент-слово» как сигнал, а указанную математическую процедуру – как очистку этого сигнала от шума. Таким образом, новая матрица содержит в себе связи между различными фрагментами текста (анализ «фрагмент-фрагмент»), между различными словами (анализ «словослово»), и между фрагментами и словами (анализ из «фрагмент-слово»), в значительной мере очищенные от статистического шума. Соотношение близости между фрагментами исходного текста понимается как соотношение близости между векторами – строками этой новой матрицы; при этом будем говорить о синтагматической близости фрагментов. В свою очередь, в качестве синтагматического расстояния (меры близости между векторами) мы выбрали косинус угла между ними. Изложенная методика была реализована нами в виде программного продукта. 3. Диаграммы сходства. Одним из способов представления результатов анализа являются диаграммы, подобные изображенным на Рис.1. Каждому фрагменту соответствуют одна строка и один столбец диаграммы. Ячейка, находящаяся на пересечении, например, 10-ой строки и 254 ого столбца (так же, как ячейка 25-ой строки и 10-ого столбца) описывает степень синтагматической близости 10-ого и 25-ого фрагментов. При этом, чем более синтагматически близкими являются два фрагмента, тем более темным цветом закрашена ячейка. На Рис.1 фрагменты 1-15 принадлежат программе Единой России, фрагменты 16-46 – программе партии «Яблоко». Темный квадрат, составленный из строк и столбцов 1-15, свидетельствует о высокой синтагматической близости этих фрагментов, и в соответствии с нашей гипотезой – о близости высказанных в этих фрагментах политических позиций. Диаграмма также показывает, что в программе Яблока выделяются две части, каждая из которых обладает более высокой внутренней связностью, чем программа в целом. Граница между ними приходится на фрагмент 30. Более подробное рассмотрение показало, что она соответствует границе разделов II «Альтернатива – социальное государство» и III «Благосостояние для всех» программы Яблока. Подчеркнем, что граница между разделами II и III программы Яблока (как и граница между программами партий) определилась автоматически с помощью ЛСА; т.е. мы не делали никаких «подсказок» программному продукту относительно структуры единого текста. В то же время, границу между разделами I и II программы Яблока на диаграмме увидеть не удается, так как раздел II слишком мал – он занимает лишь часть фрагмента 28, весь фрагмент 29 и часть фрагмента 30. Рис.1. Диаграмма сходства для программ Единой России и Яблока на выборах 2007 года. Программа ЕР (фрагменты 1-15) четко отделена от программы Яблока, в которой можно выделить две внутренне связные части, соответствующие разделам I,II (фрагменты 16-30) и разделу III (фрагменты 31-46) 5 Перед дальнейшим обсуждением напомним, что в 2011 году на съезде Единой России было принято решение считать предвыборной программой тексты выступлений Д.Медведева и В.Путина. Априори можно было бы предположить, что выступление Д.Медведева, имеющего репутацию либерала, окажется более близким программе Яблока, чем выступление В.Путина. Однако латентно-семантический анализ показывает (Рис.2, показаны только строки, соответствующие программе Яблока), что это не так: пересечение «медведевских» столбцов 1-11 и «яблочных» строк 41-67 имеет более светлый тон, чем пересечение «путинских» столбцов и «яблочных» строк. Рис.2. Диаграмма сходства предвыборных программ ЕР и Яблока 2011 года (показаны только строки, соответствующие программе Яблока). Сопоставление программ КПРФ и ЕР 2011 года показывает, в частности, что они слабо различимы, если рассматривать программу ЕР как целое. Если же (Рис.3) рассмотреть корреляцию строк 1-26 (КПРФ) отдельно со столбцами 27-37 (Медведев) и 38-64 (Путин), то можно увидеть несходство программы КПРФ с выступлением Медведева, высокую близость с первой частью и несходство с последней частью выступления Путина. Рис.3. Диаграмма сходства предвыборных программ КПРФ и ЕР 2011 года (показаны только строки, соответствующие программе КПРФ). 4. Числовая мера синтагматической близости программ 6 Выше, в разделах 2 и 3 обсуждались вопросы сходства отдельных фрагментов, составляющих тексты программ: вычисление синтагматического расстояния и визуализация. В то же время, политологически более содержательной является мера сходства партийных программ в целом, агрегирующая данные о сходстве отдельных фрагментов. В качестве такой меры мы выбрали отношение нормированных на отрезок [0;1] средних синтагматических расстояний между фрагментами, входящими в разные программы и в одну и ту же программу. Обозначим синтагматическое расстояние между i-тым и j-тым фрагментами через rij , тогда нормированное на отрезок [0;1] расстояние равно 1 rij / 2 . Если на диаграмме сходства фрагменты первой программы занимают строки от 1 до N1 , а второй – от N1 1 до N1 N 2 , то сумма «внутренних» нормированных расстояний между 1 rij , второй программы 2 j 1 N1 N1 фрагментами первой программы равна i 1 N1 N 2 N1 N 2 1 rij i N1 1 j N1 1 2 2 2 . Всего таких внутренних расстояний N1 N 2 , поэтому среднее нормированное расстояние между фрагментами, входящими в одну и ту же программу, равно 1 rij N1 N2 N1 N2 1 rij 2 2 i N1 1 j N1 1 i 1 j 1 A 2 2 N1 N 2 N1 N1 Рассуждая аналогичным образом, получим выражение для нормированного расстояния между фрагментами, входящими в разные программы: 1 N1 N1 N2 1 rij B N1N 2 i 1 j N1 1 2 . Их отношение, нормированное на шкалу от 0 до 100, является мерой синтагматической близости программ: R 100B / A . При этом значения R от 0 до 50 являются скорее гипотетическими, так как соответствуют преобладанию отрицательных значений rij . Значения R>100 также являются гипотетически возможными, это означало бы, что фрагменты программы первой партии ближе к программе второй партии, чем к своей. Для реальных текстов следует ожидать значений R от 50 для наиболее далеких программ до 7 100 для наиболее близких. Отметим, что попадание эмпирических значений R в данный интервал может рассматриваться как аргумент в пользу валидности методики. Вычисленные таким образом значения R для предвыборных партийных программ четырех российских партий на выборах 2007 и 2011 годов сведены в Табл.1. и Табл.2. 2007 ЕР КПРФ ЛДПР Яблоко ЕР 0 99 92 87 0 95 91 0 91 КПРФ ЛДПР Яблоко 0 Табл. 1. Синтагматическая близость партийных программ 2007 года 2011 ЕР КПРФ ЛДПР Яблоко ЕР 0 87 91 89 0 96 85 0 90 КПРФ ЛДПР Яблоко 0 Табл. 2. Синтагматическая близость партийных программ 2011 года Полученные результаты свидетельствуют о довольно высокой близости программ указанных партий. Визуальное сопоставление построенных нами диаграмм сходства с результатами исследования произведений художественной литературы [Nakov, 2001а,2001b,2001c] также свидетельствует о том, что программы российских партий являются менее синтагматически разнообразными, чем художественные произведения. Вероятно, этого и следовало ожидать. Отметим также, что этот результат согласуется с результатами исследований проекта Манифесто [Werner, Lacewell, Volkens]. При том, что Rile-шкала проекта Манифесто простирается от -100 до 100, российские партии расположены на ней весьма кучно (кампания 2007 года): СР=-8,65; ЕР=-2,61; КПРФ=3,16; ЛДПР=16,59 (к сожалению, партия Яблоко не покрывается проектом Манифесто). Для сравнения укажем, что французские партии имеют Rile-шкальные значения (2007) от -48 до 28,49; итальянские (2006) – от -17,71 до 48,19. Проанализируем с помощью метода иерархической кластеризации данные Таблицы 1 в отношении того, какие партийные программы наиболее близки и далеки друг от друга. 8 Рис.4. Структура синтагматической близости программ 2007 и 2011 годов. В предвыборную кампанию 2007 года наиболее близкими были программы ЕР и КПРФ, а наиболее отдаленной от других – программа Яблока. В кампанию 2011 года произошла определенная перестройка: наиболее близкими были программы КПРФ и ЛДПР, а наиболее отдаленной от других – программа ЕР. Работа выполнена при поддержке РФФИ (проект 10-01-00332-а) и РГНФ (проект 12-03-00431). Список литературы Ахременко А.С. Структуры электорального пространства. М.: Социально-политическая мысль, 2007. 320 с. Митрофанова О.А. Семантические расстояния: проблемы и перспективы // XXXIV Международная филологическая конференция: Вып. 21. Прикладная и математическая лингвистика. СПб., 2005. Петров А.П., Корнилина Е.Д. Исследование близости политических позиций методом латентно-семантического анализа // XII Международная научная конференция по проблемам развития экономики и общества. Книга 2. М.: Издательский дом высшей школы экономики. 2012. С.334-342 Downes A. An economic Theory of Democracy. N.Y., Harper&Row, 1957 E. Kornilina, A. Petrov "Research of poitical blogs by means of LSA" // Intellectualization of information processing-2010 conf. proceedings – 2010 P. 508-511. T. Landauer, P.W. Foltz, D. Laham. Introduction to Latent Semantic Analysis. Discourse Processes 25: 259–284 (1998). Nakov P. Latent Semantic Analysis for German literature investigation. // Proceedings of the 7th Fuzzy Days'01, International Conference on Computational Intelligence. B. Reusch (Ed.): LNCS 2206. pp. 834-641. Dortmund, Germany. October 1-3, 2001a. Nakov P. Latent Semantic Analysis for Bulgarian Literature. In Proceedings of the Spring Conference of Bulgarian Mathematicians Union. pp. 279-284. Borovetz, Bulgaria. 2001b. 9 Nakov P. Latent Semantic Analysis for Russian literature investigation. In Proceedings of the Naval Scientific Forum, vol. 4 (Mechanical Engineering and Mathematics. Information Technology), pp. 292-299. Varna, Bulgaria. 2001c. A.Werner, O.Lacewell, A.Volkens. Manifesto coding instructions., http://manifestoproject.wzb.eu/ 10