21 БУЗА - Электронная библиотека БГУ
реклама

Математика и информатика
УДК 681.3
М.К. БУЗА, ЦЗЯХУЭЙ ЛЮ (КНР)
АВТОМАТИЗАЦИЯ ПРОЕКТИРОВАНИЯ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ
In this paper, a system of automatic designing parallel programs is considered. Some frequent useful loops have been analyzed.
The algorithm of parallelizing loop nests, which includes the mentioned type of loops, has been proposed and realized.
Сегодня существуют различные средства для проектирования и описания параллельных процессов
[1]. Разработаны специальные примитивы коммуникации и управления, позволяющие программисту
99
Вестник БГУ. Сер. 1. 2009. № 3
создавать сценарии параллельного исполнения программ; имеются расширения последовательных
языков специальными конструкциями, порождающими параллельные процессы (например, mpC,
HPF, HPC++, Cilk, Maisie, MPL и др.); созданы языки параллельного программирования (Java, NESL,
Orca, Sisal, ZPL и др.).
Можно воспользоваться специальными библиотеками (например, PVM, MPI и т. д.), позволяющими производить асинхронный обмен сообщениями между потоками и процессами [2].
Организовать параллельную обработку можно, используя системные функции операционной системы, такие, например, как Portable Operating System Interface for UNIX (POSIX). Это стандарты, описывающие интерфейсы между ОС и прикладной программой. В пределах POSIX параллельные вычисления реализуются на основе обмена сообщениями (как в MPI) или разделяемой памяти (как в
OpenMP).
Общий недостаток этих методов состоит в том, что большой объем работы по организации параллельной обработки возлагается на программиста. В связи с этим возникает задача его минимизации
при проектировании параллельных программ и организации параллельной обработки данных.
Организация параллельных вычислений предполагает разработку программной поддержки проектирования параллельных программ и эффективных методов планирования с учетом ограничений по
данным, управлению и ресурсам [3].
Количество строк кода для параллельной программы значительно превышает объем кода для последовательного исполнения при программировании одной и той же задачи. Параллельный подход
требует решения ряда дополнительных проблем, среди которых порождение и обработка синхронных
событий, параллельные потоки, планирование и т. д. Если речь идет о многоядерных процессорах, то
в этом случае могут использоваться различные модели многопроцессорности: асимметричная AMP
для обеспечения управления и отказоустойчивости; симметричная SMP, поддерживающая масштабируемость и максимальный параллелизм; исключительная BMP, снижающая трудоемкость построения
и миграцию кода.
Некоторые классы циклов
Основные вычисления в программе занимают циклы. В связи с этим для ускорения их обработки
тела циклов следует выполнять параллельно [4, 5].
Циклы в программах, спроектированных на языке Си, различаются по способам их организации,
структуре тела цикла, глубине вложенности, использованию переменных и констант и т. д. Ясно, что
в зависимости от указанных характеристик их параллельное исполнение будет иметь свои особенности.
Ниже предложена классификация рассматриваемых циклов, приведены примеры на языке Си и
указан один из возможных вариантов их параллельной реализации.
Тип 1. Цикл типа 1 характеризуется следующим:
1) в каждый цикл не входит переменная, кроме индекса цикла.
Например, “for(i=0;i<(цифра);i++){” ← цикл без переменных;
2) в теле самого внутреннего цикла находится линейный оператор, который имеет вид sum =
sum ⊕ (цифра) ← константа, где sum – переменные с типом данных “double”, “float”, “long” или “int”;
⊕ – арифметическая операция.
Под линейным оператором в общем виде будем понимать конструкцию типа x = B, где B – некоторое выражение.
Тип 2. Цикл типа 2 характеризуется следующим:
1) в каждый цикл не входит переменная кроме индекса цикла;
2) в теле самого внутреннего цикла находится линейный оператор, который имеет вид
sum = sum ⊕ (переменная); ← переменная.
(1)
Тип 3. Цикл типа 3 характеризуется следующим:
1) в каждый цикл входят переменные.
Например,“for(i=(переменная);i<(переменная);i++){” ← цикл с переменными;
2) в теле самого внутреннего цикла находится линейный оператор вида (1).
Тип 4. Особенность цикла в том, что в его теле находится линейный оператор следующего вида:
“sum = f (sum, i);”← линейная функция.
Функция f (sum, i) имеет вид: f (sum, i) = sum ⊕ (a* i), где a≠0, i – индекс цикла.
100
Математика и информатика
Тип циклов 1–4 включает их простейшую организацию. Дальнейшие особенности касаются структур тела циклов. В связи с этим рассмотрим особенности реализации тела цикла на реальных
примерах.
Тип 5. Пример: пусть требуется перемножить матрицы A и B, т. е. C = A×B.
∑ (a
n
Элемент cij матрицы С вычисляем по формуле cij =
k =1
ik
∗ bkj ) (i, j = 1, 2, ..., n).
Основная часть последовательной программы может быть записана следующим образом:
Цикл № 1: for(i=0;i<N;i++){ ← Цикл № 1 – самый внешний цикл.
Цикл № 2: for(j=0;j<N;j++){ ← Цикл № 2 находится в теле цикла № 1.
Цикл № 3:
for(k=0;k<N;k++){ ← Цикл № 3 находится в теле цикла № 2.
c[i][j]=c[i][j]+a[i][k]*b[k][j]; ← Линейный оператор – выражение
} } }
для вычисления сij.
Здесь N – количество строк матрицы С, массив “a” – матрица А, массив “b” – матрица B, массив
“c”– матрица C.
Цикл типа 5 характеризуется следующим:
1) вложенные циклы (цикл № 1, цикл № 2 и цикл № 3);
2) линейный оператор, который находится в теле цикла № 3, является выражением для вычисления (сij). Оно имеет вид c=c+a*b, где “c”, “a” и “b” – двухмерные массивы.
Тип 6. Пример: нахождение максимального и минимального значения в массиве.
Последовательная программа нахождения максимального значения в массиве может быть записана следующим образом:
for(i=(переменная);i<(переменная);i++){ ← Цикл с переменными.
if (s1<arr[i]){ (или if (arr[i]> s1) ) ← Условный оператор находится в теле цикла.
s1 = arr[i]; ← Линейный оператор находится в теле условного оператора.
} }
Здесь s1 – максимальное значение в одномерном массиве.
Цикл типа 6 характеризуется следующим:
1) это цикл с переменными;
2) в теле цикла находится условный оператор, который включает переменную и массив; переменная служит для хранения максимального или минимального значения в массиве;
3) в теле условного оператора находится линейный оператор. Переменная находится в его левой
части, массив – в правой части, т. е. входное множество – массив.
Существенные особенности в организации структур циклов можно заметить при решении следующих задач.
Тип 7 – упорядочение массивов по убыванию.
Тип 8 – упорядочение массивов по возрастанию.
Тип 9 – нахождение максимального и минимального значений в матрице по условиям.
Тип 10 – приближенное вычисление определенного интеграла.
Тип 11 – вычисление корня алгебраического уравнения методом Ньютона.
Тип 12 – целочисленные решения неопределенных уравнений методом перебора.
Тип 13 – решение системы линейных алгебраических уравнений методом Гаусса – Зейделя.
Тип 14 – вычисление обратной матрицы методом элементарных преобразований.
Основной алгоритм
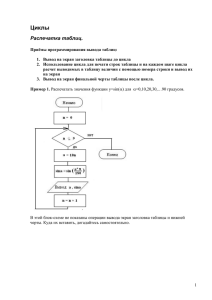
Общий алгоритм системы автоматизации проектирования параллельных программ (САППП) приведен на рис. 1.
Предлагаемая система предназначена для автоматизации процесса распараллеливания программ с
языков программирования типа Си на компьютеры параллельного действия. В ее основу положена
библиотека преобразования циклов, созданная на основе классификации типов циклов для распараллеливания гнезд циклов.
Чтобы объяснить этот алгоритм, рассмотрим пример приближенного вычисления определенного
интеграла
b
s = ∫ f ( x)dx.
(2)
a
1
Конкретизируем параметры интеграла. Пусть b = 1, a = 0 и f (x) = x. Тогда (2) примет вид s = ∫ xdx.
0
101
Вестник БГУ. Сер. 1. 2009. № 3
Рис. 1. Схема алгоритма САППП
Интервал (a, b) разобьем на N промежутков (xi, xi+1) длиной (b–a)/N. Пусть N=100. Тогда (2) будет
N
иметь вычислительный вид: s = ∑ si , где si = f(xi)*dx (dx=(b–a)/N). Пусть количество обрабатываюi =1
щих процессоров равно трем (рис. 2). Распределим вычисления по процессорам следующим образом.
На процессоре № 1 вычисляется множество {s1, s4, ... , s97, s100}.
На процессоре № 2 вычисляется множество {s2, s5, ... , s98}.
На процессоре № 3 вычисляется множество {s3, s6, ... , s99}.
Рис. 2. Вычисление определенного интеграла
Тогда гнездо циклов (тип 10) будет представлено следующим образом:
S1 : int i,N;
S2 : double s,dx,fx;
Первая часть – объявление данных.
S3 : s = (значение);
S4 : N= (значение);
S5 : dx = (значение);
Вторая часть – инициализация значений переменных.
S6 : fx = (значение);
S7 : for( i=0; i<(значение); i++){
S8 :
fx = (выражение);
Третья часть – вычисление определенного интеграла.
S9 :
s = s + si (si = fx *dx);
Эту часть можно выполнить параллельно.
S10 : }
102
Математика и информатика
Последовательная программа для реализации вычислений будет иметь вид
S1 : int i,N;
S2 : double s,dx,fx;
Первая часть – объявление данных.
S3 : s=0;
S4 : N=100;
S5 : dx=1.0/N;
Вторая часть – инициализация значений переменных.
S6 : fx=0;
S7 : for(i=0; i<N; i++){
S8 :
fx = i * dx;
Третья часть – вычисление определенного интеграла.
S9 :
s = s + fx*dx;
Эту часть можно выполнить параллельно.
S10 : }
Будем хранить исходную программу в текстовом файле.
Шаг 1. Главный процессор открывает текстовой файл и записывает исходную программу в одномерный массив в оперативной памяти в следующем виде (табл. 1).
Таблица 1
Запись исходной программы в памяти
№ в программе
Содержание
S1
S2
S3
S4
S5
S6
S7
S8
S9
S10
int i,N;
double s,dx,fx;
s=0;
N=100;
dx=1.0/N;
fx=0;
for(i=0; i<N; i++){
fx=i*dx;
s = s + fx*dx;
}
Шаг 2. Главный процессор анализирует тип используемых данных, которые состоят из констант,
переменных и массивов. Затем их начальные значения, имя и тип данных записываются в таблице
системных данных. Схема реализации шага 2 отражена на рис. 3.
а
б
Рис. 3. Алгоритм анализа типа данных:
а – алгоритм анализа констант; б – алгоритм анализа типа данных “int”, “long”, “float” и “double”
103
Вестник БГУ. Сер. 1. 2009. № 3
Рассмотрим реализацию алгоритма анализа констант на конкретных примерах. Пусть задана константа типа “#define N 100”. Если ключевым словом первой строки является “#define”, оно определяет константу. Выделяется ключевое слово первой строки – “#define”. За ключевым словом следует
имя данных “N”. За именем данных – его значение 100.
В первой строке табл. 2 системных данных записывается константа “N”.
Таблица 2
Таблица системных данных
№
1
Тип данных
const
Имя данных
N
Значение данных
100
Алгоритм анализа типа данных “int”, “long”, “float” и “double” показан на рис. 3 б.
Рассмотрим операторы S1 и S2 в исходной программе. Оператор S1 – “int i,N;”.
Во-первых, “int”– ключевое слово. Оно определяет целочисленную переменную. Во-вторых, “i”–
имя данных. Задаем начальное значение данных равным 0. В первой строке таблицы системных данных записывается переменная “i” (табл. 3). Если за переменной “i” следует символ “;”, это означает
конец оператора; если “,”, то далее следуют переменные. Во второй строке таблицы системных данных записывается переменная “N” (см. табл. 3).
Таблица 3
Таблица системных данных
№
Тип данных
Имя данных
Начальные значения данных
1
2
3
4
5
int
int
double
double
double
i
N
s
dx
fx
0
0
0
0
0
Оператор S2 анализируется аналогично S1.
Шаг 3. Анализ исходной программы с целью создания таблицы операторов. Таблица содержит
поля: номер оператора, оператор, тип оператора, принадлежность оператора телу цикла и глубина
вложения.
Выделим три класса операторов: линейный оператор, цикл и условный оператор.
а
б
в
Рис. 4. Анализ типа оператора:
а – оператора цикла; б – условного оператора; в – линейного оператора
В начале оператора цикла стоит ключевое слово “for”, которое находится в левой части знака “(”
(рис. 4 а). В начале условного оператора – ключевое слово “if”, которое находится в левой части знака “(” (рис. 4 б). Для линейного оператора в левой части знака “=” находится переменная (рис. 4 в). В
правой части знака “=” – выражение, включающее в себя операцию присваивания и/или арифметическую операцию.
Таблица 4
Таблица операторов
№
№ в программе
Оператор
Тип оператора
В теле цикла
Глубина вложения
1
2
3
4
5
6
7
8
S3
S4
S5
S6
S7
S8
S9
S10
s = 0;
N=100;
dx=1.0/N;
fx=0;
for(i=0; i<N; i++){
fx=i*dx;
s = s + fx*dx;
}
Линейный оператор
Линейный оператор
Линейный оператор
Линейный оператор
Заголовок цикла
Линейный оператор
Линейный оператор
Знак конца цикла
Нет
Нет
Нет
Нет
Нет
Да
Да
–
–
–
–
–
–
1
2
–
104
Математика и информатика
Рассмотрим оператор S3 “s = 0;”.
В левой части оператора S3 находится переменная “s”. За ней следует символ “=”, поэтому тип
оператора S3 – линейный. Операторы S4 и S6 анализируются аналогично S3.
Рассмотрим оператор S5 “dx =1.0/N;”.
В левой части оператора S5 находится переменная “dx”. За символом “=” следует арифметическое
выражение, поэтому тип оператора S5 – линейный. Операторы S8 и S9 анализируются аналогично S5.
Рассмотрим оператор S7 “for(i=0;i<N;i++){”.
Слева от символа “(” в операторе S7 находится ключевое слово “for”, поэтому оператор S7 принадлежит к типу «цикл». Операторы S8 и S9 находятся в теле цикла.
В табл. 4 приведена таблица операторов.
Шаг 4. Обнаружение информационной, логической и конкуренционной зависимости операторов.
Для реализации шага 4 основная часть программы представляется в виде ориентированного графа
G, множество вершин которого V={v1, v2, ..., vn} соответствует либо отдельным операторам программы либо совокупности некоторых операторов. Множество направленных дуг означает информационную, конкуренционную или логическую зависимость между операторами. Установление такой зависимости необходимо для корректного исполнения основной части программы в параллельном режиме. Так, в примере на с. 5 переменная N используется в основной части программы, а ее вычисление
осуществляется вне этой части.
Шаг 5. Формирование таблицы циклических операторов.
Для программы, приведенной выше, эта табл. 5 будет иметь вид:
Таблица 5
Таблица циклических операторов
№ в таблице
№ оператора в программе
Индекс цикла
Начальное значение переменной цикла
Конечное значение переменной цикла
Шаг изменения цикла
Тело цикла
1
S7
i
0
N
+1
S8, S9
Шаг 6. Создание таблицы условных операторов. Структура ее аналогична структуре табл. 5.
Шаг 7. Формирование таблицы исполнения программы. Она формируется на основе подготовленных таблиц.
Затем главный процессор распределяет работу по процессорам в соответствии с рис. 2. По окончании работы обрабатывающих процессоров главный процессор формирует окончательный результат
вычислений.
В заключение отметим, что разработанная библиотека преобразования рассмотренного множества
циклов в соответствии с их классификацией и основной алгоритм могут быть использованы при проектировании параллельных программ на достаточно широком классе современных языков программирования.
1. Б у з а М . К . Архитектура компьютеров. Мн., 2007.
2. Ш п а к о в с к и й Г . И . , С е р и к о в а Н . В . Программирование для многопроцессорных систем в стандарте MPI.
Мн., 2002.
3. В а л ь к о в с к и й В . А . , К о т о в В . Е . , М а р ч у к А . Г . , М и р е н к о в Н . Н . Элементы параллельного программирования М., 1983.
4. W o l f M . E . , L a m M . S . // IEEE Transactions on Parallel and Distributed Systems. October. 1991. Vol. 2. № 4. P. 452.
5. G r a m a A . , G u p t a A . , K a r y p i s G . , K u m a r V . Introduction to parallel computing second edition. AddisonWesley, 2003.
Поступила в редакцию 10.04.09.
Михаил Константинович Буза – доктор технических наук, профессор кафедры математического обеспечения ЭВМ.
Лю Цзяхуэй – аспирант кафедры математического обеспечения ЭВМ. Научный руководитель – М.К. Буза.
105