Глава 3 ОПРЕДЕЛЕНИЕ ВИДА КАРТИНЫ ЗАМЕН ПРИ СРАВНЕНИИ НУКЛЕОТИДНЫХ И АМИНОКИСЛОТНЫХ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
реклама

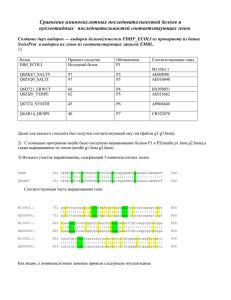
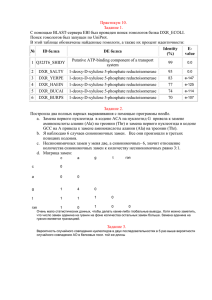
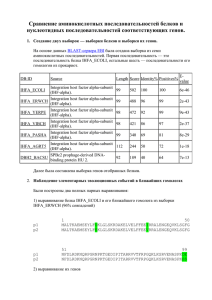
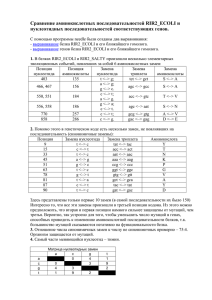
Глава 3 ОПРЕДЕЛЕНИЕ ВИДА КАРТИНЫ ЗАМЕН ПРИ СРАВНЕНИИ НУКЛЕОТИДНЫХ И АМИНОКИСЛОТНЫХ ПОСЛЕДОВАТЕЛЬНОСТЕЙ Общим предположением при проведении сравнительного анализа нуклеотидных и аминокислотных последовательностей является то, что они эволюционировали с неизменной картиной нуклеотидных замен (гипотеза о гомогенности эволюционного процесса). Однако в ряде случаев картина замен в ходе эволюции может изменяться, то есть становиться гетерогенной. Отсутствие учета гетерогенной картины замен препятствует получению корректных филогенетических выводов и проверке эволюционных гипотез. Для оценки вида картины замен в 2001 г. С. Кумар и С. Гадагкар предложили индекс несоответствия (disparity index, ID), который позволяет определить различия картин замен для пар последовательностей. На основе этого индекса ими разработан метод Монте-Карло, предназначенный для проверки гипотезы о гомогенности. Рассмотрим основные параметры, используемые при определении вида картины замен. 3.1. КОМПОЗИЦИОННАЯ ДИСТАНЦИЯ Композиционная дистанция (дистанция состава) – это мера сходства состава сравниваемых нуклеотидных или аминокислотных последовательностей. Рассмотрим методику вычисления композиционной дистанции. Пусть X и Y – это 2 последовательности ДНК длиной L каждая. Пусть xi – это количество нуклеотида типа i (i=A, T, Ц или Г) в последовательности X, а yi – в последовательности Y. Тогда композиционная дистанция между этими двумя последовательностями определяется как: DС = ½ ∑i (хi – yi)2 (3.1) где i =A, T, Ц или Г. Для получения расчетного значения DС представим последовательности X и Y как (а1а2а3…а4) и (b1b2b3…b4). Для данного нуклеотида типа i, расположенного в сайте k, определим: δki = + 1 если аk = i, a bk ≠ i δki = – 1 если аk ≠ i, a bk = i δki = 0 другие варианты (3.2) Используя уравнение 3.2, формулу (3.1) можно записать как: DС = ½ ∑i (∑Lk=1 δki)2 (3.3) Расчетное значение композиционной дистанции определяется как: Е (DС) = ½ Е (∑i (∑Lk=1 δki)2) (3.4) Учитывая независимость сайтов, получаем Е (DС) = ½ Е (∑i ∑k (δki)2) + ½ Е (∑i ∑k∑k΄≠k δki δk΄i) (3.5) Первое слагаемое – это расчетное количество нуклеотидных различий между двумя последовательностями (Nd), которое определяется степенью их дивергенции, картиной эволюционных замен и степенью гетерогенности сайтов. То есть: ½ Е (∑i ∑k (δki)2) = Е (Nd) (3.6) Поскольку суммирование происходит для независимых сайтов, то второе слагаемое в формуле (3.5) можно записать следующим образом: ½ Е (∑i ∑k∑k΄≠k δki δk΄i) = ∑i (Е [∑k δki] Е [∑k΄≠k δk΄i] (3.7) Если основной процесс замен является гомогенным, то для данной пары нуклеотидов (i, j), E (nij)=E (nij), где ni.=∑j≠i nij, n.i=∑j≠i nij, a nij – это число сайтов с нуклеотидом i в последовательности X и нуклеотидом j в последовательности Y. Таким образом, Е (∑k δki) = Е (ni.) – Е (n.i) = 0 (3.8) Е (∑i ∑k∑k΄≠k δki δk΄i) = 0 (3.9) Поэтому, Подставив формулы (3.6) и (3.9) в формулу (3.5), получаем Е (DС) = Е (Nd) (3.10) где Nd – это количество сайтов в последовательностях X и Y с различными нуклеотидами. Формула 3.10 показывает, что расчетное число различий между двумя последовательностями является половиной суммы всех частот различий соответствующих выровненных оснований (или аминокислот) в сравниваемых последовательностях. В 1977 г. А. Корниш-Боуден первым предложил формулу (3.1). Однако доказательство формулы (3.10), представленное в его работе, подразумевало гомогенность эволюционного процесса и независимость значений xi и yi. Понятно, что его второе предположение является неверным, потому что эти значения коррелируют в связи с наличием общего предшественника последовательностей X и Y. Рассмотренное выше доказательство С. Кумара и С. Гадагкар не требует этого предположения и основывается на независимости сложности модели замен нуклеотидов (или аминокислот), примененной к наблюдаемой картине, и степени гетерогенности сайтов. Следует отметить, что этот факт был подтвержден компьютерным моделированием. Однако оказываются полученные достаточно значения большими, композиционных что делает дистанций неудобным их интерпретацию и сравнение между собой. Поэтому эти значения делят на количество сравниваемых нуклеотидных или аминокислотных сайтов, получая композиционную дистанцию в расчете на сайт. 3.2. ФАКТОР PDF Когда две сравниваемые последовательности имеют различные картины замен, то полученная с использованием формулы (3.1) композиционная дистанция будет больше, чем полученная в случае гомогенности. Это связано с тем, что наблюдаемые различия в частоте сходных сравниваемых параметров двух последовательностей (xi–yi) будут больше. Для подтверждения этого было проведено компьютерное моделирование для аминокислотных последовательностей. Вероятность замены одного аминокислотного остатка на другой в нем была принята одинаковой для всех остатков в эволюции последовательности в обеих линиях (гомогенность). В случае гетерогенности принята намного большая вероятность замены на данный остаток в выбранной линии для выявления больших отклонений в картинах замен (фактор девиации картины, pdf) с равными остальными вероятностями замен. Фактор рdf – фактор, показывающий отличие вероятности замены на данную аминокислоту (или нуклеотид) при гетерогенности от ожидаемой в случае гомогенности. Для s возможных состояний (s=4 для нуклеотидов и s=20 для аминокислот) вероятность замены на данную составляет 1/(s–1), если все замены равновероятны. Если pdf равен значению f, то это означает, что вероятность данной замены равна f/(s– 1); f=1 соответствует гомогенному процессу. Рис. 3.1. Зависимость между композиционной дистанцией и pdf-фактором для гомо- и гетерогенной картин замен, полученная С. Кумар и С. Гадагкар. Вероятности любой другой замены равны и определяются как (1–f/[s–1])/(s– 2). Более высокое значение pdf указывает на большую гетерогенность в картинах замен. 3.3. ИНДЕКС НЕСООТВЕТСТВИЯ Очевидно, что значение DС будет выше при гетерогенном эволюционном процессе (рис. 3.1). Наблюдаемое между композиционной дистанцией и значением pdf несоответствие, увеличивающееся с ростом гетерогенности, называется индексом несоответствия (index disparity, ID). Значение ID увеличивается при увеличении количества замен и постоянном pdf, а также при увеличении pdf и постоянном количестве замен. При эмпирическом анализе данных ID для данной пары последовательностей вычисляется по формуле: ID = ½ ∑( xi - yi)2 – Nd (3.11) где xi и yi – это частоты нуклеотида (или аминокислоты) типа i в последовательностях X и Y, соответственно, а значение Nd используется для оценки ожидаемой в случае гомогенности DС. Когда предположение о гомогенности подтверждается, то E (ID)= 0, потому что расчетное значение ½ ∑( xi - yi)2 равно значению Nd (формула 3.10). Сходно с композиционной дистанцией индекс несоответствия удобнее вычислять в расчете на сайт. 2.4. МЕТОД МОНТЕ-КАРЛО ДЛЯ ПРОВЕРКИ ГИПОТЕЗЫ О ГОМОГЕННОСТИ Для проверки гипотезы о гомогенности необходимо вычислить вероятность того, что наблюдаемое значение композиционной дистанции (DCO) больше, чем ожидаемое согласно нулевой гипотезе о гомогенности, то есть ID> 0. Поскольку фактическое распределение DC при гомогенности для данных частот оснований и число различий не известно априорно, для его получения следует использовать метод Монте-Карло. В этом методе первоначально используется случайная последовательность длинной L, ожидаемые частоты принимаются равными средним частотам оснований, вычисленным для данной пары последовательностей. Далее производятся случайные замены в двух образовавшихся последовательностях до тех пор, пока количество различий между ними не станет равным Nd для сравниваемой пары последовательностей. Это необходимо для получения DС согласно гипотезе о гомогенности для наблюдаемых данных, учитывая средние частоты оснований для исходной пары последовательностей. Для произведения замен произвольно выбирается участок одной из двух образовавшихся последовательностей. Затем производится произвольная замена нуклеотида в данном сайте (независимо от его исходного вида) на другой на основе полученных ранее средних наблюдаемых частот. Получившиеся последовательности будут иметь те же частоты оснований, поскольку замены происходят со сходным эволюционным процессом в обеих линиях. Эта схема выбрана потому, что нет никакой априорной информации относительно нулевой картине замен и различий скоростей эволюции среди сайтов или линий. Для двух последовательностей, образованных в данном повторе b вычисляем DC,b. Затем этот процесс повторяется необходимое число раз (обычно 1000) и вычисляется доля повторов, в которых DСО выше, чем DC,b (ID>0). Если эта доля больше 95%, то нулевая гипотеза отклоняется на 5%-ом уровне. 3.5. ВОЗМОЖНОСТИ ID-ТЕСТА Для оценки эффективности метода Монте-Карло в обнаружении различий эволюционных картин было проведено компьютерное моделирование при различных биологических условиях. Ошибка ID-теста на 5%-ом уровне аминокислотных при неравных скоростях последовательностей эволюции составляет линий и для приблизительно 5%. Возможность ошибки > 5%, особенно при использовании модели ДжуксаКантора, обуславливает большую приемлемость 1%-ого уровня значимости. Была проанализирована эффективность ID-теста в отклонении ложной нулевой гипотезы, когда сравниваемые последовательности эволюционировали с разными эволюционными процессами. Статистические возможности ID-теста в отклонении нулевой гипотезы возрастают с числом замен и длинной последовательности. Для последовательности данной длины и числа замен, эффективность значительно увеличивается даже при малых отклонениях между последовательностями в эволюционных картинах (pdf = 2). Этот тест гетерогенности не требует априорного знания картины замен, степени сайтов и эволюционных взаимоотношений между последовательностями. Компьютерное моделирование показало, что ID-тест применим для множества биологических моделей эволюции последовательностей. При применении этого теста для анализа 3789 пар ортологичных генов человека и мыши получено, что наблюдаемые картины замен в нейтральных сайтах не являются гомогенными в 41% генов, что обусловлено изменением ГЦ-содержания. Таким образом, предлагаемый тест может использоваться как диагностическое средство для идентификации генов и линий, изменяющихся с существенно отличающимися эволюционными процессами, что отражается в наблюдаемых картинах замен. Идентификация таких генов и линий является важным начальным шагом при проведении сравнительных геномных и молекулярно-филогенетических исследований для анализа эволюционных процессов, в ходе которых формировались геномы организмов. 3.6. ЭФФЕКТИВНОСТЬ ID-ТЕСТА ПО СРАВНЕНИЮ С РАНЕЕ ПРЕДЛОЖЕННЫМИ ТЕСТАМИ При сходных частотах оснований в последовательностях ранее часто использовался χ2-тест: χ2 = ∑ (f1i – f2i)2 / (f1i + f2i) (3.12) где f1ij и f2i равны количеству основания i в сравниваемых последовательностях. При компьютерном моделировании получено, что χ2 является высоко консервативным, поэтому он является менее эффективным, чем ID-тест. Причина консервативного характера классического χ2-теста заключается в том, что он основан на предположении о независимости сравниваемых показателей. Но это не так, потому что частоты, полученные для гомологичных последовательностей, не являются независимыми из-за общей эволюционной истории. Эта зависимость обуславливает повышение значения знаменателя в формуле χ2-теста, поскольку включает информацию по всем сайтам, включая даже те, в которых не происходили замены. Включение этих инвариантных сайтов в знаменатель сильно снижает значение χ2, в то время как их вклад в числитель автоматически аннулируется. Этот эффект является более жестким для близкородственных последовательностей из-за большей доли идентичных сайтов, что связано с наличием общего предшественника. Проблему сходных оснований в сайте, обусловленную общим происхождением также изучали А. Ржетский и М. Ней, разработавшие строгий статистический тест равенства частот нуклеотидов (или аминокислот) для множества последовательностей. Однако этот тест слишком либерален, что обусловлено нарушением некоторых сделанных в тесте предположений. 3.7. ПРИМЕНЕНИЕ ID-ТЕСТА Определение индекса несоответствия и проведение ID-теста является эффективным способом идентификации пар последовательностей, которые эволюционировали с сильно отличающимися картинами замен. Идентификация генов и видов с нетипичными картинами замен также может быть полезной для объяснения эволюционных механизмов наблюдаемых различий. В молекулярной филогенетике возможность определения таких пар последовательностей с помощью ID-теста полезна для дифференциального выбора метода реконструкции эволюционного дерева, учитывающего или не учитывающего гипотезу о гомогенности. Однако стоит отметить, что большое количество параметров в этих сложных методах может препятствовать получению высоко достоверных результатов. Альтернативно исследователи могут удалять последовательности, которые не удовлетворяют гипотезе о гомогенности, предварительно ID-тест, используя или использовать более простые модели для корректных филогенетических оценок. Помимо этого применение ID-теста будет обеспечивать получение корректных эволюционных дистанций, вычисление на их основании точных скоростей эволюции, а также правильность результатов селекционных тестов. 3.8. СРАВНИТЕЛЬНЫЙ АНАЛИЗ М-ИЗОФЕРМЕНТОВ КРЕАТИНКИНАЗ ХОРДОВЫХ Нами проанализированы нуклеотидные последовательности мРНК и аминокислотные последовательности M-изоферментов креатинкиназ различных хордовых животных: оболочника (Ciona intestinalis, C.i.), ланцетника (Branchiostoma fluoridae, B.f.), рыб (Ictalurus punctatus, I.p.), пресмыкающихся (Zaocys dhumnades, Z.d.), птиц (Gallus gallus, G.g.), грызунов (Rattus norvegicus, R.n., Mus musculus, M.m.), парнокопытных (Bos taurus, B.t.) и приматов (Homo sapiens, H.s.). Выравнивание последовательностей произведено с помощью программ Clustal W DNA и Clustal W Protein. Для указанных последовательностей вычислены композиционные дистанции и индекс несоответствия. Вероятность (Р) отклонения нулевой гипотезы о гомогенной картине замен нуклеотидов на 5%-ном уровне определена методом Монте-Карло при 1000 повторов. Картина замен считалась гомогенной при величине Р больше 0,05, в обратном случае – гетерогенной. В случае гомогенной картины замен эволюционные дистанции (ЭД) рассчитаны методами Джукса-Кантора, Кимура, Тадзима-Ней, Тамура, Тамура-Ней; в случае гетерогенной – методами Тадзима-Ней, Тамура, Тамура-Ней. Скорость эволюционных замен вычислена по формуле: kнукл. = ЭД/2T, где Т – число лет, прошедших после эволюционной дивергенции двух цепей от общей для них предковой цепи: множитель 2 в знаменателе соответствует двум ветвям подразумеваемого филогенетического древа. Композиционные дистанции, полученные для нуклеотидных последовательностей мРНК и аминокислотных последовательностей Мизоферментов креатинкиназ в расчете на сайт, представлены в табл. 3.1. Таблица 3.1 Композиционные дистанции между последовательностями мРНК и аминокислотными последовательностями М-изоферментов креатинкиназ хордовых H.s. H.s. B.t. M.m. R.n. G.g. Z.d. I.p. B.f. C.i. 0,0793 0,0597 0,0775 0,7602 0,3990 0,3206 1,1007 3,1916 B.t. 0,0375 0,0401 0,1176 0,4091 0,2513 0,6105 0,9180 4,2308 M.m. 0,0509 0,0429 0,0223 0,5615 0,1881 0,4554 0,8868 3,8779 R.n. 0,0483 0,0322 0,0054 0,7121 0,1907 0,3948 1,0143 3,5945 G.g. 0,0938 0,0697 0,0912 0,0938 0,3111 1,9902 1,9082 6,9955 Z.d. 0,1769 0,0938 0,1019 0,0912 0,1662 1,1310 1,4439 5,3182 I.p. 0,1340 0,0992 0,1287 0,1233 0,1421 0,1475 0,9688 1,8512 B.f. 0,4611 0,3458 0,3378 0,3378 0,4048 0,1850 0,2976 C.i. 0,2091 0,1582 0,1475 0,1501 0,1903 0,0885 0,1260 0,1743 4,9955 Примечание. Жирным шрифтом выделены композиционные дистанции между нуклеотидными последовательностями. Из приведенных в табл. 3.1 данных видно, что во всех случаях проведенных сравнений значения композиционной дистанции между нуклеотидными последовательностями достоверно выше таковых для аминокислотных последовательностей (р < 0,01). Следовательно, нуклеотидный состав мРНК, кодирующих М- изоферменты креатинкиназ хордовых варьирует значительно больше по сравнению с их аминокислотным составом. Это можно объяснить тем, что на уровне аминокислотных последовательностей проявляются лишь несинонимичные замены, на которые накладываются бóльшие структурнофункциональные ограничения, а на уровне нуклеотидных последовательностей – несинонимичные и синонимичные замены. Значения индекса несоответствия и вероятность отклонения нулевой гипотезы о гомогенной картине замен для изучаемых нуклеотидных и аминокислотных последовательностей представлены в табл. 3.2. Таблица 3.2 Значения индекса несоответствия и вероятности отклонения нулевой гипотезы о гомогенной картине замен для нуклеотидных последовательностей мРНК и аминокислотных последовательностей Мизоферментов креатинкиназ хордовых H.s. H.s. B.t. M.m. R.n. G.g. Z.d. I.p. B.f. C.i. 0,0000 (1,00) 0,0000 (1,00) 0,0000 (1,00) 0,5740 (0,01) 0,2291 (0,07) 0,1257 (0,17) 0,8351 (0,00) 2,8601 (0,00) B.t. 0,0000 (1,00) 0,0000 (1,00) 0,0125 (0,33) 0,2291 (0,07) 0,0971 (0,17) 0,4207 (0,02) 0,6515 (0,01) 3,8904 (0,00) M.m. 0,0161 (0,12) 0,0027 (0,42) 0,0000 (1,00) 0,3922 (0,02) 0,0214 (0,33) 0,2576 (0,07) 0,6248 (0,02) 3,5410 (0,00) R.n. 0,0080 (0,27) 0,0000 (1,00) 0,0000 (1,00) 0,5383 (0,01) 0,0276 (0,32) 0,1970 (0,11) 0,7522 (0,01) 3,2558 (0,00) G.g. 0,0000 (1,00) 0,0000 (1,00) 0,0080 (0,36) 0,0080 (0,36) 0,1373 (0,14) 1,7834 (0,00) 1,6070 (0,00) 6,6462 (0,00) Z.d. 0,0670 (0,06) 0,0000 (1,00) 0,0000 (1,00) 0,0000 (1,00) 0,0402 (0,20) 0,9376 (0,00) 1,1622 (0,00) 4,9777 (0,00) I.p. 0,0054 (0,41) 0,0000 (1,00) 0,0000 (1,00) 0,0000 (1,00) 0,0080 (0,41) 0,0000 (1,00) 0,7094 (0,01) 1,5258 (0,00) B.f. 0,1823 (0,06) 0,0670 (0,23) 0,0563 (0,25) 0,0536 (0,27) 0,1099 (0,15) 0,0000 (1,00) 0,0214 (0,37) C.i. 0,0000 (1,00) 0,0000 (1,00) 0,0000 (1,00) 0,0000 (1,00) 0,0000 (1,00) 0,0000 (1,00) 0,0000 (1,00) 0,0000 (1,00) 4,6542 (0,00) Примечание. Жирным шрифтом выделены значения для нуклеотидных последовательностей. В скобках указана вероятность отклонения нулевой гипотезы о гомогенной картине замен. Ячейки со значениями Р>0,05 выделены серым цветом. Из данных, показанных в табл. 3.2 видно, что значения индекса несоответствия для изучаемых нуклеотидных последовательностей достоверно выше таковых для аминокислотных последовательностей (р < 0,01). Примечательно, что во всех проведенных попарных сравнениях аминокислотных последовательностей М-изоферментов креатинкиназ наблюдается гомогенная картина замен, что, вероятно, связано с жесткими структурно-функциональными ограничениями на замены аминокислот. В то же время для нуклеотидных последовательностей гомогенная картина замен обнаруживается лишь в 15 из 36 проведенных сравнений (41,7±8,2%). Таким образом, определение картины замен для последующего расчета эволюционной дистанции наиболее важно для нуклеотидных последовательностей. Наличие двух картин замен в нуклеотидных последовательностях мРНК, кодирующих М-изоферменты креатинкиназ хордовых, свидетельствует о необходимости дифференцированного подхода при определении эволюционных дистанций между нуклеотидными последовательностями. Поэтому для попарных сравнений, в которых обнаружена гомогенная картина замен, следует определять средние эволюционные дистанции по пяти вышеназванным методам, учитывающим этот вид картины замен. Для попарных сравнений, в которых наблюдается гетерогенная картина замен, следует вычислять средние эволюционные дистанции лишь по тем трем методам, которые содержат модифицированные формулы для учета гетерогенности. Вычисленные таким способом средние эволюционные дистанции отображены в табл. 3.3. Таблица 3.3 Средние эволюционные дистанции и их стандартная ошибка для нуклеотидных последовательностей мРНК, кодирующих Мизоферменты креатинкиназ хордовых H.s. H.s. B.t. M.m. R.n. G.g. Z.d. I.p. B.f. C.i. 0,0901 0,1018 0,1129 0,2152 0,1856 0,2246 0,3310 0,4371 B.t. 0,0004 0,1090 0,1164 0,2105 0,1728 0,2192 0,3343 0,4539 M.m. 0,0004 0,0006 0,0369 0,1917 0,1903 0,2291 0,3261 0,4473 R.n. 0,0004 0,0006 0,0001 0,1977 0,1835 0,2295 0,3258 0,4518 G.g. 0,0006 0,0008 0,0006 0,0005 0,1995 0,2417 0,3910 0,4678 Z.d. 0,0006 0,0005 0,0009 0,0007 0,0005 0,2214 0,3592 0,4540 I.p. 0,0005 0,0005 0,0007 0,0006 0,0007 0,0012 0,3231 0,4268 B.f. 0,0001 0,0006 0,0007 0,0005 0,0006 0,0012 0,0004 C.i. 0,0003 0,0007 0,0005 0,0005 0,0005 0,0009 0,0014 0,0011 0,4595 Примечание. Жирным шрифтом выделены значения эволюционных дистанций Для вычисления средних значений ЭД каждого из организмов необходимо учитывать только эволюционные дистанции, полученные при сравнении последовательности, выделенных из этого организма, с последовательностями, выделенными из филогенетически вышестоящих организмов. При расчете средней ЭД оболочника следует учитывать эволюционные дистанции, полученные при сравнении нуклеотидной последовательности мРНК, кодирующей его М-изофермент креатинкиназы, с последовательностями пресмыкающихся, изучаемого птиц и фермента четырех видов ланцетника, рыб, представителей класса Млекопитающие. Так, средняя ЭД для Ciona intestinalis равна 0,4498±0,0049, для Branchiostoma fluoridae – 0,3415±0,0102, для Ictalurus punctatus – 0,2276±0,0036, для Zaocys dhumnades – 0,1863±0,0049, для Gallus gallus – 0,2038±0,0063, для Rattus norvegicus – 0,1147±0,0025, для Mus musculus – 0,1054±0,0051 и для Bos taurus – 0,0901±0,0004. Интересно сопоставить предполагаемые времена дивергенции (500-600 млн. лет для оболочника, 550 млн. лет для ланцетника, 405 млн. лет для рыбы, 330 млн. лет для пресмыкающихся, 310 млн. лет для птиц, 110 млн. лет для грызунов, 90 млн. лет для парнокопытных) с полученными эволюционными дистанциями (рис. 3.2). 0,5 y = 0,0007x R2 = 0,9118 эволюционная дистанция в расчете на сайт 0,45 C.i. 0,4 0,35 B.f. 0,3 0,25 I.p. G.g. 0,2 Z.d. 0,15 R.n. M.m. 0,1 B.t. 0,05 0 0 100 200 300 400 500 600 700 время, млн. лет Рис. 3.2. Зависимость между значениями эволюционных дистанций и временем дивергенции М-изофермента креатинкиназ хордовых животных. Все точки достаточно хорошо ложатся на тренд, что подтверждает высокая достоверность его аппроксимации (R2=0,91). Наклон тренда равен 0,0065, поэтому kнукл = ЭД/2T = 0,0065/2·100 млн. лет ≈ 0,33 · 10-9 замен на нуклеотидный сайт в год, что свидетельствует о приблизительно постоянной скорости эволюции изучаемых нуклеотидных последовательностей. Следует отметить, что вычисленная нами ранее скорость эволюции аминокислотных последовательностей М-изофермента креатинкиназ хордовых животных (0,18·10-9 замен на аминокислотный сайт в год) почти в два раза меньше таковой для аминокислотных последовательностей, значительной долей синонимичных замен. что связано со