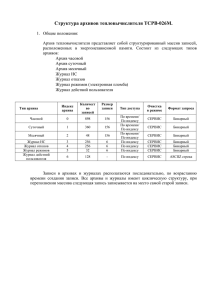
Алфавит C++
реклама

Алфавит C++
Алфавит (или множество литер) языка программирования C++ основывается на множестве символов
таблицы кодов ASCII. Алфавит C++ включает:
строчные и прописные буквы латинского алфавита (мы их будем называть буквами),
цифры от 0 до 9 (назовём их буквами-цифрами),
символ '_' (подчерк - также считается буквой),
набор специальных символов:
"{},|[]+-%/\;':?<>=!&#~^.*
прочие символы.
Алфавит C++ служит для построения слов, которые в C++ называются лексемами. Различают пять
типов лексем:
идентификаторы,
ключевые слова,
знаки (символы) операций,
литералы,
разделители.
Почти все типы лексем (кроме ключевых слов и идентификаторов) имеют собственные правила
словообразования, включая собственные подмножества алфавита.
Лексемы разделяются разделителями. Этой же цели служит множество пробельных символов, к
числу которых относятся пробел, символы горизонтальной и вертикальной табуляции, символ новой
строки, перевода формата и комментарии.
Правила образования идентификаторов
Рассмотрим правила построения идентификаторов из букв алфавита (в C++ три):
1. Первым символом идентификатора C++ может быть только буква.
2. Следующими символами идентификатора могут быть буквы, буквы-цифры и буквыподчерки.
3. Длина идентификатора неограниченна (фактически же длина зависит от реализации системы
программирования).
Вопреки правилам словообразования в C++ существуют ограничения относительно использования
подчерка в качестве самой первой буквы в идентификаторах. Особенности реализации делают
нежелательными для использования идентификаторы, которые начинаются с этого символа.
Ключевые слова и имена
Часть идентификаторов C++ входит в фиксированный словарь ключевых слов. Эти идентификаторы
образуют подмножество ключевых слов (они так и называются ключевыми словами). Прочие
идентификаторы после специального объявления становятся именами. Имена служат для
обозначения переменных, типов данных, функций и меток. Обо всём этом позже.
Ниже приводится список ключевых слов:
asm auto break case catch char class const continue default do double else enum extern float for friend goto
if inline int long new operator private protected public register return short signed sizeof static struct switch
template this throw try typedef typeid union unsigned virtual void volatile while.
Символы операций и разделителей
Множество лексем, соответствующее множеству символов операций и разделителей строится на
основе набора специальных символов и букв(!) алфавита. Единственное правило словообразования
для этих категорий лексем заключается в задании фиксированного множества символов операций и
разделителей.
Следующие последовательности специальных символов и букв алфавита образуют множество
символов операций (часть из них в зависимости от контекста может быть использована в качестве
разделителей):
,
!
!= |
|=
%
%=
&
&& &=
()
*=
+
++
+=
-
--
-= ->
->*
.
.*
/
/=
::
<
<=
<<=
>
>>
>=
>>= == ?:
[]
^
^=
~
||
#
*
<<
## sizeof new delete typeid throw
Кроме того, к числу разделителей относятся следующие последовательности специальных символов:
... ; {}
Литералы
В C++ существует четыре типа литералов:
целочисленный литерал,
вещественный литерал,
символьный литерал,
строковый литерал.
Это особая категория слов языка. Для каждого подмножества литералов испольльзуются
собственные правила словообразования. Мы не будем приводить здесь эти правила. Ограничимся
лишь общим описанием структуры и назначения каждого подмножества литералов. После этого
правила станут более-менее понятны.
Целочисленный литерал служит для записи целочисленных значений и является
соответствующей последовательностью цифр (возможно со знаком '-'). Целочисленный
литерал, начинающийся с 0, воспринимается как восьмеричное целое. В этом случае цифры 8
и 9 не должны встречаться среди составляющих литерал символов. Целочисленный литерал,
начинающийся с 0x или 0X, воспринимается как шестнадцатеричное целое. В этом случае
целочисленный литерал может включать символы от A или a, до F или f, которые в
шестнадцатеричной системе эквивалентны десятичным значениям от 10 до 15.
Непосредственно за литералом может располагаться в произвольном сочетании один или два
специальных суффикса: U (или u) и L (или l).
Вещественный литерал служит для отображения вещественных значений. Он фиксирует
запись соответствующего значения в обычной десятичной или научной нотациях. В научной
нотации мантисса отделяется от порядка литерой E или e). Непосредственно за литералом
могут располагаться один из двух специальных суффиксов: F (или f) и L или l).
Значением символьного литерала является соответствующее значения ASCII кода (это,
разумеется, не только буквы, буквы-цифры или специальные символы алфавита C++).
Символьный литерал представляет собой последовательность из одной или нескольких литер,
заключённых в одинарные кавычки. Символьный литерал служит для представления литер в
одном из форматов представления. Например, литера Z может быть представлена литералом
'Z', а также литералами '\132' и '\x5A'. Любая литера может быть представлена в нескольких
форматах представления: обычном, восьмеричном и шестнадцатеричном. Допустимый
диапазон для обозначения символьных литералов в восьмеричном представлении ограничен
восьмеричными числами от 0 до 377. Допустимый диапазон для обозначения символьных
литералов в шестнадцатеричном представлении ограничен шестнадцатеричными числами от
0x0 до 0xFF. Литеры, которые используются в качестве служебных символов при
организации формата представления или не имеют графического представления, могут быть
представлены с помощью ещё одного специального формата. Ниже приводится список литер,
которые представляются в этом формате. К их числу относятся литеры, не имеющие
графического представления, а также литеры, которые используются при организации
структуры форматов.
Список литер организован по следующему принципу: сначала приводится представление
литеры в специальном формате, затем - эквивалентное представление в шестнадцатеричном
формате, далее - обозначение или название литеры, за которым приводится краткое описание
реакции на литеру (смысл литеры).
\0
\a
\b
\f
\n
\r
\t
\v
\\
\'
\"
\?
\x00
\x07
\x08
\x0C
\x0A
\x0D
\x09
\x0B
\x5C
\x27
\x22
\x3F
null
bel
bs
ff
lf
cr
ht
vt
\
'
"
?
пустая литера
сигнал
возврат на шаг
перевод страницы
перевод строки
возврат каретки
горизонтальная табуляция
вертикальная табуляция
обратная косая черта
Строковые литералы являются последовательностью (возможно, пустой) литер в одном из
возможных форматов представления, заключённых в двойные кавычки. Строковые литералы,
расположенные последовательно, соединяются в один литерал, причём литеры соединённых
строк остаются различными. Так, например, последовательность строковых литералов "\xF"
"F" после объединения будет содержать две литеры, первая из которых является символьным
литералом в шестнадцатеричном формате '\F', второй - символьным литералом 'F'. Строковый
литерал и объединённая последовательность строковых литералов заканчиваются пустой
литерой, которая используется как индикатор конца литерала.
Структура предложения C++
Предложения в C++ называются операторами. Подобно тому, как в естественном языке предложение
строится из различных частей предложения и даже отдельных предложений (сложные предложения),
оператор C++ состоит из выражений и может содержать вложенные операторы. Выражение является
частью оператора и строится на основе множества символов операций, ключевых слов и операндов.
Операндами являются литералы и имена. Одной из характеристик выражения является его значение,
которое вычисляется на основе значений операндов по правилам, задаваемым операндами.
Программный модуль
Программа строится на основе программных модулей. Модуль состоит из элементов программного
модуля. В модуле нет ничего, кроме инструкций препроцессора и (или) списков операторов.
Как сказано в справочном руководстве по C++, файл состоит из последовательности объявлений.
Здесь нет ничего странного: определение является частным случаем объявления (например,
объявление, содержащее инициализацию).
Сложность оператора практически ничем не регламентируется, к ним, в частности, относятся
объявления и определения объектов, объявления (или прототипы) и определения функций.
В свою очередь, функция состоит из заголовка, который включает спецификаторы объявления,
описатели и инициализаторы и тела.
Тело функции представляет собой блок операторов - список операторов (опять!), заключаемый в
фигурные скобки.
Объекты и функции
Объектом называют область памяти, выделяемую для сохранения какой-либо информации. Эта
информация в данной области памяти кодируется двоичной последовательностью. Такие
последовательности составляют множество значений объекта.
Резервирование области памяти предполагает обязательную возможность доступа к ней. Обращение
к объекту обеспечивается выражениями. Выражение в языке программирования является
единственным средством взаимодействия с объектами. Частным случаем выражения является имя
объекта.
Объекты, которые используются исключительно для сохранения информации, называются
константами. Обычно константе присваивается значение в момент создания объекта. Дальнейшие
изменения значения константы не допускаются.
Объекты, которые допускают изменение зафиксированных в них значений, называются
переменными. Инициализация переменной (присваивание ей начального значения) может быть не
связана с оределением этой переменной. Переменная открыта для изменения значений, а потому
присвоение значения может быть произведено в любом месте программы, где только существует
возможность доступа к переменной.
Основными характеристиками объекта являются: тип, класс памяти, область действия связанного с
объектом имени, видимость имени объекта, время жизни, тип компоновки (или тип связывания).
Все атрибуты объектов в программе взаимосвязаны. Они могут быть явным образом
специфицированы в программе, а могут быть заданы по умолчанию в зависимости от контекста, в
котором имя объекта встречается в тексте программы.
Область памяти, выделяемая для сохранения программного кода, называется функцией. Между
объектами и функциями много общего. Обращение к функциям также обеспечивается выражениями.
Эти выражения называются выражениями вызова функций. Значения выражений вызова
вычисляются в результате выполнения соответствующего программного кода. Функция
характеризуется типом, область действия связанного с функцией имени, видимостью имени
функции, типом связывания.
Типы
Тип является основной характеристикой объекта и функции. Тип определяет, что и как следует
делать со значениями объектов и функций. Значение функции выполняется, значение константы
читается, константой переменной модифицируется. Тип определяет структуру и размеры объекта,
диапазон и способы интерпретации его значения, множество допустимых операций.
Поскольку конкретное значение может быть зафиксировано в области памяти, которая соответствует
объекту определённого типа, можно также говорить о типе значения. Значения представляются
выражениями. Поэтому имеет смысл также говорить и о типе выражения. Таким образом, тип
оказывается важнейшей характеристикой языка.
Можно предположить существование языка с единственным типом объекта. Такой язык можно
считать нетипизированным языком. Для нетипизированного языка характерен фиксированный
размер объекта, единый формат хранения данных, унифицированные способы интерпретации
значений.
Как ни странно, нетипизированный язык одинаково неудобен для решения задач в любой
конкретной предметной области. К обработке символьной информации или решению сложных
вычислительных задач транслятор нетипизированного языка относится одинаково. Для него все
объекты одинаковые. Так что реализация алгоритмов сравнения символьных строк, вычисление
значений тригонометрических функций, корректное прочтение и запись значений переменных и
констант, способы интерпретации информации, применение разнообразных операций к данным (при
анализе символьной информации бессмысленны операции умножения и деления) и многие другие
проблемы оказываются исключительно проблемами программиста. Больше проблем - больше
ошибок.
Здесь имеет смысл обратиться к приложениям, связанным с типизацией и контролем типов. В
следующих разделах мы будем говорить о типах объектов. Типы функций будут рассмотрены позже.
Основные типы C++
Основные типы в C++ подразделяются на две группы: целочисленные типы и типы с плавающей
точкой (для краткости их будем называть плавающими типами). Это арифметические типы.
В C++ нет жёсткого стандарта на диапазоны значений арифметических типов (в стандарте языка
оговариваются лишь минимально допустимые значения). В принципе, эти диапазоны определяются
конкретной реализацией. Обычно выбор этих характеристик диктуется эффективностью
использования вычислительных возможностей компьютера. Зависимость языка от реализации
создаёт определённые проблемы переносимости. C++ остаётся машинно-зависимым языком.
К целочисленным типам относятся типы, представленные следующими именами основных типов:
char
short
int
long
Имена целочисленных типов могут использоваться в сочетании с парой модификаторов типа:
signed
unsigned
Эти модификаторы изменяют формат представления данных, но не влияют на размеры выделяемых
областей памяти.
Модификатор типа signed указывает, что переменная может принимать как положительные, так и
отрицательные значения. Возможно, что при этом самый левый бит области памяти, выделяемой для
хранения значения, используется для представления знака. Если этот бит установлен в 0, то значение
переменной считается положительным. Если бит установлен в 1, то значение переменной считается
отрицательным.
Модификатор типа unsigned указывает, что переменная принимает неотрицательные значения. При
этом самый левый бит области памяти, выделяемой для хранения значения, используется так же, как
и все остальные биты области памяти - для представления значения.
В ряде случаев модификаторы типа можно рассматривать как имена основных типов.
Здесь также многое определяется конкретной реализацией. В версиях Borland C++ данные типов,
обозначаемых как signed, short и int в памяти занимают одно и то же количество байтов.
Особое место среди множества основных целочисленных типов занимают перечисления, которые
обозначаются ключевым словом enum. Перечисления представляют собой упорядоченные наборы
целых значений. Они имеют своеобразный синтаксис и достаточно специфическую область
использования. Их изучению будет посвящён специальный раздел.
Здесь также многое зависит от реализации. По крайней мере, для Borland C++ 4.5, основные
характеристики целочисленных типов выглядят следующим образом:
Тип данных
Байты Биты Min
Max
signed char
1
8
- 128
127
unsigned char
1
8
0
255
signed short
2
16
-32768
32767
enum
2
16
-32768
32767
unsigned short 2
16
0
65535
signed int
2
16
-32768
32767
unsigned int
2
16
0
65535
signed long
4
32
-2147483648 2147483647
unsigned long 4
32
0
4294967295
К плавающим типам относятся три типа, представленные следующими именами типов,
модификаторов и их сочетаний:
float
double
long double
Как и ранее, модификатор типа входит в число имён основных типов.
Плавающие типы используются для работы с вещественными числами, которые представляются в
форме записи с десятичной точкой, так и в "научной нотации". Разница между нотациями становится
очевидной из простого примера, который демонстрирует запись одного и того же вещественного
числа в различных нотациях.
297.7
2.977*10**2
2.977E2
и ещё один пример…
0.002355
2.355*10**-3
2.355E-3
В научной нотации слева от символа E записывается мантисса, справа - значение экспоненты,
которая всегда равняется показателю степени 10.
Для хранения значений плавающих типов в памяти используется специальный формат
представления вещественных чисел. Этот формат называется IEEE форматом.
Ниже представлены основные характеристики типов данных с плавающей точкой (опять же для
Borland C++ 4.5):
Тип данных Байты Биты Min
Max
float
4
32
3.4E-38
3.4E+38
double
8
64
1.7E-308
1.7E+308
long double
10
80
3.4E-4932 3.4E+4932
Подведём итог.
Имена типов данных и их сочетания с модификаторами типов используются для представления
данных различных размеров в знаковом и беззнаковом представлении:
char
signed char
unsigned char
short
signed short
unsigned short
signed
unsigned
short int
signed short int
unsigned short int
int
signed int
unsigned int
long
signed long
unsigned long
long int
signed long int
unsigned long int
Все эти типы образуют множество целочисленных типов. К этому множеству также относятся
перечисления.
А вот сочетания имён типов и модификаторов для представления чисел с плавающей точкой:
float
double
long double
Вот и всё об основных типах. Помимо основных типов в C++ существуют специальные языковые
средства, которые позволяют из элементов основных типов создавать новые, так называемые
производные типы.
Комментарии: возможность выразиться неформально
Язык программирования C++, как и любой формальный язык непривычен для восприятия и в силу
этого в ряде случаев может быть тяжёл для понимания. В C++ предусмотрены дополнительные
возможности для облегчения восприятия текстов программ. Для этого используются комментарии.
Комментарии - это любые последовательности символов алфавита C++, заключённые в специальные
символы. Эти символы называются символами - комментариями. Существуют две группы символов
- комментариев. К первой группе относятся парные двухбуквенные символы /* и */.
Ко второй группе символов - комментариев относится пара, состоящая из двухбуквенного символа //
и не имеющего графического представления пробельного символа новой строки.
Последовательность символов, ограниченная символами комментариев, исчезает из поля зрения
транслятора. В этой "мёртвой зоне" программист может подробно описывать особенности
создаваемого алгоритма, а может просто "спрятать" от транслятора целые предложения на C++.
Сейчас мы рассмотрим структуру модуля. На содержательную часть этой "программы" можно не
обращать никакого внимания. Сейчас важен лишь синтаксис.
СписокИнструкцийПрепроцессора
СписокОператоров
Макроопределение
Оператор
Оператор
Оператор
Оператор
#define Идентификатор СтрокаЛексем
ОбъявлениеПеременной
ОбъявлениеФункции
ОпределениеФункции
ОпределениеФункции
#define IdHello "Hello…"
int *pIntVal[5];
/*
Объявлена переменная типа массив указателей размерности 5 на объекты типа int с именем
pIntVal.
*/
СпецификаторОбъявления Описатель;
СпецификаторОбъявления Описатель ТелоФункции
СпецификаторОбъявления Описатель ТелоФункции
#define IdHello "Hello…"
int *pIntVal[5];
int Описатель (СписокОбъявленийПараметров);
float Описатель (СпецификаторОбъявления Имя ) ТелоФункции
unsigned int MyFun2 (int Param1, ...) СоставнойОператор
#define IdHello "Hello…"
int *pIntVal[5];
int MyFun1 (
СпецификаторОбъявления ,
СпецификаторОбъявления АбстрактныйОписатель Инициализатор,
);
float MyFun2 (СпецификаторОбъявления ИмяОписатель)
ТелоФункции
unsigned int MyFun3 (int Param1, ...) {СписокОператоров}
#define IdHello "Hello…"
int *pIntVal[5];
int MyFun1 (float, int *[5] = pIntVal);
/*
Объявление функции. В объявлении второго параметра используется
абстрактный описатель - он описывает нечто абстрактное, а, главное,
безымянное, вида *[5]. Судя по спецификатору объявления int,
расположенному перед описателем, "нечто" подобно массиву указателей
на объекты типа int из пяти элементов (подробнее о массивах после).
И эта безымянная сущность инициализируется с помощью инициализатора.
Сейчас нам важно проследить формальные принципы построения программного
модуля. Прочие детали будут подробно обсуждены ниже.
*/
float MyFun2 (char chParam1)
{
СписокОператоров
}
unsigned int MyFun3 (int Param1, …)
{СписокОператоров}
#define IdHello "Hello…"
int *pIntVal[5];
int MyFun1 (float, int *[5] = pIntVal); // Объявление функции.
// Определены две функции…
float MyFun2 (char chParam1)
{
extern int ExtIntVal;
char *charVal;
}
unsigned int MyFun3 (int Param1, …)
{
const float MMM = 233.25;
int MyLocalVal;
}
этот пример показывает, что в программе нет случайных элементов. Каждый символ, каждый
идентификатор программы играет строго определённую роль, имеет собственное название и место в
программе. И в этом и состоит основная ценность этого примера.
Итак, наш первый программный модуль представляет собой множество инструкций препроцессора и
операторов. Часть операторов играет роль объявлений. С их помощью кодируется необходимая для
транслятора информация о свойствах объектов. Другая часть операторов является определениями и
предполагает в ходе выполнения программы совершение разнообразных действий (например,
создание объектов в различных сегментах памяти).
После трансляции модуля предложения языка преобразуются во множество команд процессора. При
всём различии операторов языка и команд процессора, трансляция правильно написанной
программы обеспечивает точную передачу заложенного в исходный текст программы смысла (или
семантики операторов). Программист может следить за ходом выполнения программы по
операторам программы на C++, не обращая внимания на то, что процессор в это время выполняет
собственные последовательности команд.
С процессом выполнения программы связана своеобразная система понятий. Когда говорят, что в
программе управление передаётся какому-либо оператору, то имеют в виду, что в исполнительном
модуле процессор приступил к выполнению множества команд, соответствующих данному
оператору.
Класс памяти
Класс памяти определяет порядок размещения объекта в памяти. Различают автоматический и
статический классы памяти. C++ располагает четырьмя спецификаторами класса памяти:
auto
register
static
extern
по два для обозначения принадлежности к автоматическому и статическому классам памяти.
В свою очередь, статический класс памяти может быть локальным (внутренним) или глобальным
(внешним).
Следующая таблица иллюстрирует иерархию классов памяти.
Динамический класс памяти
Статический класс памяти
Автоматический Регистровый Локальный
Глобальный
auto
Extern
register
static
Спецификаторы позволяют определить класс памяти определяемого объекта:
Этот спецификатор автоматического класса памяти указывает на то, что объект
располагается в локальной (или автоматически распределяемой) памяти. Он используется в
операторах объявления в теле функций, а также внутри блоков операторов. Объекты, имена
которых объявляются со спецификатором auto, размещаются в локальной памяти
непосредственно перед началом выполнения функции или блока операторов. При выходе из
блока или при возвращении из функции (о механизмах вызова функций и возвращения из них
речь ещё впереди), соответствующая область локальной памяти освобождается и все ранее
размещённые в ней объекты уничтожаются. Таким образом спецификатор влияет на время
жизни объекта (это время локально). Спецификатор auto используется редко, поскольку все
объекты, определяемые непосредственно в теле функции или в блоке операторов и так по
умолчанию располагаются в локальной памяти. Вне блоков и функций этот спецификатор не
используется.
register. Ещё один спецификатор автоматического класса памяти. Применяется к объектам,
по умолчанию располагаемым в локальной памяти. Представляет из себя "ненавязчивую
просьбу" к транслятору (если это возможно) о размещении значений объектов, объявленных
со спецификатором register в одном из доступных регистров, а не в локальной памяти. Если
по какой-либо причине в момент начала выполнения кода в данном блоке операторов
регистры оказываются занятыми, транслятор обеспечивает с этими объектами обращение, как
с объектами класса auto. Очевидно, что в этом случае объект располагается в локальной
области памяти.
static. Спецификатор внутреннего статического класса памяти. Применяется только(!) к
именам объектов и функций. В C++ этот спецификатор имеет два значения. Первое означает,
что определяемый объект располагается по фиксированному адресу. Тем самым
обеспечивается существование объекта с момента его определения до конца выполнения
программы. Второе значение означает локальность. Объявленный со спецификатором static
локален в одном программном модуле (то есть, недоступен из других модулей
многомодульной программы) или в классе (о классах - позже). Может использоваться в
объявлениях вне блоков и функций. Также используется в объявлениях, расположенных в
теле функций и в блоках операторов.
extern. Спецификатор внешнего статического класса памяти. Обеспечивает существование
объекта с момента его определения до конца выполнения программы. Объект, объявленный
со спецификатором extern доступен во всех модулях программы, то есть глобален.
auto.
Выбор класса памяти, помимо явных спецификаторов, зависит от размещения определения или
объявления в тексте программы. Модуль, функция, блок могут включать соответствующие
операторы объявления или определения, причём всякий раз определяемый объект будет размещаться
в строго определённых областях памяти.
Пространство имён
С понятием области действия имени связано понятие пространства имени.
Пространством имени называется область программы, в пределах которой это имя должно быть
уникальным. Различные категории имён имеют различные пространства имён. К их числу относятся:
Пространство имён глобальных объектов. Это пространство образуется множеством
образующих программу программных модулей. Имена глобальных объектов должны быть
уникальны среди множества имён глобальных объектов во всех модулях, образующих
программу.
Пространство имен поименованных операторов (или операторов с меткой) - функция. Имя
оператора должно быть уникально в теле функции, в которой метка была введена в
программу.
Пространство имён структур, классов, объединений и перечислимых типов зависит от
контекста, в котором были объявлены структуры, классы, объединения. Если они были
объявлены в блоке - это пространство будет составлять блок, если они были объявлены в
модуле, таковой областью является программа. C++ помещает эти имена в общее
пространство имён.
Имена элементов структур, классов, объединений и перечислимых данных должны быть
уникальны в пределах определения структуры, класса, объединения и перечислимых данных.
При этом в разных структурах, классах, объединениях и перечислимых данных допустимы
элементы с одинаковыми именами. Пространством имён для элементов структур, классов,
объединений и перечислимых данных элементов являются сами структуры, классы,
объединения и перечисления.
Имена переменных и функций, имена пользовательских типов (типов, определённых
пользователем - о них также немного позже) должны быть уникальны в области определения:
глобальные объекты должны иметь уникальное имя среди всех глобальных объектов и т.д.
По крайней мере в реализациях C++, для процессоров использующих сегментированную модель
памяти, существует определённая связь между пространством имени и расположением
поименованного объекта в конкретном сегменте памяти. В пределах определённого сегмента может
находиться лишь один объект с уникальным именем. В противном случае возникли бы проблемы с
организацией ссылок на располагаемые в сегменте памяти объекты.
Вместе с тем, одни и те же имена могут использоваться при организации ссылок на объекты,
располагаемые в разных сегментах памяти. Например, в теле функции можно обращаться как к
глобальному объекту, так и к одноимённому локальному объекту, определённому в теле функции.
Правда, обращение к одноимённым объектам, расположенным в различных пространствах имён,
ограничено специальными правилами. В связи с необходимостью организации специального
протокола обращения к одноимённым объектам, располагаемым в различных сегментах памяти, в
C++ возникло понятие области видимости.
Тип связывания или тип компоновки
Тип связывания или тип компоновки определяет соответствие имени объекту или функции в
программе, исходный текст которой располагается в нескольких модулях. Различают статическое и
динамическое связывание.
Статическое связывание бывает внешним или внутренним. Оно обеспечивается на стадии
формирования исполнительного модуля, ещё до этапа выполнения программы.
Если объект локализован в одном модуле, то используется внутреннее связывание. Тип компоновки
специальным образом не обозначается, а определяется компилятором по контексту,
местоположению объявлений и использованию спецификаторов класса памяти.
Внешнее связывание выполняется компоновщиком, который на этапе сборки многомодульной
программы устанавливает связь между уникальным объектом и обращениями к объекту из разных
модулей программы.
При динамическом связывании компоновщик не имеют никакого представления о том, какой
конкретно объект будет соответствовать данному обращению. Динамическое связывание
обеспечивается транслятором в результате подстановки специального кода, который выполняется
непосредственно в ходе выполнения программы.