Особенности архитектуры вычислительных систем c общей
реклама

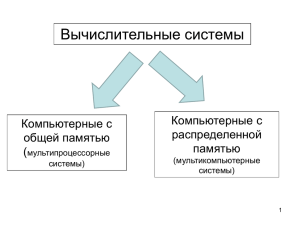
Курс «Архитектура Вычислительных Систем», Университет «Дубна» Лекция 3. Особенности архитектуры вычислительных систем c общей памятью. Две задачи параллельных вычислений. Особенности smp-компьютеров. Иерархия памяти Архитектура NUMA и ccNUMA Компьютер BBN Butterfly Компьютер Hewlett-Packard Superdome Параллелизм на уровне машинных команд Закон Амдала К компьютерам с общей памятью относятся все системы класса Symmetric multi-processor (SMP). В таких системах несколько идентичных (симметричных) процессоров имеют общую память, общую систему ввода-вывода, одну операционная система и др. Shared memory processors аббревиатуры SMP. – альтернативная расшифровка Два принципиально разных класса компьютеров – с общей и c распределенной памятью – отражают две основные задачи параллельных вычислений. (1) Построение вычислительных систем с максимальной производительностью. Это легко на основе концепции распределенной памяти. Уже сейчас установки с тысячами вычислительных узлов, Интернет тоже можно рассматривать как супер- (или даже мета-) компьютер с распределенной памятью, объединяющий миллионы серверов. Но как такие системы эффективно использовать? Как убрать большие накладные расходы на взаимодействие процессоров? Отсюда (2) Поиск методов разработки эффективного программного обеспечения для параллельных систем. Данная задача намного проще решается для компьютеров с общей памятью. Накладные расходы на обмен данными между процессорами через общую память минимальны. Технологии программирования относительно просты, поскольку есть единое адресное пространство. Проблема в том, что по техническим причинам не удается объединить большое число процессоров с единой 1 оперативной памятью. Поэтому очень большую производительность на таких системах получить нельзя. На общее время выполнения задачи влияет много факторов, но главные: (1) время выполнения арифметических операций и (2) время взаимодействия с памятью. Поэтому организация памяти играет важную роль. Главное требование к памяти – обеспечение быстрого доступа к отдельным словам. Иерархия памяти - неотъемлемая часть архитектуры всех современных ЭВМ. Прямого отношения к параллелизму не имеет, однако, безусловно, относится к тем особенностям архитектуры компьютеров, которые имеют огромное значение для повышения их производительности (сглаживание разницы между скоростью работы процессора и временем выборки из памяти). Основные уровни памяти: регистры, кэш-память, оперативная память, дисковая память. Время выборки по уровням памяти от дисковой памяти к регистрам уменьшается, стоимость в пересчете на 1 слово (байт) растет. Как бы ни была устроена память в компьютере – каждый бит информации моделируется простейшим техническим элементом, принимающим два состояния, 0 или 1. Плотность расположения таких элементов исключительно высока. Однако память нельзя сделать сколь угодно большой. Быстрая память – время доступа существенно меньше времени выполнения операций. Медленная – вся остальная. Адресуемая память – большая часть памяти, можно считывать и записывать информацию – это оперативная память (ОП). Неадресуемая – недоступна пользователям. Постоянная и сверхбыстрая. Из постоянной можно только многократно считывать – нужна для хранения команд запуска компьютера, служебных программ и т.д. Сверхбыстрая – существенно меньшее время доступа по сравнению с оперативной. Она тоже часто имеет два уровня. Самый быстрый – регистры. Небольшой объем (единицы или десятки слов). Неотъемлемая часть АЛУ. Хранятся результаты выполнения 2 операций, которые нужны для реализации команд, непосредственно следующих за исполняемыми. Кэш-память – почти такая же быстрая. Играет роль буфера между регистровой памятью и ОП. До миллиона слов. Хранятся результаты, которые могу вскоре потребоваться. Устройство управления (УУ) управляет сверхбыстрой памятью. ОЗУ (оперативное запоминающее устройство) управляет ОП. При компиляции программ, на стадии перевода в машинный код, продвинутый компилятор стремится выстроить команды таким образом, чтобы эффект от сверхбыстрой памяти был максимальным (оптимизация). Но это далеко не всегда удается и\или удается. Зависит от особенностей технической реализации иерархии памяти на конкретных ЭВМ. Понятие локальности вычислений и локальности обработки данных – следующий объект вычислений (команда или операнд) расположен «недалеко» от предыдущего. Это позволяет в полной мере использовать возможности расслоения памяти. Идеальный пример – цикл из 1 операции с большим числом итераций. Тело цикла помещают в быструю память, поскольку на следующей итерации выполняются те же команды. Контрпримеры – неудачная работа с многомерными массивами, косвенная адресация, условные операторы. Попытка объединения достоинств компьютеров с общей и распределенной памятью реализована в архитектурах организации памяти – технологиях NUMA и ccNUMA, Non uniform memory access. Идея в том, чтобы создать механизм, позволяющий всю совокупную (вообще говоря, неоднородную) физическую память компьютера рассматривать (виртуально) как единую адресуемую память. Система Cm* (конец 70х годов) – первый NUMA компьютер. Состоит из набора кластеров, соединенных между собой через межкластерную шину. Каждый кластер объединяет процессор, контроллер памяти, модуль памяти, плюс вспомогательные устройства, соединенные между собой посредством локальной шины. Когда процессору нужно выполнить операции чтения или записи, он посылает запрос с адресом своему контроллеру памяти. Контроллер анализирует старшие разряды адреса и определяет, в каком модуле хранятся нужные данные. Если адрес локальный – запрос выставляется на локальную шину, в противном случае запрос для удаленного 3 кластера отправляется через межкластерную шину. В таком режиме программа, хранящаяся в одном модуле памяти, может выполняться любым процессором системы. Различие заключается лишь в скорости выполнения. Все локальные ссылки отрабатываются намного быстрее, чем удаленные. Поэтому процессор того кластера, где хранится программа, выполнит ее на порядок быстрее, чем любой другой. BBN Butterfly – другой пример NUMA компьютера. В максимальной конфигурации объединял 256 процессоров. Каждый вычислительный узел (ВУ) содержит процессор, локальную память и контроллер памяти, который определяет – является ли запрос к памяти локальным или его необходимо передать удаленному узлу через коммутатор. С точки зрения программиста память является единой общей памятью, удаленные ссылки которой реализуются немного дольше локальных (6 мкс против 2 мкс, т.е. в три раза медленнее). Кэш-память, которая помогает значительно ускорить работу отдельных процессоров – для многопроцессорных систем оказывается узким местом, поскольку возникает проблема согласования содержимого кэшпамяти. На первых NUMA компьютерах кэш-памяти не было, поэтому не было и проблемы. Но для современных микропроцессоров кэш-память является неотъемлемой составной частью. Для решения этой проблемы разработана специальная модификация NUMA архитектуры – ссNUMA (cashe coherent), которая обеспечивает согласованность содержимого всех кэшей. На основе архитектуры ссNUMA в настоящее время выпускается множество реальных многопроцессорных систем, расширяющих возможности традиционных компьютеров с общей памятью. Если smpкомпьютеры как правило содержат 16-32-64 процессора, то при использовании ссNUMA – до 256 процессоров. Разрыв во времени доступа к локальной и удаленной памяти – 200-700%. Компьютеры серии НР Superdome появились в 2000г и в 2001г заняли 147 позиций в списке Топ-500. В стандартной комплектации может объединять от 2 до 64 процессоров с возможностью последующего расширения системы. Все процессоры 4 имеют доступ к общей памяти, организованной в соответствии с архитектурой ccNUMA (cashе coherent NonUniform Memory Access). Память всего компьютера неоднородна (делится на удаленную и локальную) и физически распределена, хотя логически она остается общей (единое адресное пространство). Это удобно для программирования и позволяет увеличить число процессоров. (1) все процессоры могут работать в едином адресном пространстве, адресуя любой байт памяти посредством стандартных операторов чтения-записи. (2) Доступ к локальной памяти идет немного быстрее, чем доступ к удаленной памяти. (3) Содержимое кэш-памяти отдельных процессоров на уровне аппаратуры согласуется с содержимым ОП (кэш память процессора – буфер между регистрами и ОП). В максимальной конфигурации НР Superdome может содержать до 256 Гбайт ОП (планы до 1 Тбайта). Процессоры могут быть РА-8600, РА 8700 (750 Мгц), IA-64. Основу архитектуры составляют вычислительные ячейки (cells) – базовый четырех-процессорный блок компьютера, - каждая из которых есть симметричный мультипроцессор, реализованный на одной плате - до 4х процессоров, - ОП до 16 Гбайт, - контроллер ячейки, - преобразователи питания, - связь с подсистемой ввода-вывода. Контроллер ячейки занимает центральное место в архитектуре ячейки. Он выполняет интерфейсные функции между процессорами, памятью и внешними устройствами, а также отвечает за когерентность кэш-памяти процессоров. Это сложное устройство, состоящее из 24 млн транзисторов. Для каждого процессора ячейки в контроллере есть собственный порт. Обмен данными между контроллером и процессором идет со скоростью 2 Гбайт\сек. Память ячейки составляет от 2 до 16 Гбайт и конструктивно разделена на 2 банка, каждый из которых имеет свой порт в контроллере ячейки. 5 Скорость обмена данными между контроллером и каждым банком составляет 2 Гбайт\с. То есть суммарная пропускная способность тракта контроллер-память составляет 4Гбайт\с. Один порт котроллера связан с внешним коммутатором и предназначен для обмена данными процессоров ячейки с другими процессорами. Скорость работы 8 Гбайт\с. Структура базовой 64-процессорной конфигурации - две стойки по 32 процессора (8 ячеек) - каждая стойка имеет по два 8-портовых неблокирующих коммутатора. Все порты работают со скоростью 8 Гбайт\сек. К каждому коммутатору подключены 4 ячейки. Три порта предназначены для связи с остальными коммутаторами, 4й зарезервирован для связи с другими системами (потенциальная возможность формирования многоузловой конфигурации). - Минимальная задержка – процессор и память в одной ячейке. - Максимальная задержка больше минимальной в 1.6 раза - процессор и память в разных ячейках с разными коммутатороми. - Промежуточный вариант - разные ячейки, но одни коммутатор. Программно-аппаратная среда компьютера позволяет его настроить как классический SMP либо как совокупность независимых разделов, работающих под различными ОС. Пиковая производительность 192Гфлопс (1.92е+9 оп\с). 64-процессорной конфигурации – Структура процессора РА-8700. Тактовая частота 750 МГц. Работая с максимальной загрузкой, может выполнять 4 арифметические операции за такт. То есть пиковая производительность 3 Гфлопс. РА-8700 имеет суперскалярную архитектуру. выполняет столько операций, сколько На каждом такте (1) позволяет информационная структура кода и (2) сколько в данный момент есть свободных фунциональных устройств. 6 Каждый процессор имеет по 10 ФУ - 4 для целочисленной арифметики и логических операций, 4 для работы с вещественной арифметикой и 2 для операций чтения-записи. На каждом такте устройство выборки команд может считывать 4 команды из кэш-памяти. Объем кэш-памяти равен 2.25 Мбайт (1.5Мбайт – кэш данных, 0.75 – кэш команд). Обмен с кэш-памятью идет по 4 каналам (множественно-ассоциативная кэш-память). 64-процессорный компьютер этой серии установлен межведомственном супер-компьютерном центре РАН, 141.е+12 оп\с. в 72-процессорная конфигурация работает в сбербанке России Спецпроцессоры, суперскалярные и VLIW – процессоры. Каждая составляющая программно-аппаратной среды вносит свой вклад в работу программы. Всегда дилемма: реализовывать ту или иную операцию на уровне аппаратуры или возложить ее на программное обеспечение (например, синхронизация). Аппаратная поддержка может дать значительный выигрыш во времени для определенного набора операций, однако при этом другие операций не будут выполняться эффективно. Всего в архитектуре предусмотреть невозможно, поэтому приходится искать компромисс между универсальностью и специализированностью. Спецпроцессоры разрабатываются для определенного, узкого круга задач. Например – обработка сигналов, распознавание речи или графических изображений. Идея состоит в эффективном использовании особенностей конкретных алгоритмов. Спецпроцессоры объединяют множество (до сотен тысяч) параллельно работающих элементарных функциональных устройств. Нет гибкости и универсальности – зато очень высокая производительность для конкретного, узкого круга задач. Примеры (1) японские компьютеры для задач КМД, специальный язык. (2) аппаратная поддержка быстрого преобразования Фурье. Параллелизм на уровне машинных команд Instruction Level Parallelism – скрытый от пользователя параллелизм, нет необходимости в 7 специальном параллельном программировании, нет переносимостью кода с одного компьютера на другой. проблем с Два подхода для использования ILW. 1. Суперкалярные процессоры. Предполагается что программа не содержит никакой информации о возможности ее рапараллеливания. Задача обнаружения параллелизма возлагается на аппаратуру, которая и строит соответствующую последовательность команд. 2. Very Large Instruction World (VLIW). команда, выдаваемая компьютеру на каждом такте, содержит сразу несколько операций, которые выполнятся параллельно. Команда состоит из набора полей, каждое из которых отвечает за свою операцию – работа с памятью, активизация ФУ, операции с регистрами. Если какая-то часть процессора на данном этапе не задействована – то соответствующее поле команды не заполняется. Компиллятор программы выявляет параллелизм и сообщает аппаратуре, какие операции не зависят друг от друга. Формируется точный план того – как процессор будет выполнять программу – последовательность выполнения операций, подключение ФУ, какие операнды в каких регистрах и т.д. Таким образом – суперскалярные процессоры – основные функции по организации распараллеливания лежат на аппаратуре, VLIWпроцессоры – основная нагрузка перекладывается на компиллятор. Закон Амдала и следствия 1й закон Амдала производительность вычислительной системы, состоящей из связанных между собой устройств, в общем случае определяется самым непроизводительным ее устройством. Предположим, что в вашей программе доля операций, которые нужно выполнять последовательно, равна f, где 0<=f<=1 (при этом доля понимается не по статическому числу строк кода, а по числу операций в процессе выполнения). Крайние случаи в значениях f соответствуют полностью параллельным (f=0) и полностью последовательным (f=1) программам. 8 Так вот, для того, чтобы оценить, какое ускорение S может быть получено на компьютере из 's' процессоров при данном значении f, можно воспользоваться 2-м законом Амдала: S<=1/[f+(1-f)/s] или s<=s/(f*s+(1-f)) Пример. Если 9/10 программы исполняется параллельно, а 1/10 попрежнему последовательно, то ускорения более, чем в 10 раз получить в принципе невозможно вне зависимости от качества реализации параллельной части кода и числа используемых процессоров (ясно, что 10 получается только в том случае, когда время исполнения параллельной части равно 0). Следствие (или 3-й закон Амдала) Пусть система состоит из простых одинаковых универсальных устройств (связных) При любом режиме работы ее ускорение не может превзойти обратной величины от доли последовательных вычислений R<1/f Или – для того, чтобы ускорить работу на такой системе в С раз, необходимо ускорить не менее чем в С раз не менее чем (1-1\С)-ю часть программы. Пример. То есть если хотим ускорить в 100 раз, должны ускорить в 100 раз не менее чем 99.99% кода!!! Отсюда вывод - прежде, чем основательно переделывать код для перехода на параллельный компьютер (а любой суперкомпьютер, в частности, является таковым) надо основательно подумать. Если, оценив заложенный в программе алгоритм, вы поняли, что доля последовательных операций велика, то на значительное ускорение рассчитывать явно не приходится и нужно думать о замене отдельных компонент алгоритма. 9